ting

欢迎您反馈PaddleHub使用问题,非常感谢您对PaddleHub的贡献! 在留下您的问题时,辛苦您同步提供如下信息: - 版本、环境信息 1)PaddleHub和PaddlePaddle版本:请提供您的PaddleHub和PaddlePaddle版本号,例如PaddleHub1.4.1,PaddlePaddle1.6.2 2)系统环境:请您描述系统类型,例如Linux/Windows/MacOS/,python版本 - 复现信息:如为报错,请给出复现环境、复现步骤
[UIE Slim Issue]UIE Slim 数据蒸馏中:预测无监督数据的标签以及学生模型训练中样本处理方式选择是否可以多样化? 因为是:基于数据蒸馏技术构建了UIE Slim数据蒸馏系统的技术 首先 Step 2: 用户提供大规模无标注数据,需与标注数据同源。使用Taskflow UIE对无监督数据进行预测。 step2中:数据同源是指同类型数据嘛,只是未标注即可? Step 3: 使用标注数据以及步骤2得到的合成数据训练出封闭域Student Model。 Step 3中:通过训练好的UIE定制模型预测无监督数据的标签得到标签数据’;再学生模型训练。 这能能否提供多场景, 1.当标注样本少的时候,维持原样 2.当标注样本比较多的时候,能否提供脚本把数据doccano处理过的数据直接转化为student model需要的数据类型,我发现doccano脚本处理的和student_model需要的貌似有点不一样。 当然这里直接使用全标注数据 和使用少量标注和合成数据,应该前者准确率是否会高点,以及对student模型会有影响吗?
[UIE Issue] 用UIE做二分类问题,遇到预测结果除了0,1之外还有01以及为空的情况?吃惊! result: {'fk[1,0]': [{'text': '1,0', 'probability': 0.2707405044412532}]} result: {'fk[1,0]': [{'text': '1,0', 'probability': 0.28205075657191614}]} 而且还有结果会是空:{} 查看文档发现是有一个超参数: position_prob=0.52 position_prob:模型对于span的起始位置/终止位置的结果概率在0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5,span的最终概率输出为起始位置概率和终止位置概率的乘积。 但是这个值设置过高的话会导致输出为空。 感觉在二分类问题是,应该不是0 就是1 呀。而且那个'probability': 0.2707405非常低呀。应该是 0才对,有点不解! 关于position_prob在分类问题的影响,
记得很早之前看过一个关于UIE关系抽取后执行evaluate.py文件发现,对性能评估的问题。 以这篇项目为例: Paddlenlp之UIE关系抽取模型【高管关系抽取为例】 https://aistudio.baidu.com/aistudio/projectdetail/4371345?contributionType=1 项目中结果验证时: Class Name: 人名 [2022-07-25 00:17:26,608] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2022-07-25 00:17:26,641] [ INFO] - ----------------------------- [2022-07-25 00:17:26,641]...
### 软件环境 ```Markdown - paddlepaddle: - paddlepaddle-gpu: 2.3.2.post112 - paddlenlp: 2.4.0 ``` ### 重复问题 - [X] I have searched the existing issues ### 错误描述 ```Markdown [2022-09-23 15:57:58,851] [ INFO] -...
### 请提出你的问题 问题背景: 2021-11-29 :百度ERNIE-Health登顶中文医疗信息处理CBLUE榜单冠军:https://baijiahao.baidu.com/s?id=1717731573139745403&wfr=spider&for=pc 2022-04-13 :云知声登顶中文医疗信息处理挑战榜CBLUE 2.0:https://baijiahao.baidu.com/s?id=1729960390071520105&wfr=spider&for=pc 2022-05月份: 艾登&清华团队在中文医疗信息处理挑战榜喜创佳绩:https://www.cn-healthcare.com/articlewm/20220606/content-1372998.html 1.可以看到在CBLUE榜单上,ERNIE最先刷榜登顶,后续有一些别的团队再更新刷榜。通过模型对比,我相信ERNIE一定是NLP领域前沿模型,效果性能都很优越。而后续新榜单模型,在算法模型的优化侧重点可能没那么大,感觉更多的会对数据集的处理上下了很大功夫。模型差不多情况下,不同数据增强等技术影响还是比较大的,然后不断迭代。 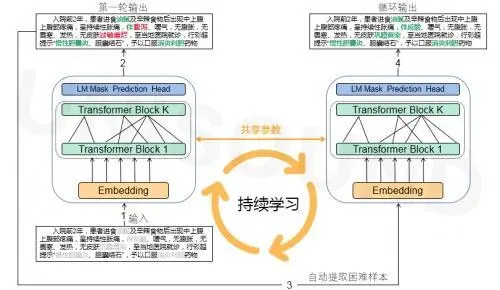 2.看到paddlenlp已经推出了:pipelines面向 NLP 全场景为用户提供低门槛构建强大产品级系统的能力,通过一种简单高效的方式搭建一套语义检索系统,使用自然语言文本通过语义进行智能文档查询。 因此引出了一个问题:关于持续学习 目前看到在paddlenlp 提供了一些数据优化的方法:如:AITrust等可信分析,以及BML平台上看到的智能标注(或者个人依赖ERNIE生成的教师模型),来提供相对较高质量的标注数据。 但感觉在模型迭代过程中更多的是点状,是靠人工进行一个个串行起来。 希望可以出现一个持续学习模型的流程(自动化)和这些技术结合起来,还是有很大意义的。
## 软件环境 ```Markdown - GPU - paddlepaddle: - paddlepaddle-gpu: 2.5.2 - paddlenlp: 2.6.0rc0 - CPU - paddlepaddle: - paddlepaddle-cpu: 2.5.2 - paddlenlp:2.6.0rc0 ``` ## 重复问题 - [X] I have searched...
请问在官网看到的的ERNIE-Search:围绕检索场景的多种任务,有开源地址嘛 https://wenxin.baidu.com/wenxin/modelbasedetail/ernie_search 模型概述 为了提升 ERNIE 在检索领域的效果,ERNIE-Search 提出了使用预训练阶段细粒度交互向粗粒度交互蒸馏的策略。通过在训练过程中进行自蒸馏,在节省了传统方法中训练教师模型的开销之外,提高了 ERNIE-Search 的模型效果。
### 软件环境 * fastploy版本 1.0.7最新版 * GPU版本 - paddlepaddle:2.4.2 - paddlepaddle-gpu: 11.2 - paddlenlp: 2.5.2 - cuda 11.2 - cudnn 8.1.1 **除使用`fastploy`外,所有程序均正常** [cudnn下载官网](https://developer.nvidia.com/rdp/cudnn-archive)  ``` fastploy官方环境要求: CUDA >= 11.2 cuDNN...
erniesage paddle2.0版本的看NLP下只提供了V2版本的 请问V1 3 4的有嘛 https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/text_graph/erniesage 对这个比较感兴趣,看到了1.8版本的v1 v2 v3 的实现,官网目前给到了高阶邻居的图示