Muhammad Salman Edhi
![]()
![]()
Muhammad Salman Edhi
Hi, thank you for your prompt response. This worked. I have one more suggestion. For file etc/extract_vocab.py Please add 'encoding="utf8"' when reading and writing files as the code crashes otherwise.
Hi, i am getting a similar issue. Can you please tell your version of PyTorch and CUDA used? @JasonObeid Or is this any other issue? I am running the project...
Hi, this was fixed by setting the embedding size to 1200 from 800 in model/src/model/transformer.py
@JasonObeid The detailed log. I am badly stuck . Any help would be really appreciated . 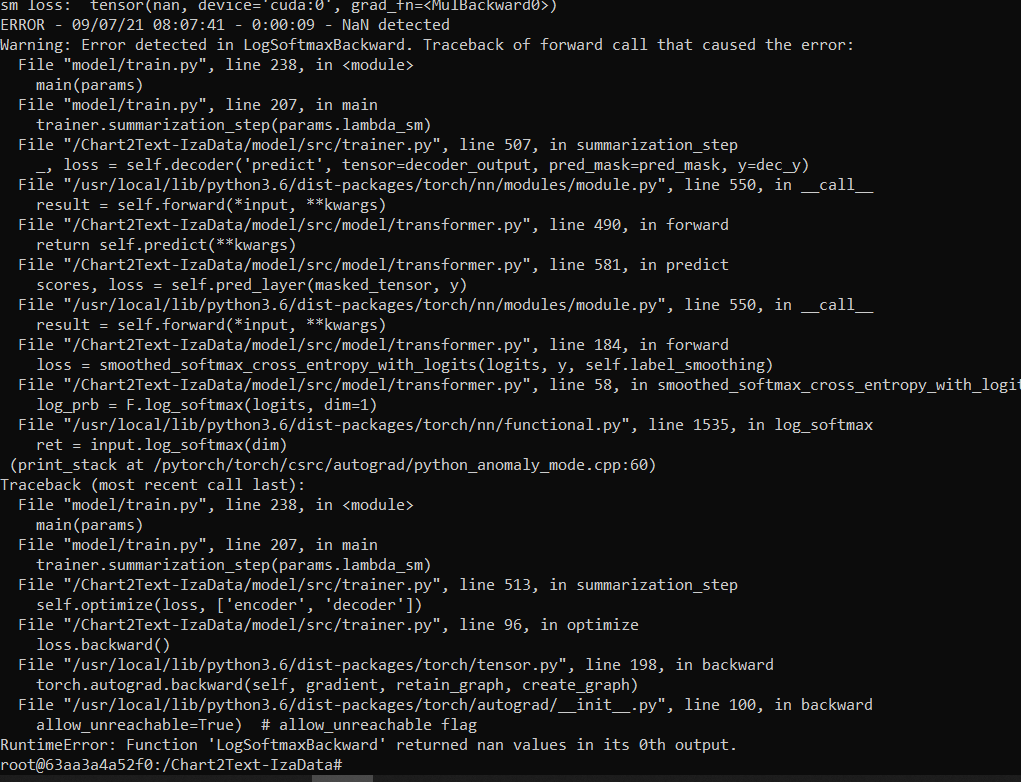
Hi @JasonObeid , i thought so too in the beginning that it might be a data issue, but sadly it is not. Since it is working fine on CPU but...