LR NaN while training on new dataset
Hi @JasonObeid , i have my own dataset and when i am training on gpu it gives NaN error, while it works on CPU.
This is the output on CPU: INFO - 09/02/21 19:59:16 - 0:14:06 - 810 - 8.31 sent/s - 233.60 words/s - cs: 0.5929 (coef=1.0000) || sm: 3.9967 (coef=1.0000) - Transformer LR = 1.0000e-04
Can you please suggest what I could do?
@JasonObeid The detailed log. I am badly stuck . Any help would be really appreciated .
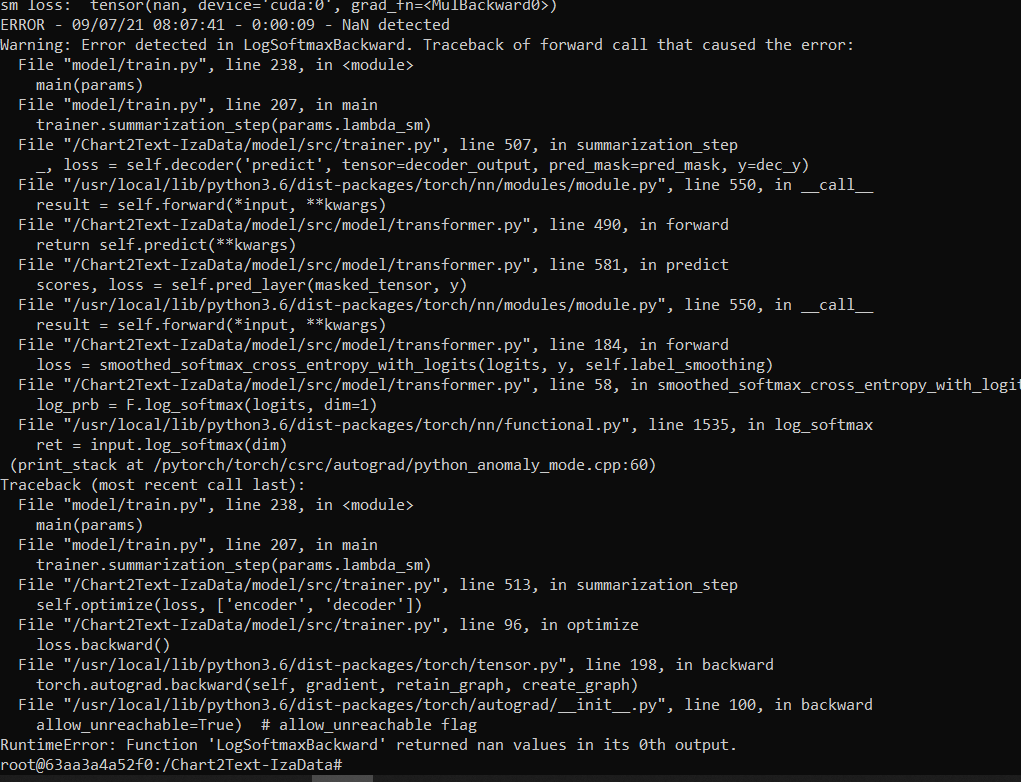
Hi @salmanedhi, unfortunately I have no idea how to fix this issue. You could run the training with a python debugger, and try to see why the error is occurring.
Since it is a NaN error and you mentioned it's a new dataset, could there maybe be some missing or corrupt data somewhere?
Hi @JasonObeid , i thought so too in the beginning that it might be a data issue, but sadly it is not. Since it is working fine on CPU but gives the same error again and again on GPU. I tried a lot to debug where exactly is the issue coming from and I am able to pinpoint that the NaN values come from the forward step of MultiHeadAttention. The weird part however, is that the NaN error comes at random places in the forward step. Sometimes, it comes on the weights, sometimes after the linear transformation of data.
Along with that it happens randomly on any iteration. sometimes it happens on the first iteration. Sometimes after the 1st epoch even.
Any further suggestions would be appreciated . Thank you
Hi @salmanedhi, if training by CPU is working, then maybe it's related to the version of pytorch or cuda?
I believe I used PyTorch 1.5.0 and cuda 10.2 for training, see https://pytorch.org/get-started/previous-versions/ for installation instructions.
Other than that I don't know what else could fix it. Best of luck! :)