Ensheng Shi (石恩升)
Ensheng Shi (石恩升)

I download tensorflow from https://polybox.ethz.ch/index.php/s/ojd0RPFOtUTPPRr and put tensorflow/ir_0 in data/. When i run `python train_inst2vec.py`, there is a error : "Expected combineable dataset" I know the except is from https://github.com/spcl/ncc/blob/master/inst2vec/inst2vec_embedding.py#L56....
run ```python server.py --share --listen --chat --model llama-7b```. Everything is okay.  However, when run ```` python server.py --share --listen --chat --model llama-13b ```, It would report an error: ```...
It takes too much time to load the model . For example, setting batch size =1, It will take about 252.89 and 880s to load llama-13b and llama-30b, respectively. Are...
refer to https://github.com/randaller/llama-chat/issues/7
code `python generate.py ` error ``` ===================================BUG REPORT=================================== Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues ================================================================================ /home/t-enshengshi/anaconda3/envs/alpaca-lora/lib/python3.9/site-packages/bitsandbytes/cuda_setup/main.py:136: UserWarning: /home/t-enshengshi/anaconda3/envs/alpaca-lora did not contain libcudart.so as...
I run the program on 4*V100. When setting group_by_lenth=True, the training loss often decreases and coverages. 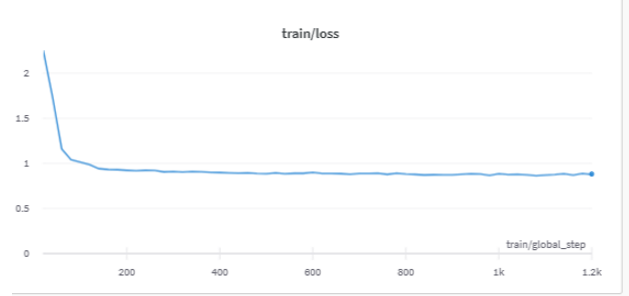 When setting group_by_lenth=False, the training loss often becomes suddenly bigger and then it...
Why add the following code snippet in this [commit](https://github.com/tloen/alpaca-lora/commit/5fa807d106fdce88bd9635eac9fee1a7be9465ae#diff-a5ff12394959301eb25d323d44fc987a79336e66a44eb3e4def7ae3515f35430) since it would bring some errors? https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L256-L261 ``` old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict()...
What is the maximum token limit of llama? Is it 1024, 2048, 4096, or longer? for example, GPT-4 has a maximum token limit of 32,000 (equivalent to 25,000 words)
I find about code about /ProgramDependenceGraph https://github.com/soot-oss/soot/blob/4a04145d1a4d2713ef2733e33abd5ba77b2fd848/src/main/java/soot/toolkits/graph/pdg/ProgramDependenceGraph.java , however I don't know how to get PDG in command line using soot