zhuww
![]()
zhuww
I also encountered the same problem.
> > @epolewski I solve this problam, edit vllm\engine\ray_utils.py change ray.init(address=ray_address, ignore_reinit_error=True) as ray.shutdown() ray.init(num_gpus=2, address=ray_address, ignore_reinit_error=True) > > num_gpus=2 because I have 2 gpu. --max-model-len set as 2048, then...
> Implement LlaMa as requested in issue #506 . > > ## Steps to use > first convert llama-7b-hf weights from huggingface with `huggingface_llama_convert.py`: `python3 huggingface_llama_convert.py -saved_dir=/path/to/export/folder/ -in_file=/path/to/llama-7b-hf -infer_gpu_num=1 -weight_data_type=fp16...
> > Implement LlaMa as requested in issue #506 . > > ## Steps to use > > first convert llama-7b-hf weights from huggingface with `huggingface_llama_convert.py`: `python3 huggingface_llama_convert.py -saved_dir=/path/to/export/folder/ -in_file=/path/to/llama-7b-hf...
> ### Branch/Tag/Commit > main > > ### Docker Image Version > nvcr.io/nvidia/pytorch:23.02-py3 > > ### GPU name > H100 MIG > > ### CUDA Driver > 525.85.12 > >...
> Hi @byshiue , I run into the same issue as mentioned by feihugis. Here I use the example where the batch_size=1. Any update on this issue? 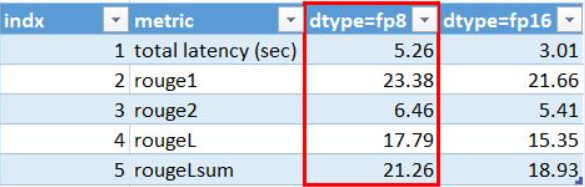 @wohenniubi May...
Thank you for your answer. I found the rosetta/main/source/external/DalpahBall/ directory and compiled it to generate DAlphaBall.gcc.
When I run ./get_interface_metrics.py output/run2/trf_relax/, The error is as follows: `ERROR: Failed to run the psipred command, which was "/opt/RFDesign/scripts/psipred/runpsipred_single DCQRKVQEAK_8MMGOTHT.fasta > /dev/null". Something went wrong. Make sure you specified...
I also encountered this problem, , I manually modified the free_gpu_memory and total_gpu_memory.
Fused GEMM/all-reduce leveraging Flux and AsyncTP Looking forward to this optimization and hoping to use it as soon as possible. Has it been implemented yet?