GPT2 + FP8 example does not work
Branch/Tag/Commit
main
Docker Image Version
nvcr.io/nvidia/pytorch:23.02-py3
GPU name
H100 MIG
CUDA Driver
525.85.12
Reproduced Steps
1. `docker run --privileged --gpus '"device=MIG-***"' --network=host --shm-size 32g --memory 128g --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --name mig-test -itd nvcr.io/nvidi
a/pytorch:23.02-py3`
2. Run the following commands inside the docker:
#!/bin/bash
git clone https://github.com/NVIDIA/FasterTransformer.git
mkdir -p FasterTransformer/build
cd FasterTransformer/build
git submodule init && git submodule update
cmake -DSM=90 -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON -DBUILD_MULTI_GPU=ON -DENABLE_FP8=ON ..
make -j
git clone https://huggingface.co/gpt2-xl
python ../examples/pytorch/gpt/utils/huggingface_gpt_convert.py -i gpt2-xl/ -o ./models/huggingface-models/c-model/gpt2-xl -i_g 1
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
mkdir models/345m/ -p
unzip megatron_lm_345m_v0.0.zip -d ./models/345m
export PYTHONPATH=$PWD/..:${PYTHONPATH}
python3 ../examples/pytorch/gpt/utils/megatron_fp8_ckpt_convert.py \
-i ./models/345m/release \
-o ./models/345m/c-model/ \
-i_g 1 \
-head_num 16 \
-trained_tensor_parallel_size 1
python3 ../examples/pytorch/gpt/gpt_summarization.py \
--data_type fp8 \
--lib_path ./lib/libth_transformer.so \
--summarize \
--ft_model_location ./models/345m/c-model/ \
--hf_model_location ./gpt2-xl/
Received the below errors:
Reusing dataset cnn_dailymail (/workdir/datasets/ccdv/ccdv___cnn_dailymail/3.0.0/3.0.0/0107f7388b5c6fae455a5661bcd134fc22da53ea75852027040d8d1e997f101f)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1084.45it/s]
top_k: 1
top_p: 0.0
int8_mode: 0
random_seed: 5
temperature: 1
max_seq_len: 1024
max_batch_size: 1
repetition_penalty: 1
vocab_size: 50304
tensor_para_size: 1
pipeline_para_size: 1
lib_path: ./lib/libth_transformer.so
ckpt_path: ./models/345m/c-model/1-gpu
hf_config: {'activation_function': 'gelu_new', 'architectures': ['GPT2LMHeadModel'], 'attn_pdrop': 0.1, 'bos_token_id': 50256, 'embd_pdrop': 0.1, 'eos_token_id': 50256, 'initializer_range': 0.02, 'layer_norm_epsilon': 1e-05, 'model_type': 'gpt2', 'n_ctx': 1024, 'n_embd': 1600, 'n_head': 25, 'n_layer': 48, 'n_positions': 1024, 'output_past': True, 'resid_pdrop': 0.1, 'summary_activation': None, 'summary_first_dropout': 0.1, 'summary_proj_to_labels': True, 'summary_type': 'cls_index', 'summary_use_proj': True, 'task_specific_params': {'text-generation': {'do_sample': True, 'max_length': 50}}, 'vocab_size': 50257}
[FT][WARNING] Skip NCCL initialization since requested tensor/pipeline parallel sizes are equals to 1.
[WARNING] gemm_config.in is not found; using default GEMM algo
[FT][ERROR] CUDA runtime error: CUBLAS_STATUS_INVALID_VALUE /home/.../FasterTransformer/src/fastertransformer/utils/cublasFP8MMWrapper.cu:277
Can you try the docker image recommended in the document?
Thanks @byshiue for your quick reply! Do you mean this docker image nvcr.io/nvidia/pytorch:22.09-py3?
Just tried nvcr.io/nvidia/pytorch:22.09-py3, but still got the same error message.
I also ran the below commands to tune gemm, but fp8 is multiple times slower than fp16 in 8 of 11 cases (please check the last column (speedup) in the below table). Is it expected?
./bin/gpt_gemm 8 1 32 12 128 6144 51200 4 1 1
./bin/gpt_gemm 8 1 32 12 128 6144 51200 1 1 1
| batch_size | seq_len | head_num | size_per_head | dataType | ### | batchCount | n | m | k | algoId | customOption | tile | numSplitsK | swizzle | reductionScheme | workspaceSize | stages | exec_time | speedup |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | 32 | 12 | 128 | 4 | ### | 1 | 4608 | 256 | 1536 | 52 | 0 | 31 | 1 | 0 | 0 | 131 | 36 | 0.013807 | 0.825235 |
| 8 | 32 | 12 | 128 | 4 | ### | 96 | 32 | 32 | 128 | 52 | 0 | 31 | 1 | 0 | 0 | 131 | 36 | 0.009926 | 2.618997 |
| 8 | 32 | 12 | 128 | 4 | ### | 96 | 128 | 32 | 32 | 52 | 0 | 31 | 1 | 0 | 0 | 131 | 36 | 0.009689 | 2.590642 |
| 8 | 32 | 12 | 128 | 4 | ### | 1 | 1536 | 256 | 1536 | 52 | 0 | 20 | 1 | 0 | 0 | 131 | 36 | 0.011924 | 1.216735 |
| 8 | 32 | 12 | 128 | 4 | ### | 1 | 6144 | 256 | 1536 | 52 | 0 | 31 | -1 | 0 | 2 | 131 | 36 | 0.013776 | 0.849793 |
| 8 | 32 | 12 | 128 | 4 | ### | 1 | 1536 | 256 | 6144 | 52 | 0 | 20 | 1 | 0 | 0 | 131 | 36 | 0.022243 | 1.277599 |
| 8 | 1 | 12 | 128 | 4 | ### | 1 | 4608 | 8 | 1536 | 52 | 0 | 31 | 1 | 0 | 0 | 131 | 36 | 0.013838 | 1.576082 |
| 8 | 1 | 12 | 128 | 4 | ### | 1 | 1536 | 8 | 1536 | 52 | 0 | 31 | 1 | 0 | 0 | 131 | 36 | 0.013509 | 2.182391 |
| 8 | 1 | 12 | 128 | 4 | ### | 1 | 6144 | 8 | 1536 | 52 | 0 | 31 | 1 | 0 | 0 | 131 | 36 | 0.013831 | 1.5266 |
| 8 | 1 | 12 | 128 | 4 | ### | 1 | 1536 | 8 | 6144 | 52 | 0 | 31 | 1 | 0 | 0 | 131 | 36 | 0.028986 | 2.848187 |
| 8 | 1 | 12 | 128 | 4 | ### | 1 | 51200 | 8 | 1536 | 52 | 0 | 31 | 1 | 0 | 0 | 131 | 36 | 0.028986 | 0.484068 |
| 8 | 32 | 12 | 128 | 1 | ### | 1 | 4608 | 256 | 1536 | 39 | 0 | 18 | -1 | 0 | 2 | 131 | 35 | 0.016731 | |
| 8 | 32 | 12 | 128 | 1 | ### | 96 | 32 | 32 | 128 | 113 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0.00379 | |
| 8 | 32 | 12 | 128 | 1 | ### | 96 | 128 | 32 | 32 | 110 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0.00374 | |
| 8 | 32 | 12 | 128 | 1 | ### | 1 | 1536 | 256 | 1536 | 114 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0.0098 | |
| 8 | 32 | 12 | 128 | 1 | ### | 1 | 6144 | 256 | 1536 | 39 | 0 | 20 | -1 | 0 | 2 | 131 | 35 | 0.016211 | |
| 8 | 32 | 12 | 128 | 1 | ### | 1 | 1536 | 256 | 6144 | 109 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0.01741 | |
| 8 | 1 | 12 | 128 | 1 | ### | 1 | 4608 | 8 | 1536 | 115 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0.00878 | |
| 8 | 1 | 12 | 128 | 1 | ### | 1 | 1536 | 8 | 1536 | 114 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0.00619 | |
| 8 | 1 | 12 | 128 | 1 | ### | 1 | 6144 | 8 | 1536 | 100 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0.00906 | |
| 8 | 1 | 12 | 128 | 1 | ### | 1 | 1536 | 8 | 6144 | 21 | 0 | 15 | 11 | 0 | 2 | 540672 | 16 | 0.010177 | |
| 8 | 1 | 12 | 128 | 1 | ### | 1 | 51200 | 8 | 1536 | 110 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | 0.05988 |
FP8 does not support gemm tuning now.
We cannot reproduce your issue. Can you run the program with environment variable FT_DEBUG_LEVEL=DEBUG again? We also guess it may be caused by MIG. Can you try running on full H100 first?
Got the same error in H100 and H100-MIG as below:
[FT][ERROR] CUDA runtime error: an illegal memory access was encountered FasterTransformer/src/fastertransformer/models/gpt_fp8/GptFP8ContextDecoder.cc:243
Can you post your scripts and full log?
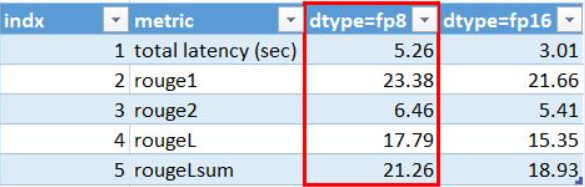
Hi @byshiue, I create new docker containers to test it again. For nvcr.io/nvidia/pytorch:22.09-py3, I confirm it works well now (not quite sure why it failed last time), but I also notified that FP8 is slower than FP16 based on the logging info as below. It seems to be unexpected.
- FP16:
Faster Transformers (total latency: 3.274726152420044 sec)
rouge1 : 21.664839291439336
rouge2 : 5.412904663794084
rougeL : 15.354753879504434
rougeLsum : 18.928251038380523
- FP8:
Faster Transformers (total latency: 4.783168077468872 sec)
rouge1 : 23.47552607890326
rouge2 : 6.86675093270573
rougeL : 17.23756077641688
rougeLsum : 20.871397598597387
For nvcr.io/nvidia/pytorch:23.02-py3, it failed as below.
- Do you know how the newer version of pytorch docker causes the failure?
root@rl-dgxh-r72-u24:/workspace/FasterTransformer# python3 examples/pytorch/gpt/utils/megatron_fp8_ckpt_convert.py
-i ./models/345m/release -o ./models/345m/c-model/ -i_g 1 -head_num 16 -trained_tensor_para
llel_size 1
=============== Argument ===============
saved_dir: ./models/345m/c-model/
in_file: ./models/345m/release
infer_gpu_num: 1
head_num: 16
trained_tensor_parallel_size: 1
processes: 16
weight_data_type: fp32
load_checkpoints_to_cpu: 1
vocab_path: None
merges_path: None
========================================
[INFO] Spent 0:00:03.138548 (h:m:s) to convert the model
root@rl-dgxh-r72-u24:/workspace/FasterTransformer# python3 examples/pytorch/gpt/gpt_summarization.py --data_ty
pe fp8 --lib_path ./build/lib/libth_transformer.so --summarize --ft_model_location ./models/34
5m/c-model/ --hf_model_location ./gpt2-xl/
/workspace/FasterTransformer/examples/pytorch/gpt/utils/gpt.py:221: SyntaxWarning: assertion is always true, perhaps r
emove parentheses?
assert(self.pre_embed_idx < self.post_embed_idx, "Pre decoder embedding index should be lower than post decoder embe
dding index.")
Reusing dataset cnn_dailymail (/workdir/datasets/ccdv/ccdv___cnn_dailymail/3.0.0/3.0.0/0107f7388b5c6fae455a5661bcd134f
c22da53ea75852027040d8d1e997f101f)
100%|█████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1038.62it/s]
top_k: 1
top_p: 0.0
int8_mode: 0
random_seed: 5
temperature: 1
max_seq_len: 1024
max_batch_size: 1
repetition_penalty: 1
vocab_size: 50304
tensor_para_size: 1
pipeline_para_size: 1
lib_path: ./build/lib/libth_transformer.so
ckpt_path: ./models/345m/c-model/1-gpu
hf_config: {'activation_function': 'gelu_new', 'architectures': ['GPT2LMHeadModel'], 'attn_pdrop': 0.1, 'bos_token_id'
: 50256, 'embd_pdrop': 0.1, 'eos_token_id': 50256, 'initializer_range': 0.02, 'layer_norm_epsilon': 1e-05, 'model_type
': 'gpt2', 'n_ctx': 1024, 'n_embd': 1600, 'n_head': 25, 'n_layer': 48, 'n_positions': 1024, 'output_past': True, 'resi
d_pdrop': 0.1, 'summary_activation': None, 'summary_first_dropout': 0.1, 'summary_proj_to_labels': True, 'summary_type
': 'cls_index', 'summary_use_proj': True, 'task_specific_params': {'text-generation': {'do_sample': True, 'max_length'
: 50}}, 'vocab_size': 50257}
[FT][WARNING] Skip NCCL initialization since requested tensor/pipeline parallel sizes are equals to 1.
[WARNING] gemm_config.in is not found; using default GEMM algo
[FT][ERROR] CUDA runtime error: an illegal memory access was encountered /workspace/FasterTransformer/src/fastertransf
ormer/models/gpt_fp8/GptFP8ContextDecoder.cc:243
Here is the script I used to run tests:
docker run --privileged --gpus '"device=0"' --network=host --shm-size 32g --memory 128g --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --name ft-h100-test -itd nvcr.io/nvidia/pytorch:22.09-py3
git clone https://github.com/NVIDIA/FasterTransformer.git
cd FasterTransformer && git submodule init && git submodule update
mkdir build && cd build
cmake -DSM=90 -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON -DBUILD_MULTI_GPU=ON -DENABLE_FP8=ON ..
make -j
pip install -r ../examples/pytorch/gpt/requirement.txt
cd ../ && git clone https://huggingface.co/gpt2-xl
python examples/pytorch/gpt/utils/huggingface_gpt_convert.py -i gpt2-xl/ -o ./models/huggingface-models/c-model/gpt2-xl -i_g 1
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
mkdir models/345m/ -p && unzip megatron_lm_345m_v0.0.zip -d ./models/345m
export PYTHONPATH=$PWD:${PYTHONPATH}
export FT_DEBUG_LEVEL=DEBUG
python3 examples/pytorch/gpt/utils/megatron_fp8_ckpt_convert.py \
-i ./models/345m/release \
-o ./models/345m/c-model/ \
-i_g 1 \
-head_num 16 \
-trained_tensor_parallel_size 1
python3 examples/pytorch/gpt/gpt_summarization.py \
--data_type fp8 \
--lib_path ./build/lib/libth_transformer.so \
--summarize \
--ft_model_location ./models/345m/c-model/ \
--hf_model_location ./gpt2-xl/
It may be the cublaslt of latest docker image have some updates. We don't verify on this version yet.
For performance between fp16 and fp8, fp8 only brings speedup when the batch size is large enough. But the batch size in the example is only 1.
For performance between fp16 and fp8, fp8 only brings speedup when the batch size is large enough. But the batch size in the example is only 1.
I made some minor changes in gpt_summarization.py to make fp8 work with the batch input. When the shape of line_encoded = [64, 658], fp16 took around 0.60 seconds, but fp8 took around 1.77 seconds. Is it expected? Not sure if there are any issues in the dev environment setup. Could you please share some rough perf numbers for the perf of FP8 if you have? For larger input shape, fp8 met runtime error without any log info even when setting export FT_DEBUG_LEVEL=DEBUG.
Can you use nsys to run the profiling for your test? For example,
nsys profile -o fp8 python gpt_summarization.py --data_type fp8
Hi @byshiue , I run into the same issue as mentioned by feihugis. Here I use the example where the batch_size=1. Any update on this issue?
Branch/Tag/Commit
main
Docker Image Version
nvcr.io/nvidia/pytorch:23.02-py3
GPU name
H100 MIG
CUDA Driver
525.85.12
Reproduced Steps
1. `docker run --privileged --gpus '"device=MIG-***"' --network=host --shm-size 32g --memory 128g --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --name mig-test -itd nvcr.io/nvidi a/pytorch:23.02-py3` 2. Run the following commands inside the docker: #!/bin/bash git clone https://github.com/NVIDIA/FasterTransformer.git mkdir -p FasterTransformer/build cd FasterTransformer/build git submodule init && git submodule update cmake -DSM=90 -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON -DBUILD_MULTI_GPU=ON -DENABLE_FP8=ON .. make -j git clone https://huggingface.co/gpt2-xl python ../examples/pytorch/gpt/utils/huggingface_gpt_convert.py -i gpt2-xl/ -o ./models/huggingface-models/c-model/gpt2-xl -i_g 1 wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip mkdir models/345m/ -p unzip megatron_lm_345m_v0.0.zip -d ./models/345m export PYTHONPATH=$PWD/..:${PYTHONPATH} python3 ../examples/pytorch/gpt/utils/megatron_fp8_ckpt_convert.py \ -i ./models/345m/release \ -o ./models/345m/c-model/ \ -i_g 1 \ -head_num 16 \ -trained_tensor_parallel_size 1 python3 ../examples/pytorch/gpt/gpt_summarization.py \ --data_type fp8 \ --lib_path ./lib/libth_transformer.so \ --summarize \ --ft_model_location ./models/345m/c-model/ \ --hf_model_location ./gpt2-xl/Received the below errors:
Reusing dataset cnn_dailymail (/workdir/datasets/ccdv/ccdv___cnn_dailymail/3.0.0/3.0.0/0107f7388b5c6fae455a5661bcd134fc22da53ea75852027040d8d1e997f101f) 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1084.45it/s] top_k: 1 top_p: 0.0 int8_mode: 0 random_seed: 5 temperature: 1 max_seq_len: 1024 max_batch_size: 1 repetition_penalty: 1 vocab_size: 50304 tensor_para_size: 1 pipeline_para_size: 1 lib_path: ./lib/libth_transformer.so ckpt_path: ./models/345m/c-model/1-gpu hf_config: {'activation_function': 'gelu_new', 'architectures': ['GPT2LMHeadModel'], 'attn_pdrop': 0.1, 'bos_token_id': 50256, 'embd_pdrop': 0.1, 'eos_token_id': 50256, 'initializer_range': 0.02, 'layer_norm_epsilon': 1e-05, 'model_type': 'gpt2', 'n_ctx': 1024, 'n_embd': 1600, 'n_head': 25, 'n_layer': 48, 'n_positions': 1024, 'output_past': True, 'resid_pdrop': 0.1, 'summary_activation': None, 'summary_first_dropout': 0.1, 'summary_proj_to_labels': True, 'summary_type': 'cls_index', 'summary_use_proj': True, 'task_specific_params': {'text-generation': {'do_sample': True, 'max_length': 50}}, 'vocab_size': 50257} [FT][WARNING] Skip NCCL initialization since requested tensor/pipeline parallel sizes are equals to 1. [WARNING] gemm_config.in is not found; using default GEMM algo [FT][ERROR] CUDA runtime error: CUBLAS_STATUS_INVALID_VALUE /home/.../FasterTransformer/src/fastertransformer/utils/cublasFP8MMWrapper.cu:277
@feihugis Hi, I have some questions and I hope to receive your advice.
- Why use --hf_model_location ./gpt2-xl/ ? megatron_lm_345m does not have a corresponding hf model format, and currently the ft8 model does not support hf_ fp8, this parameter seems to be of little use here.
- When I use --weights_data_type fp16, the model will load fails, as follows: ` Reusing dataset cnn_dailymail (/root/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0/a88add311826ada312ac2321c9f0cf00dcc10f72c4b832fbab9dadae87052b48) 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 272.51it/s] top_k: 1 top_p: 0.0 int8_mode: 0 random_seed: 5 temperature: 1 max_seq_len: 1024 max_batch_size: 1 repetition_penalty: 1 vocab_size: 50304 tensor_para_size: 1 pipeline_para_size: 1 lib_path: ./lib/libth_transformer.so ckpt_path: ../models/345m/c-model/1-gpu hf_config: {'activation_function': 'gelu_new', 'architectures': ['GPT2LMHeadModel'], 'attn_pdrop': 0.1, 'bos_token_id': 50256, 'embd_pdrop': 0.1, 'eos_token_id': 50256, 'initializer_range': 0.02, 'layer_norm_epsilon': 1e-05, 'model_type': 'gpt2', 'n_ctx': 1024, 'n_embd': 1600, 'n_head': 25, 'n_layer': 48, 'n_positions': 1024, 'output_past': True, 'resid_pdrop': 0.1, 'summary_activation': None, 'summary_first_dropout': 0.1, 'summary_proj_to_labels': True, 'summary_type': 'cls_index', 'summary_use_proj': True, 'task_specific_params': {'text-generation': {'do_sample': True, 'max_length': 50}}, 'vocab_size': 50257} [FT][WARNING] Skip NCCL initialization since requested tensor/pipeline parallel sizes are equals to 1. [FT][WARNING] file ../models/345m/c-model/1-gpu/model.wpe.bin only has 2097152, but request 4194304, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.wte.bin only has 103022592, but request 206045184, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.final_layernorm.bias.bin only has 2048, but request 4096, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.final_layernorm.weight.bin only has 2048, but request 4096, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.wte.bin only has 103022592, but request 206045184, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.layers.0.input_layernorm.bias.bin only has 2048, but request 4096, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.layers.0.input_layernorm.weight.bin only has 2048, but request 4096, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.layers.0.attention.query_key_value.bias.0.bin only has 6144, but request 12288, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.layers.0.attention.dense.bias.bin only has 2048, but request 4096, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.layers.0.post_attention_layernorm.bias.bin only has 2048, but request 4096, loading model fails!
[FT][WARNING] file ../models/345m/c-model/1-gpu/model.layers.0.post_attention_layernorm.weight.bin only has 2048, but request 4096, loading model fails! ` Can the ../examples/pytorch/gpt/utils/megatron_fp8_ckpt_convert.py and ../examples/pytorch/gpt/gpt_summarization.py only use the weight of fp32 here?
Hi @byshiue , I run into the same issue as mentioned by feihugis. Here I use the example where the batch_size=1. Any update on this issue?
@wohenniubi May I ask how to control parameters and commands to distinguish between FP16 results and FP8 results here. First, select fp8 or fp16 through the --data_type parameter. Secondly, for both fp8 and fp16, are the --weights_data_type parameters set to fp16? Thirdly, how do you set the --ft_model_location parameters for fp8 and fp16. For fp8, use the ../models/345m/c-model/ path, but for fp16, what model path do you use ?The fp16 model for converting megatron_ckpt_convert.py or megatron_fp8_ckpt_convert.py scripts?