ECHO
ECHO

paddlepaddle2.6版本 运行Matting操作流程就和quickstart里的一样,在进行背景替换时会报一个错误  我看了下应该是np数组大小不一致导致的。  这边fg的大小是(1,1,3)。 然后我在_estimate_fb_ml这个函数里加了个print语句  然后代码就正常运行了  我不能理解是什么原因导致的
我用torch的tensorrt包把RealESRGAN_x4模型转成trt模型,用了多进程还有异步io,在处理图片时勉强达到1秒1张的水平,虽然从图片角度看还行,但如果用来超分视频的话1秒25帧的视频就要花25秒这就感觉挺慢的了,所以我想问问除了我上面用的方法还有哪些方法能使处理速度提升?还是只能从硬件层面解决?
### 是否已有关于该错误的issue或讨论? | Is there an existing issue / discussion for this? - [X] 我已经搜索过已有的issues和讨论 | I have searched the existing issues / discussions ### 该问题是否在FAQ中有解答? | Is there an...
跑speaker_diarization任务的时候发现分割出的时间大于输入音频的最大长度 ```python dinference_diar_pipline = pipeline( mode="sond_demo", num_workers=0, task=Tasks.speaker_diarization, diar_model_config="sond.yaml", model='damo/speech_diarization_sond-zh-cn-alimeeting-16k-n16k4-pytorch', model_revision="v1.0.5", sv_model="damo/speech_xvector_sv-zh-cn-cnceleb-16k-spk3465-pytorch", sv_model_revision="v1.2.2", ) audio_list=[ "../2.wav", "../spk1.wav", "../spk2.wav", "../spk3.wav", "../spk4.wav", ] results = inference_diar_pipline(audio_in=audio_list) print(results) {'text': 'spk1 [(0.0, 18.8), (55.36,...
加载微调后保存在logs文件夹下的GPT和VITS模型或报错,但又不影响输出推理结果。  但加载自动保存在weights下的模型就没有该错误,但weights下的模型效果不如logs文件夹下的。 而且加载weights的模型推理后再重新加载logs文件夹下的模型推理生成的音频文件音色相同,重启推理webui后直接加载logs文件夹下的模型推理生成的音频又会与上述音频的音色不同。
代码就是demo中的例子,例子中SparseFeat的vocabulary_size大小设置为最大值+1 ``` fixlen_feature_columns = [SparseFeat(feat, data[feat].max() + 1,embedding_dim=4) for feat in sparse_features] ``` 当我将其改为1时代码仍能成功运行 ``` fixlen_feature_columns = [SparseFeat(feat, 1,embedding_dim=4) for feat in sparse_features] ```  而当我禁用gpu,使用cpu训练模型时tensorflow则会提示我越界错误 
想知道变长输入是如何使用tf.feature_column处理的,也是和sparse_feature一样的处理方式吗,但这样原来VarLenSparseFeat的maxlen参数就没有被使用到了。
**Describe the question(问题描述)** 使用DeepFEFM训练模型,训练集loss在下降,val_loss第一次最低然后逐渐升高。按理说这种情况是模型过拟合了,但训练第一个epoch就过拟合有些不合理吧 **Additional context**  **Operating environment(运行环境):** - python version [e.g. 3.6] - tensorflow version [e.g. 1.4.0, 1.15.0, 2.10.0] - deepctr version [e.g. 0.9.2,]
使用的文档里的ml-1m-ensfm的数据集,输出的loss一直为负数,且越来越小 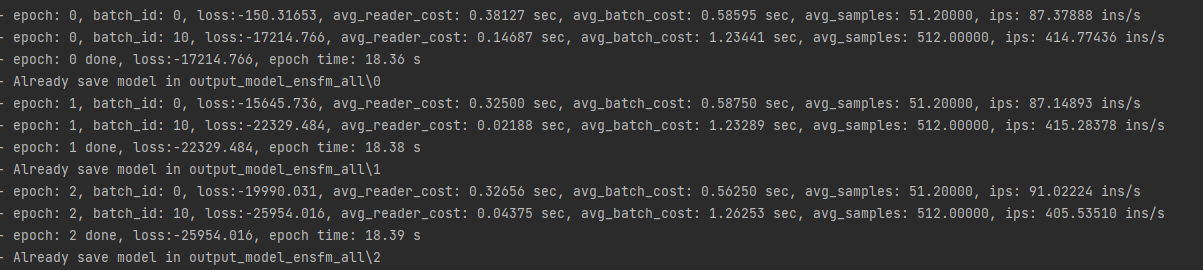
下载criteo原生数据后使用data_process.sh对数据进行处理但得出的结果与直接下载的paddle预处理过的数据不一样。   所以想知道原生数据到预处理数据之间的这一块是怎么做的。