zhaohongbo
zhaohongbo
I used the ONNX Parser and the plan file was converted from the ONNX model file.
@ttyio Thank you for your reply, logs are as follows: command: ```shell nsys profile -o 0316 --stats=true trtexec --loadEngine=slice_single.plan --dumpProfile --separateProfileRun ``` output: ```shell Warning: LBR backtrace method is not...
The following link is the log file that opened TRT_LOGGER = trt.logger (trt.logger.verbose) when building the plan file, I put it on Google cloud disk because it was too big:...
I find a lot of Layer(Reformat) when build de plan file. why?
@ttyio I am sorry, I used your hotmail email to shared, now I use nvidia email to share again , you can get it
[https://drive.google.com/file/d/1jWcwHhHFpZ0qiRUIwA54qa7MSLL6BK9a/view?usp=sharing](url) this is plan file link. [https://drive.google.com/file/d/1rmSzJNDarV0FGc1ZF7Nidbsrt4h9c0CC/view?usp=sharing](url) this is onnx model file link
hi @ttyio thank you for your reply. q1: in real network slice's input is indeterminate and cannot be preprocessed. slice input is embedding lookup layer, it is a plugin. q2:...
@ttyio Another question is what if I want to implement my plugin to support FP16. are the inputs and outputs of the plugin still FP32? convert FP32 to FP16 before...
hi @ttyio slice op cuda kernel: 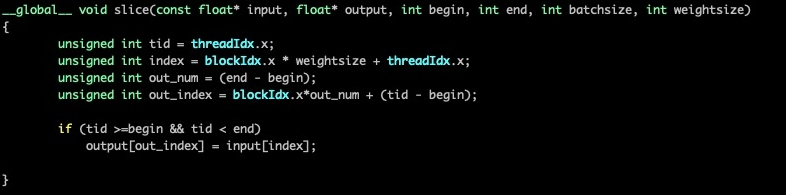 The address of the input he output is obtained from TensorRT's enqueue API,I dont know why copypackedkernel happend
hi @ttyio yes, my plugin is slower than native tensorrt op, but I just want to test whether my plugin will trigger the CopyPackedKernel. do we need the log in...