wtkszzz
wtkszzz
> > 这个项目是一个很棒的框架。但我有一些问题要问。 > > > > 1. 我注意到在预处理阶段,您根据标签掩码将每个图像裁剪成一个框(大于补丁大小(112、112、80))并获得一个 LA 区域。但后来,在 Dataset LAHeart 中,您添加了一个随机裁剪变换以再次将图像裁剪为 (112, 112, 80)。为什么这个?我认为只需裁剪到 (112, 112, 80) 并删除变换中的随机裁剪就足够了。随机裁剪可能会丢失一些 LA 信息。 > > 2. 在测试阶段,为什么要对一张图像的补丁进行多次推断?如果在预处理中裁剪到 (112, 112, 80)...
readme里由注释文件的地址。另外,可以分享以下Chuk-sys数据集吗,十分感谢!邮箱:[email protected]
请问你下载好GCC和SBU数据集了吗 可以分享一下吗 @wanng-ide
> _未提供说明。_ Hello!Can you run code on a pancreas dataset?I tried to preprocess the pancreas dataset but failed.I would appreciate if you could give me a preprocessing code of pancreas...
> 您好,非常感谢您的贡献。 > > 我无法重现您关于脾脏数据集的论文中显示的结果。 在 5%、10% 和 50% 标记设置下,最终的训练输出没有意义:    > > 你训练了多少个 epoch 才能得到这些结果? 你好,我用heart数据集上跑也是不收敛,dice非常低约是0,请问你解决这个问题了吗,我切片的时候发现groundtruth里有许多图是纯黑的,或许跟这个有关系
> 感谢您的贡献。 我注意到在核数据集中,一个图像的每个核都有多个掩码。但是,在训练时,在您的代码中,似乎每张图像只有一个掩码。我想知道您是否将所有面具组合成一个,或者我忽略了一些程序。 请问其它两个数据集你跑过吗,结果正常吗?
> Did you got data? I need it ,too. Please can I get the preprocessed data too? Thank you so much. Email: [email protected]
哪位有数据可以分享一下吗,不胜感激 邮箱:[email protected]
> 你拿到数据了吗?我也需要。 你好,请问你拿到预处理的数据了吗,可以分享一下吗,十分感谢![email protected]
> 找到了。我必须在 test.py 中更改它设置默认 parser.add_argument('--vit_name', type=str, default='R50-ViT-B_16', help='select one vit model') 你好,我在运行test.py时出现如下错误: 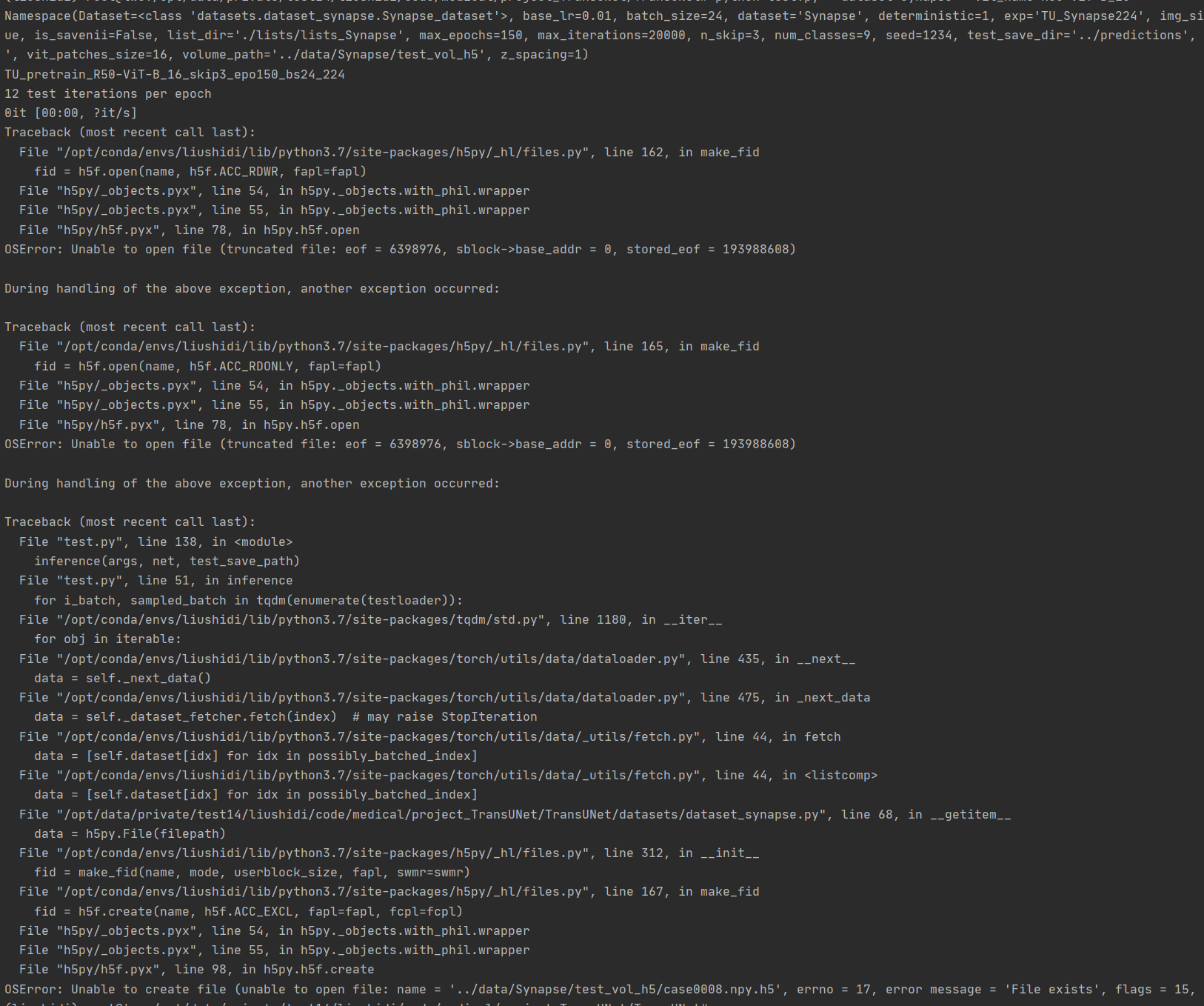 请问你知道如何解决吗,非常感谢!