valkryhx
valkryhx
请问: 在单机多卡环境 跑这段命令 报错 该怎么修改启动命令呢? RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0! (when checking argument for argument target...
参考trl和trlx这两个项目,GPT2+PPO 、GPT2+ILQL
> 合并语料 我看到tools目录下有个merge.py 是把lora adapter参数合并到大模型 那是不是可以用参数合并的方式而不是语料合并来连续微调呢
不如用qlora 一张24g卡就能调llama13b 效果也不差
> @Coder-nlper 我这里看是有的 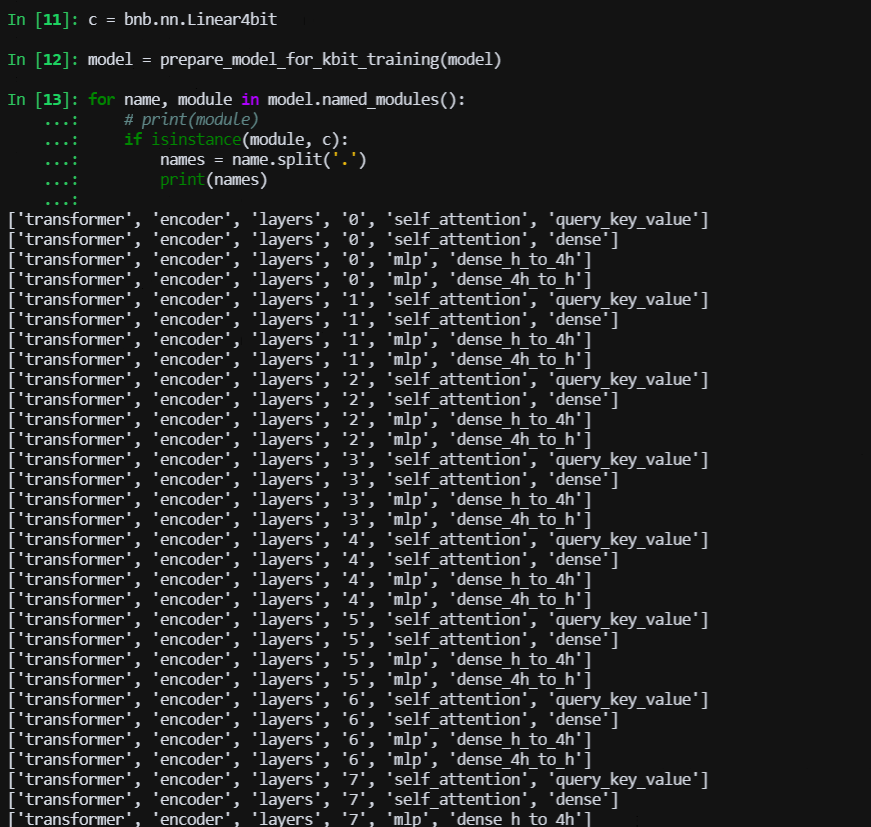 问一下,图片中哪些层是被量化的层,名字有提示吗?
请问您是使用了整个252K 的数据集进行LORA 微调吗? LR是脚本中默认值吗?我这边只有4K微调语料,LORA微调训练了10个epoch 感觉基本没学到东西。
> > 请问您是使用了整个252K 的数据集进行LORA 微调吗? LR是脚本中默认值吗?我这边只有4K微调语料,LORA微调训练了10个epoch 感觉基本没学到东西。 > > 嗯,我把训练限制从1000放到310000,eval限制从100放到500(如果换成1000会爆V100的32G显存),batchsize只能调整到2 好的 感谢您的指导
> > @bash99 我觉得现在有几种模式,可能要测一下: 1、base model + lora model,不合并的模式,也就是你试验过的 2、base model 和 lora model做merge,但不量化(我那个脚本支持这种) 3、base model和 lora model做merge,用官方的量化方法到4bit(我那个脚本就是这样的量化) 4、base model和lora model做merge,不量化,加载的时候用BitsAndBytesConfig,即nf4的方式加载 > > 3和1就是我之前对比的,推理质量(可靠性)大幅度下降的问题。1和2对比推理时无区别。 4我刚刚测了,对比1 推理质量下降很轻微(或者不可见)。 > > 对比了两种训练方式(lora和qlora),两种量化加载方式,用的CSC数据集,测试用例暂时比较有限。 lora比qlora,劣势:训练内存占用高、速度似乎稍慢、后期加载时必须合并;优势:可并行GPU加速;loss下降更快,3个epoch后的最低loss也更好;推理结果更好...
> > > > > 我把在chatglm-6b loRA微调后的模型移植到chatglm2-6b中,也没有得到想要推理结果,原来可是3万条数据集,推测应该不是数据量的问题。 > > 既然有3w条数据,训练之后可以看一下你的loraA和B的权重,a和b是不是为0?可能是我数据太小,B还是保持初始全0矩阵,准备拿个大的数据试一下再。 请问怎么样查看LORA 矩阵A和B的权重呢?
> 修改modeling_chatglm.py chat方法,我没有用流方式 ###### if not history: prompt = query else: prompt = "" for i, (old_query, response) in enumerate(history): prompt += "[Round {}]\n问:{}\n答:{}\n".format(i, old_query, response) prompt += "[Round {}]\n问:{}\n答:".format(len(history),...