v4if
v4if

### What happened + What you expected to happen It is not allowed to specify both num_cpus and num_gpus for map tasks. When only num_gpus is specified, num_cpus seems to...
使用DB.php连接数据库的时候报错 数据库链接失败: SQLSTATE[HY000] [2002] Connection refused
**Describe the bug:** behind nginx with a sub path, how to set the resource root path with the sub path such as: http://example.com/path/to/milvus nginx config: ``` location /path/to/milvus/ { proxy_pass...
## 第一章 绪论 机器学习正是这样一门学科,它致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。如果说计算机科学是研究关于`算法`的学问,那么可以说机器学习是研究关于`学习算法`的学问 若预测的是离散值,例如好瓜、坏瓜,此类学习任务称为`分类`;若预测的是连续值,例如西瓜的成熟度0.95、0.37,此类学习任务称为`回归`。一般地,预测任务是希望通过对训练集,(x_2,y_2),...,(x_m,Y_m)\rbrace)进行学习,建立一个从输入空间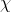到输出空间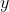的映射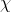。对二分任务,通常令或;对多分类任务,;对回归任务,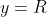,R为实数集 根据训练数据是否拥有标记信息,学习任务可大致划分为两大类:监督学习和无监督学习,分类和回归是前者的代表,而聚类则是后者的代表 通常假设样本空间中全体样本服从一个未知的`分布`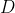,我们获得的每个样本都是独立地从这个分布上采样获得的,即`独立同分布`。一般而言,训练样本越多,得到的关于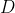的信息越多,这样就越有可能通过学习获得具有强 ## 第二章 模型评估与选择 通常把分类错误的样本数占样本总数的比例称为`错误率(error rate)`,即如果在m个样本中有a个样本分类错误,则错误率 称为精度(accuracy) 交叉验证法(cross validation) 调参(parameter tuning) 回归任务最常用的性能度量是`均方误差`(mean squared error) =\frac{1}{m}\sum_{i=1}^{m}(f(x_i)-y_i)^2) 查准率(precision)、查全率(recall)与F1 挑出的西瓜中有多少比例是好瓜、所有好瓜中有多少比例被挑了出来 ## 第三章 线性模型 给定由d个属性描述的示例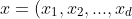),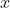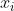在个属性上的取值,线性模型(linear model)试图学得一个通过属性的线性组合来进行预测的函数,即 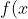=w_1x_1+w_2x_2+...+w_dx_d+b) 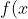=w^Tx+b)...
## pbdq blog [https://pbdq.github.io](https://pbdq.github.io) Data From:[https://github.com/v4if/blog/issues](https://github.com/v4if/blog/issues) ## 思路 使用issue写文章,将图片等资源放在`{repo}/assets`下做存储,利用Github API获取issue内容,Github Pages构造单页面应用 静态博客,无后台搭建,自动拉取issues内容渲染 ## Hack ``` // api https://api.github.com/repos/v4if/blog/issues ``` 默认会返回30条issue,为了拉取全部的issue,采用了一种相对hack的方法 ``` page: [int], // 当前页 per_page: [int] // 获取的条数 ```...
## 阻塞 阻塞会block住当前进程,非阻塞通常采用轮询的手段,本质上都是同步的; 只有使用了特殊的 API 才是异步 IO,如Linux的AIO和Windows的IOCP ## Docker [Docker 版本号说明](https://www.jianshu.com/p/348dca0e314c) Docker version 1.2.0 (2014-08-20)   Docker version 1.11.0 (2016-04-13) With Docker 1.11, a Linux docker installation is now...
## 'libproxychains.so.3' from LD_PRELOAD cannot be preloaded ``` ➜ ~ find /usr/ -name libproxychains.so.3 -print /usr/lib/x86_64-linux-gnu/libproxychains.so.3 ➜ ~ export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libproxychains.so.3 ``` ## cygwin apt-cyg You can do this using Cygwin’s...
## Buffers 数据传输效率不对称,或提前不知道接收数据的大小都需要进行缓冲区的设计,而对于TCP本身就是一个流协议,一次发送可能多次接收,一次接收也可能是多次堆积的数据,因此对于消息接收解析缓冲区的设计必不可少,用streambuf从async_read_some读取数据,然后再对streambuf里面的数据进行消费,通过split_and_process_message将streambuf里面完整的消息体取出 buffers又可以简单的表示成一个包含pointer和size的tuple,比如boost里面 ```c++ typedef std::pair mutable_buffer; typedef std::pair const_buffer; ``` 底部存储容器可以使用array、vector、string等 buffers的设计离不开内存的管理,一种方案是固定内存块大小,配合内存池,当缓冲块底层存储容量被消耗完了之后,将缓冲块释放到内存池,然后重新分配一个缓冲块;还有一种方案是对当前缓冲块进行重用,但是需要对没有consume的数据进行整理,调整到缓冲块的头部,asio::streambuf就是采取的这种方式 ## asio::streambuf asio::streambuf则是提供了一个流类型的buffer,它自身是能申请内存的,包含数据内容,而且内存可以自动增长。它的好处是可以通过stl的stream相关函数实现缓冲区操作,处理起来更加方便 而asio::buffer只是一个适配器,使用时需要注意原始数据源  put get 对asio::streambuf的简单测试 ```c++ size_t fake_read(boost::asio::streambuf::mutable_buffers_type buff) { size_t size_ =...
先抛出一个思考的问题,对象构造的时候什么时候选择栈上对象,什么时候选择需要去new一个对象,对象在作为参数传递的时候,谁来保证对象的有效性,所有权如何传递? 对象的构造分为栈上对象和堆上对象。 ## 栈对象 在对栈上的对象也即局部变量对象进行函数参数传递的时候,无非两种选择:值传递或者引用传递。值传递的情况比较简单,会增加数据拷贝的开销,对象越大,付出的代价就会越大,但是不会涉及所有权的问题,在调用者和被调用函数内部对象永远都是有效的,相当于建立了一个对象的副本,同样也不会对原有对象进行更改。因此值传递会带来两个问题:拷贝带来的性能代价和对形参的操作并不会对实参有所改变。 引用传递不会拷贝对象,好像可以避免值传递所带来的问题,但是在某些情况下却会有对象有效性的问题,比如`异步回调中局部变量对象的引用` ```c++ void timer_async_wait(boost::asio::io_service& ios) { int a = 1; boost::asio::steady_timer timer(ios); timer.expires_from_now(std::chrono::seconds(2)); timer.async_wait([&a](const boost::system::error_code& error){ std::cout
>Assuming you want your client to work with other servers, and server to work with other clients, your server can't expect to be treated nicely. There are two ways to...