Naoto Usuyama
Naoto Usuyama
Would be great to get expected pretraining results (e.g., loss, next-sentence-prediction accuracy, etc.) and learning curves using the 64 * V100 training. I found the fine-tuning task results on the...

> docker folder for docker file and instruction to use Azure Container Registry https://github.com/microsoft/AzureML-BERT/blob/master/pretrain/PyTorch/README.md It seems the custom image is not needed from this commit d49e7cd58ae68ff209e374fdb730d2cd4ef29521 , but would be...
Thanks for creating a great repo, organizing many segmentation models/datasets in one place! Wondering if you're planning to add support for instance segmentation / panoptic segmentation. The cityscape dataset provides...
## 一言でいうと 生物医学論文に特化した検索エンジン構築のための技術紹介。PubMed BERTを用いて検索結果のRe-Rankingを行う。 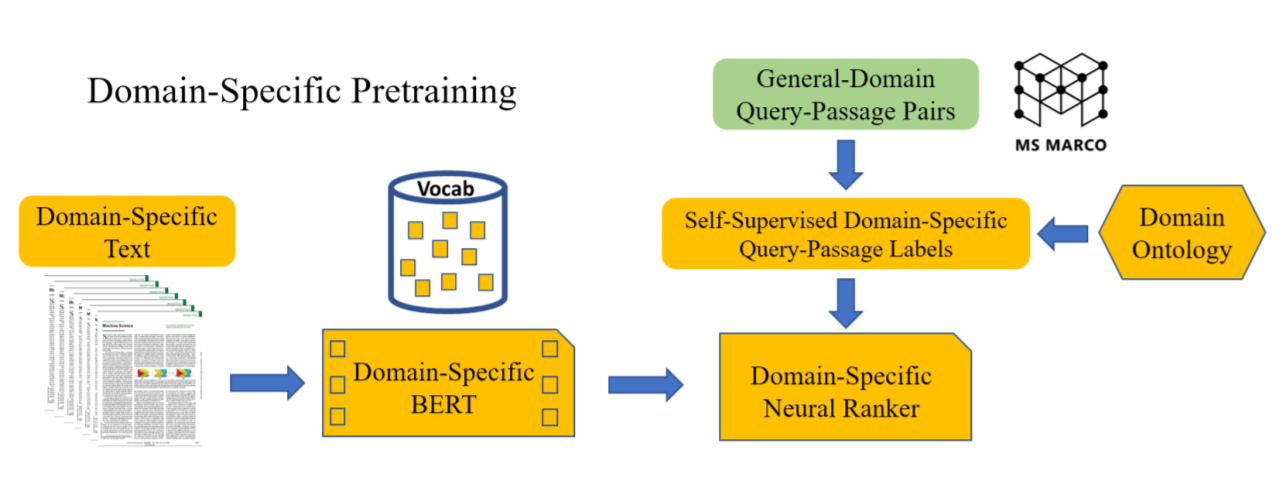 ### 論文リンク https://arxiv.org/abs/2106.13375 ### 著者/所属機関 Yu Wang, Jinchao Li, Tristan Naumann, Chenyan Xiong, Hao Cheng, Robert Tinn, Cliff Wong, Naoto Usuyama, Richard Rogahn, Zhihong Shen,...
Will you share some of your pretrained models? Would be great for quick testing and fine-tuning.
https://github.com/microsoft/hi-ml/blob/7fe55b0c177c4708fad2846c709ff16b2feac001/hi-ml/src/health_ml/utils/lr_scheduler.py#L43 Need to return LRs for each param group ``` def get_lr(self) -> List[float]: # type: ignore return [self.final_lr * self.warmup_multiplier() for g in self.optimizer.param_groups] ```
Has anyone tried running HistoQC on PySpark/Databricks? I'm thinking about ways to run HistoQC on a large dataset like all 30k slides from TCGA. I guess it should work with...
Has anyone tried saliency map visualizations with open_clip models? I came across these examples, but they only use OpenAI ResNet-based models. https://colab.research.google.com/github/kevinzakka/clip_playground/blob/main/CLIP_GradCAM_Visualization.ipynb https://huggingface.co/spaces/njanakiev/gradio-openai-clip-grad-cam
Currently, I think we're using [OpenAI mean/std](https://github.com/mlfoundations/open_clip/blob/694554495aedf97ac046e53a690ecd86aee96274/src/open_clip/constants.py#L1) even for timm pretrained image models. Better to use [ImageNet mean/std](https://github.com/rwightman/pytorch-image-models/blob/18ec173f95aa220af753358bf860b16b6691edb2/timm/data/constants.py#L3) for image models that were pretrained with imagenet.
I'm wondering if we can automatically run [clip_benchmark](https://github.com/LAION-AI/CLIP_benchmark) to get validation metrics. Currently, OpenCLIP integrates Imagenet zero-shot, but I'm particularly interested in utilizing other datasets, particularly biomedical datasets. I came...