urlchecker-python
 urlchecker-python copied to clipboard
urlchecker-python copied to clipboard
:snake: :link: Python module and client for checking URLs

sample markdown text like "输入`foo https://example.com`,然后", extracted url is "https://example.com`,然后", expected is "https://example.com"
No rush here, but I really like pre-commit over manually running each tool.
@vsoch Once again, here is another attempt at improving our long and forgiving nice regex :smile: A little background, the current regex is something I found online and after testing...
I've just seen https://github.com/urlstechie/urlchecker-python/blob/7fd08866c1550bd9746062c00c1c55fcb44b4e92/urlchecker/core/urlproc.py#L182 and this is brilliant (the user agent setting)! What about listing the strengths of this library in the README?
hey @SuperKogito - it occurred to me today that we don't support checking internal links, meaning that if we render a jekyll site, we aren't able to see if something...
Hi there, I was playing around with your library, and had to dig into your code to see how exclude patterns work. I _think_ I understand correctly that they're substrings...
- This PR replaces the old public Codacy token with a Travis hidden variable including the new token value. - The token is defined as an environment variable in Travis,...
This PR : - is related to #50 - implements urls checks accelerations using asyncio and aiohttp libs instead of requests - adds more test files and tests for better...
Urls are checked using a loop that tests the response of the requests sequentially, which becomes slow for huge websites. 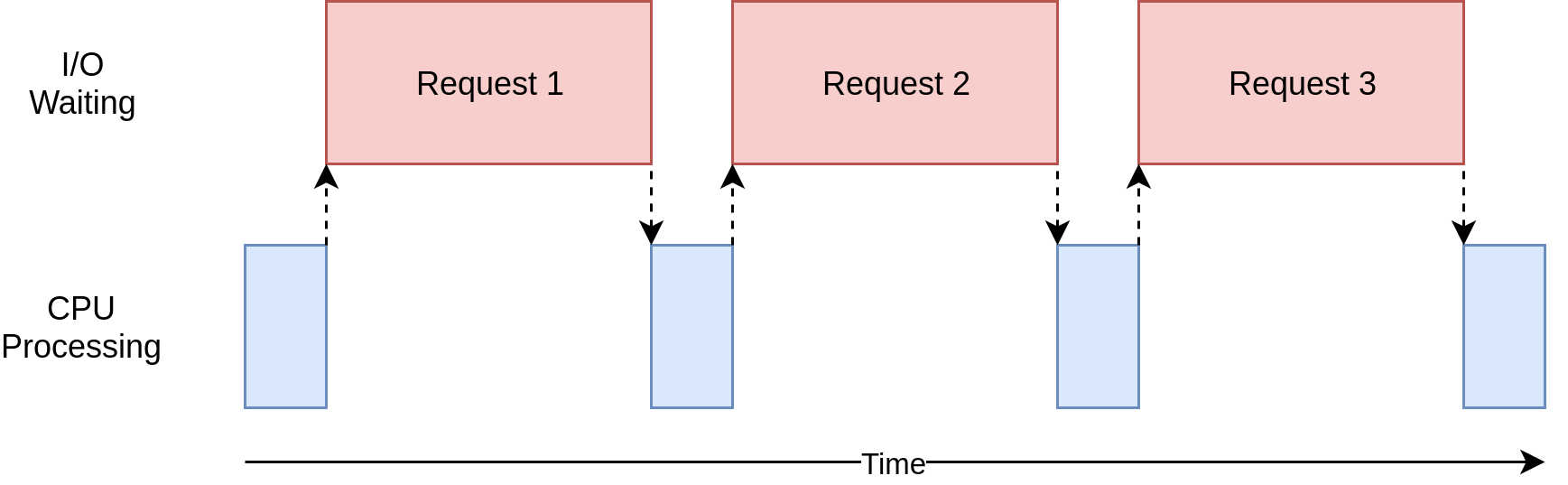 [Img source](https://realpython.com/python-concurrency/) Alternatively, we can use concurrency to process...
And along with this, an example CI run on CircleCI, which would allow us to save an html report and then render it (in the browser) directly as an artifact....
Metadata
Owner
Metadata
:snake: :link: Python module and client for checking URLs