István PONGRÁCZ
István PONGRÁCZ
Similar here? https://github.com/nextcloud/fulltextsearch/issues/617 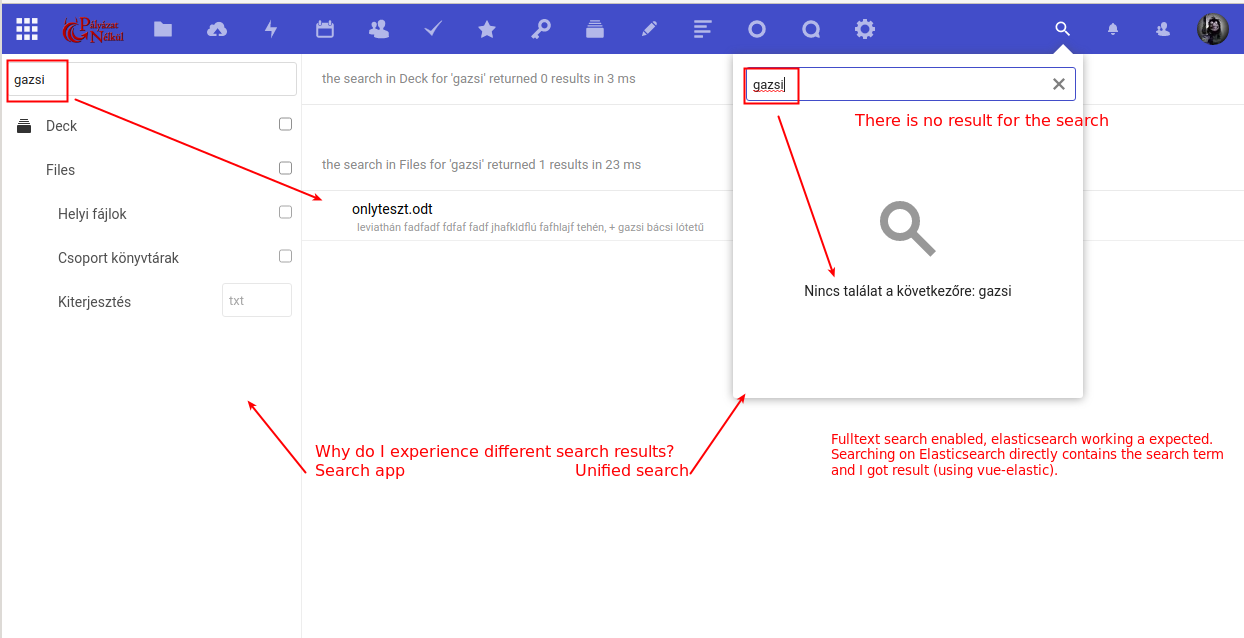
Hi Sabas, thanks for your quick response. It seems the parser can read the file content after decoding, even the file have syntax error (my opinion). The error count is...
Anyway, I just realized even I got error messages if I do not use the utf8_decode, the array filled up with data. Printing it as json or var_dumo, I do...
I think at this moment I would be happy with only the parser working with original UTF8 strings.... I could manage the array and get out what I want (mapping...
At this moment I suspend this original question.
My EDI file starts with this: ``` UNA:+.? ' UNB+UNOB:2+TECHNIQ+TERMIQUE+180720:1105+957' ```
I succeed with a brute force workaround: I commented out the following line to do not remove any characters: https://github.com/php-edifact/edifact/blob/6fc2fe50458085b6f47e7459852981be24e9aa20/src/EDI/Parser.php#L139
Hmmm, UNOB does not suppose to use UTF-8 characters, right? That is the reason, parser wants to strip as defined by the standard, so, technically your parser does what is...
Ok, the producer of my input file fixed the UNB to include the UNOY instead of UNOB and fixed some other smaller issues. So, as a summary: - using utf8...
Depending on the UNB settings in the file, I think one scenario should work: * new Reader/Parser without actual file or string * setStripRegex() --- force ignore UNB settings *...