piekey2022
piekey2022
> @piekey1994 分支 test_multiprocess version 0.3.2 [da5402a](https://github.com/a358003542/fenci/commit/da5402a8d9cbdd734131dd36556f96bb54783440) > > 移除原有的线程锁,只在模型写的那部分加上了文件锁,优化了模型的部分数据更新逻辑。 `update_json_file` 会将一些数据汇总之后再统一更新到模型文件中去。 > > 写了一个多线程和多进程的简单单元测试代码,但是老实说这块错误不是很方便重现。 > > @piekey1994 你可以帮忙尝试下最新的分支代码然后看看还会出现错误吗? 我之前是在gunicorn里面起多个worker时出现的问题,你可以试试
> @piekey1994 具体和本模块相关的运行代码也麻烦贴一下,如果只是多进程运行简单的分词已经测试没有问题了。gunicorn环境后面我再测一下。 没什么代码,就是gunicorn加载main文件的时候在import你这个包后初始化cache的时候就报错了,都没到分词那一步,有空我再实际测试一下吧
> @piekey1994 I have also same issue > > but the issue disappeared after fixing .pbtxt this line `dynamic_batching { max_queue_delay_microseconds: 70000 } -> dynamic_batching { } ` > >...
> @piekey1994, @S-GH : Can you provide repro steps and the model to repro with. The model and configuration come from https://github.com/WENET-E2e/WENET/Tree/Main/Runtime/Server/x86 _ GPU.
> @piekey1994, @S-GH : Can you provide repro steps and the model to repro with. > @piekey1994 Can you provide repro steps, models, etc. so that we can reproduce this...
you can try: rm -rf /root/.cache/colossalai
The implementation of their ppo seems to be more similar to trlx. I use your colossalai ppo without gae algorithm, and the model can continuously optimize 20 generate epochs, but...
> > 请问为何在13B的时候将位置编码从ROPE改为Alibi了。如果从长度外推的角度来考虑,我们最近看论文Rope通过插值也能做到很好的长度外推,请问改成Alibi是基于其他的一些考虑吗?谢谢~ > > 实际上,Alibi位置编码也具备RoPe的[位置插值](https://arxiv.org/pdf/2306.15595.pdf)特性,以下是Baichuan-13B-Chat在shareGPT-zh 1w token以上的样本做的实验。可以看到,插值的效果是优于外推的,并且插值并没有微调。 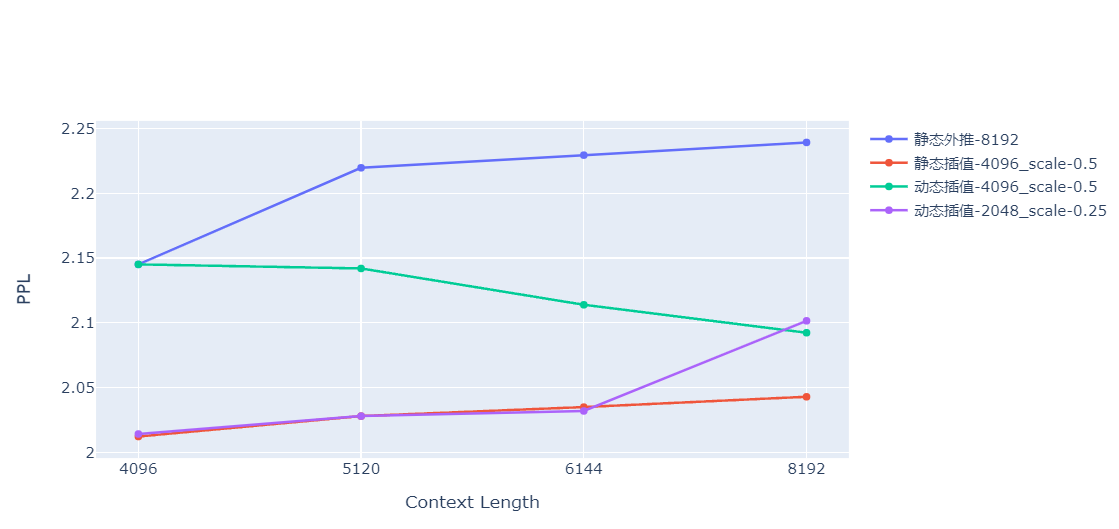 > > 也可以看到,ALiBi的外推能力在本测试集上是优于RoPe的,之前的7b模型在8192的点为上PPL是34+,而这里是2.24。 > > 图中还有个有趣的实验,就是插值是按静态插值(按固定最大长度计算缩放比例)和动态插值(按当前文本长度计算缩放比例)。如果这个实验靠谱,可能会得出几个猜想结论: > > 1. 想办法把超长的推理文本的位置编码压缩到模型训练的最大长度之内,模型的表现就会变好。 > 2. 在1.的基础上,统计SFT数据token的长度分布,将推理文本token长度压缩到该分布密度最高的长度上,模型表现最佳。 > > 以上结论和猜想仅供参考,实践需要自己根据自己的数据做测试。 同求插值的code,谢谢大佬
> When you are doing ordinary LLM training, you have a batch size that is the same as the max response count you can have. If you can train an...