pangkun248
pangkun248

我发现我的一个检测任务mAP和图片测试结果不吻合,经过排查不是过拟合的问题,因为我发现即使用那些验证集上的图片来进行测试,有些目标也没有被检测出来。同样的情况我更换另一个检测任务发现和mAP和测试结果符合。请问你知道是哪里出了问题吗    截图中红色椭圆型的是未检测出来的目标,按理说不应该出现这种情况才对呀
我用mobilenet_yolov3_lite从头来训练我自己的数据,因为自己的数据是二次元游戏截图,与现实物体差距较大,所以没有使用预训练模型。 但是我发现训练的结果与测试的结果相差很大,map几乎为0,但是recall几乎为1 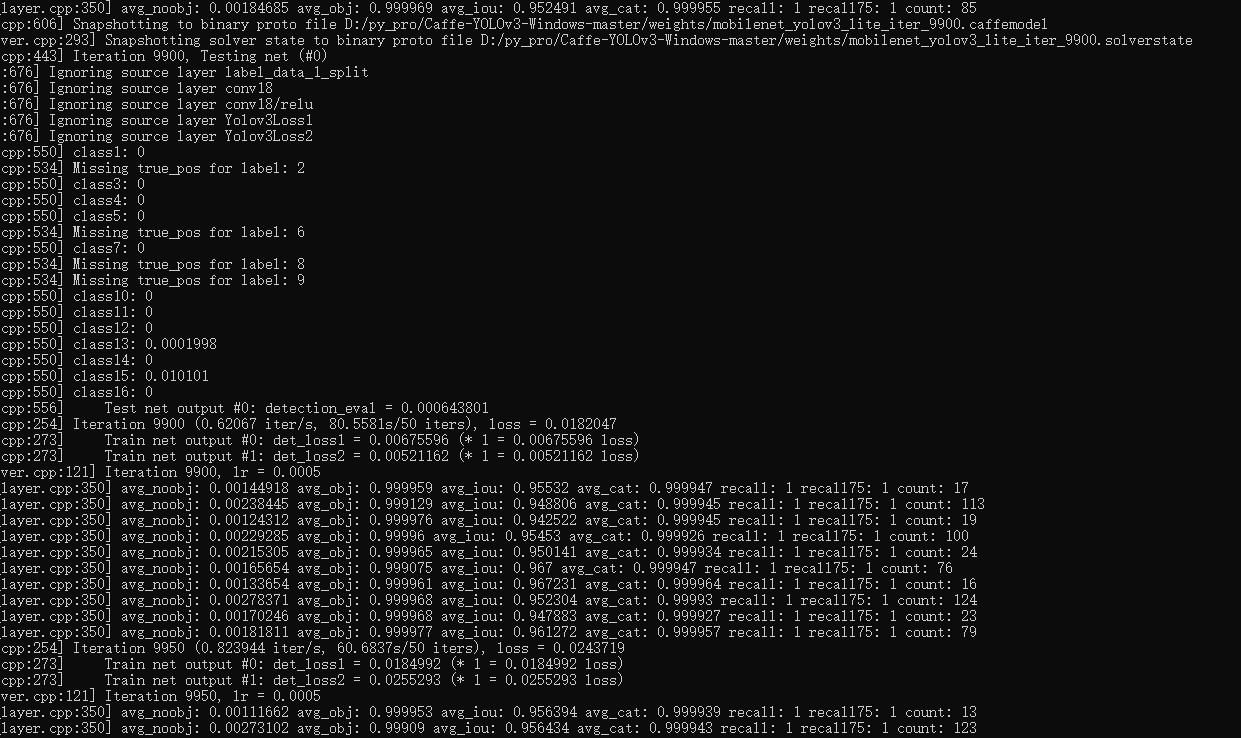 我的网络配置:https://drive.google.com/open?id=1TtzhXDKzwyiSvjqdPfHUK_dLjSJ2sS41 在配置中我把bn层给删掉了,但发现无论我删没删好像不是很影响结果的准确率.都不是像训练结果展现的那样。我拿图片(无论测试还是训练集)测试发现效果也不太好,虽然大部分能检测出来。但远没有达到recall=1我不太清楚问题出在哪了。所以有人知道这种情况为什么会发生吗,先谢谢了 :)
RT, 1.我发现使用您的这份代码剪枝(剪枝率70%~85%)后速度基本没有变化(29ms)。 2.使用您在README最下面给出的那份cfg文件,在2080Ti上forward的时间为29ms左右。 3.而且您的 剪枝前后指标对比表格数据中显示 Baseline (416) 的forward时间为15ms,难道不是29ms左右吗,如果使用的是YOLOv3原生的cfg文件的话。
如题,我看你计算loc和cls损失时都是计算正负样本的总损失。但是最后返回时却只除以了正样本数量。你能解释一下为什么要这样做吗。或者给我一个相关链接也行。
RT,原始论文中 0.5>IOU>0.4的anchor label好像都赋值为-1以此来忽略最终的loss计算,IOU
RT, 1.我阅读源码发现网络并非是并行运行。有些像对一个batch的数据进行for循环。 2.同时我发现bs从2开始往上提升的话对训练速度就没有收益了(怀疑和1有关),coco的话每个epoch约2h。我本地无法编译mmdetection。所有不确定原作者是否也是这种情况。 所以想在此和您探讨一下。
RT,我看到你的代码中时不时的要把数据从numpy上切换到cuda.tensor上或者从cuda.tensor切换到numpy上面,这一点我在chenyuntc/simple-faster-rcnn-pytorch的代码中也有发现。请问你知道有关这方面的技巧吗?让代码运行更快的技巧。就是应该在什么时候从numpy->cuda,而什么时候从cuda->numpy。或者如果你知道相关论文博客链接的话也可以。
[//]: # "SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved." [//]: # "SPDX-License-Identifier: Apache-2.0" [//]: # "" [//]: # "Licensed under the Apache License, Version 2.0 (the...