nowhereman1999
nowhereman1999
@Linzaer ,大佬,我是一名大二学生,目前在我们学校robomaster战队里负责用神经网络识别装甲板,但是用yolo系列的话最后的bbox并不能很好的拟合装甲板的轮廓,导致我们后期在使用pnp进行姿态解算时会有很大误差,所以我想使用关键点检测的方法得到的bbox效果要好很多,就用装甲板的四个角点,就是我看您的这个项目应该能够实现,我想问一下就是需要改动哪些地方呢,我看您的项目里关键点也是4个,这是否意味着我可以直接训练呢,因为我现在的标签格式是类别再加4个角点的归一化后的坐标,最后就是能够使用openvino部署吗,直接将onnx转成IR和bin调用就行了吗?
@yingfeng 大佬你好,就是我是一名大二学生,然后是在中北大学的robomaster战队里负责用神经网络识别装甲板实现自动瞄准,不过就是之前我用yolo系列训练出来的模型最后实际测试时得到的bbox和装甲板的轮廓并不能很好的拟合,导致后续使用pnp进行姿态解算时会有较大误差,所以我想将传统yolo的数据集格式改为用四个角点的归一化坐标,现在的数据集格式是像这样:1 0.673029 0.373564 0.678429 0.426232 0.830433 0.401262 0.824525 0.351212,第一个数字是类别id,后面八个数字是归一化后的装甲板的四个角点坐标,之前我使用yolov5-face已经训练出来一个可以直接定位装甲板四个角点的模型,效果如下:  然后很早之前就想尝试一些其他的人脸检测模型对比一下关键点定位精度,最开始是想用retinaface,但是当时也是因为数据集使用的widerface,我标注的yolo格式不能直接用于训练,当时也想过离线数据转换,就是写一个脚本将yolo格式转化为widerface格式,不过由于忙其他事一直没什么时间,后来就看到了scrfd这个模型,在人脸检测的速度和精度上都有不错的表现,而且使用的mmdet框架训练,注册机制对于修改模型很方便,但是现在我同样遇到了数据集格式转化的问题 # 0--Parade/0_Parade_marchingband_1_849.jpg 1024 1385 449.00000 330.00000 571.00000 479.00000 488.90601 373.64301 0.00000 542.08899 376.44199 0.00000 515.03101 412.82999 0.00000 485.17401...

@derronqi 大佬你好,就是我是一名大二学生,然后是在中北大学的robomaster战队里负责用神经网络识别装甲板实现自动瞄准,不过就是之前我用yolo系列训练出来的模型最后实际测试时得到的bbox和装甲板的轮廓并不能很好的拟合,导致后续使用pnp进行姿态解算时会有较大误差,所以我想将传统yolo的数据集格式改为用四个角点的归一化坐标,然后我看到了您这个项目,不过我看您的数据集格式里还是包含了传统yolo的归一化后的中心点坐标和w,h,然后我现在的数据集格式是像这样:1 0.673029 0.373564 0.678429 0.426232 0.830433 0.401262 0.824525 0.351212,第一个数字是类别id,后面八个数字是归一化后的装甲板的四个角点坐标,但是我看您的这个仓库里训练是用的wider face数据集,所以我想是得改动dataloader的部分才能训练吗?望大佬解惑
@duanshengliu 大佬你好,就是我是一名大二学生,然后是在中北大学的robomaster战队里负责用神经网络识别装甲板实现自动瞄准,不过就是之前我用yolo系列训练出来的模型最后实际测试时得到的bbox和装甲板的轮廓并不能很好的拟合,导致后续使用pnp进行姿态解算时会有较大误差,所以我想使用您的这个项目先做分割把车牌提取出来,后面再用opencv提取坐标,但是目前我就是不知道该如何制作分割所需的数据集,以往都是做的目标检测的数据集,所以想请教一下大佬您?
作者大佬你好,首先感谢你们杰出的工作并且开源,我是一名大二本科生,正在准备今年数学建模国赛,学校给我们发了几道练习题做,其实就是今年华中杯b题,2,3问回涉及到股票时间序列的分析,第1问我们首先是通过随机森林做了特征重要度分析,提取出来了与数字经济板块相关的一些指标,然后出去时间那列总共有10个变量,现在就是要求我们利用这个数据训练模型并预测,最开始我们尝试了多变量LSTM多步预测,数据是按每5分钟间隔排列的,总共6240行,其中前面5238行作为训练集,后面912行作为测试集来预测,是按照这篇文章的思路写的:https://zhuanlan.zhihu.com/p/191211602,但是最后我们在可视化预测结果后发现预测值在峰值处与实际值相差比较多如下图: 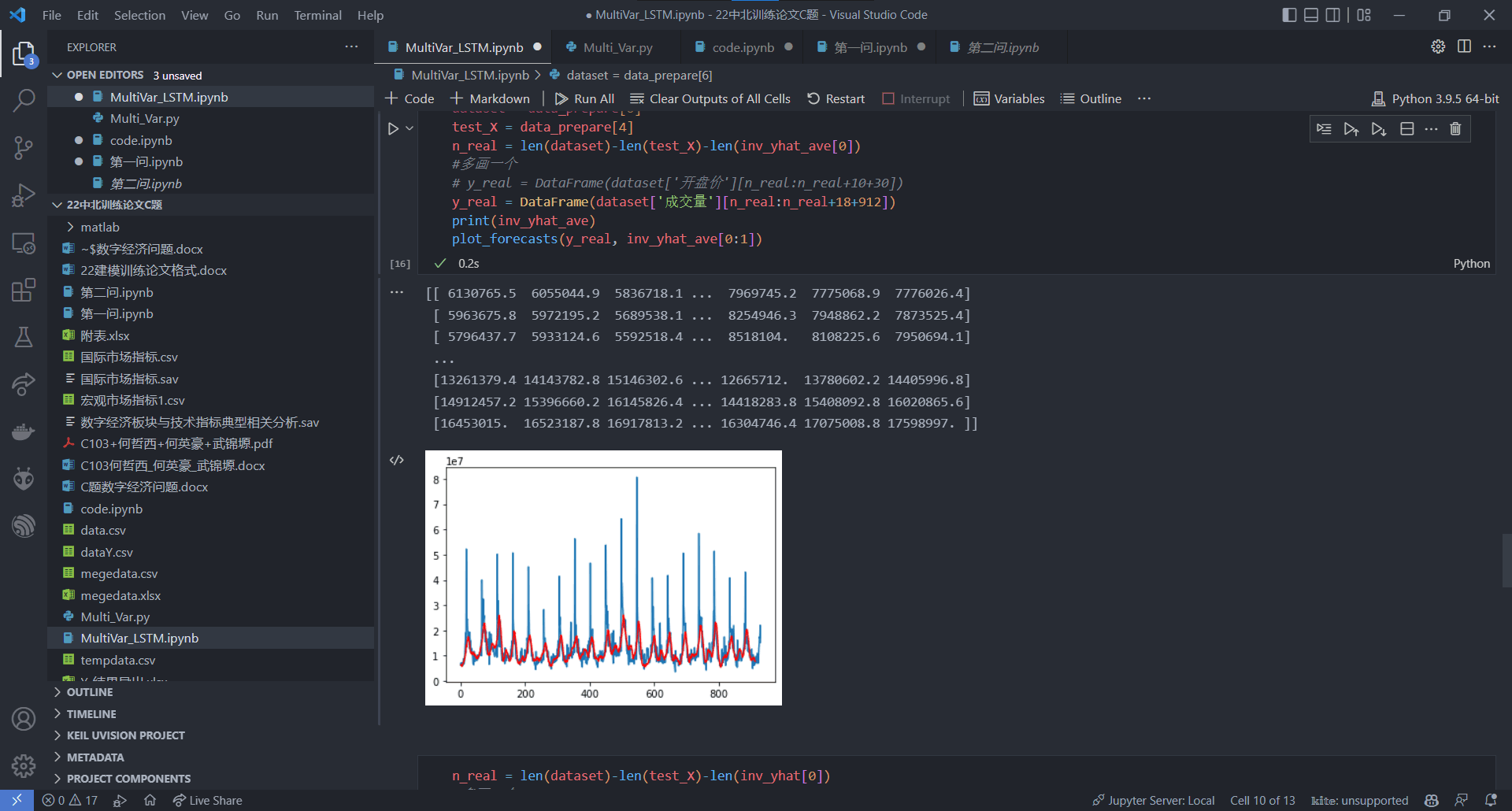 后来我尝试增加LSTM cell数量以及增大units数量,但提升都微乎其微,后来我在另一篇博客里看到了informer这个模型,对长序列预测似乎效果很不错,于是我现在想尝试用你们的repo训练试试,但是我不知道对于这种周期性波动的序列效果怎样,尤其是不知道怎样调节超参数,所以希望大佬能够给予一些指导
@haotian-liu Hi, I'm a undergraduate in North University of China and I'm working on Robomaster competition which is held by DJI,I'm a member of the vision group which is responsibile...
@DefTruth 大佬你好,就是我是一名大二学生,然后是在中北大学的robomaster战队里负责用神经网络识别装甲板实现自动瞄准,不过就是之前我用yolo系列训练出来的模型最后实际测试时得到的bbox和装甲板的轮廓并不能很好的拟合,导致后续使用pnp进行姿态解算时会有较大误差,所以我想将传统yolo的数据集格式改为用四个角点的归一化坐标,然后我看到了您这个项目,我觉得我们的应用场景和车牌检测有很大的共通之处,然后我现在的数据集格式是像这样:1 0.673029 0.373564 0.678429 0.426232 0.830433 0.401262 0.824525 0.351212,第一个数字是类别id,后面八个数字是归一化后的装甲板的四个角点坐标,然后其实现在我是参照yolov5-face这个repo来实现了关键点定位,其他一些使用网络的学校也用的这个repo,用pytorch推理的效果如下:  第五个点我还没去掉,不过在使用他提供的export.py转化为onnx时却一直有error,目前在issue下作者还没回复我,所以现在这段时间我想来尝试尝试您的这个repo,如果您能提供一些指导,我将不胜感激
@CPFLAME 大佬你好,就是我是一名大二学生,然后是在中北大学的robomaster战队里负责用神经网络识别装甲板实现自动瞄准,不过就是之前我用yolo系列训练出来的模型最后实际测试时得到的bbox和装甲板的轮廓并不能很好的拟合,导致后续使用pnp进行姿态解算时会有较大误差,所以我想将传统yolo的数据集格式改为用四个角点的归一化坐标,现在的数据集格式是像这样:1 0.673029 0.373564 0.678429 0.426232 0.830433 0.401262 0.824525 0.351212,第一个数字是类别id,后面八个数字是归一化后的装甲板的四个角点坐标,之前我使用yolov5-face已经训练出来一个可以直接定位装甲板四个角点的模型,效果如下:  然后之前也一直想尝试用centernet系列的模型来实现检测,但是由于准备比赛一直没有什么时间就没有搞,我是在您知乎的文章里看到了centerx的介绍,您的讲解方式非常有意思,而且centernet不需要后处理这一点实在太吸引我,因为之前yolo系模型转化成trt或者openvino后部署时的后处理实在写的我很烦,而且还耗时,所以我想试试用centerx实现直接对装甲板角点回归,也就是支持keypoints,我知道应该需要修改dataloader,head以及keypoints的loss,但是之前是在yolox上搞过,然后当时还在cls那个头上多搞了个1x1conv单独输出颜色类别,也就是把颜色和数字id类别解藕了,但是改完之后训练一直有些问题,所以这次我想请教一下您具体需要修改的部分,然后注意哪些东西,希望大佬能不吝赐教!
@RangiLyu 大佬,你好,就是我是一名大二学生,然后是在中北大学的robomaster战队里负责用神经网络识别装甲板实现自动瞄准,不过就是之前我用yolo系列训练出来的模型最后实际测试时得到的bbox和装甲板的轮廓并不能很好的拟合,导致后续使用pnp进行姿态解算时会有较大误差,所以我想将传统yolo的数据集格式改为用四个角点的坐标,然后我现在的数据集格式是像这样:1 0.673029 0.373564 0.678429 0.426232 0.830433 0.401262 0.824525 0.351212,第一个数字是类别id,后面八个数字是归一化后的四个角点坐标,我现在就是想用centernet来训练,我看了您仓库中给的在自定义数据集上训练的博客,我现在知道了应该是数据集应该是coco格式的,然后我就想问一下我可以直接用cvat这类工具标注后导出为coco格式然后来训练吗,这样的话我标注的时候可以使用四点标注的bbox吗?望大佬解惑
@fb029ed 大佬,你好,我想先问一下你是哈深rm战队的成员吗,我是一名大二学生,是中北大学606战队视觉组的成员,目前在队里主要负责使用神经网络检测装甲板,就是我是一名大二学生,然后是在中北大学的robomaster战队里负责用神经网络识别装甲板实现自动瞄准,不过就是之前我用yolo系列训练出来的模型最后实际测试时得到的bbox和装甲板的轮廓并不能很好的拟合,导致后续使用pnp进行姿态解算时会有较大误差,所以我现在是基于yolov5-face这个repo实现直接检测装甲板的四个角点,现在就是我之后还想使用openvino实现c++下的部署,之前我已经实现了原始yolov5使用tensorrt在c++的部署,在nano上仅有25fps左右,后来在视觉交流群里,也是哈深的一位叫陈迅的大佬用openvino实现了基于yolov5-face的四点模型的部署,nuc11使用核显可以到100多帧,不过是在python下,我之前也打算使用openvino来部署,因为我们也有一个nuc10,所以我就想能否参考您的仓库来实现,因为我的输出头里增加了四个角点的坐标,那么对于parse_yolov5()函数应该需要修改吧,现在这段时间主要由于是考试周,时间比较紧,四点模型我还没有完全改完,所以想着能不能加一下您的微信或qq之后交流一下呢?