Niels
![]()
![]()
Niels
Hey, it seems like the date format in the data was a bit too exotic to be parsed correctly. If I manually parse the timestamps during preprocessing like `data['date'] =...
Hey Noah, thanks for the pointer! How do you envision the bootstrapping to fit within the library? As a replacement for the chunking, as something to perform on each chunk...
Ah yes, I see. Instead of just splitting a dataset into non-overlapping chunks (like you've mentioned) you would take that dataset as a whole and generate chunks of a fixed...
Hey Noah, just letting you know that I've created a quick implementation of the `BootstrapChunker` for you, you can find it in the [117-bootstrap-chunker](https://github.com/NannyML/nannyml/tree/117-bootstrap-chunker) branch. It uses the `pandas.DataFrame.sample()` method...
Original data reconstruction error with `SizeBasedChunker(size=5000)`: 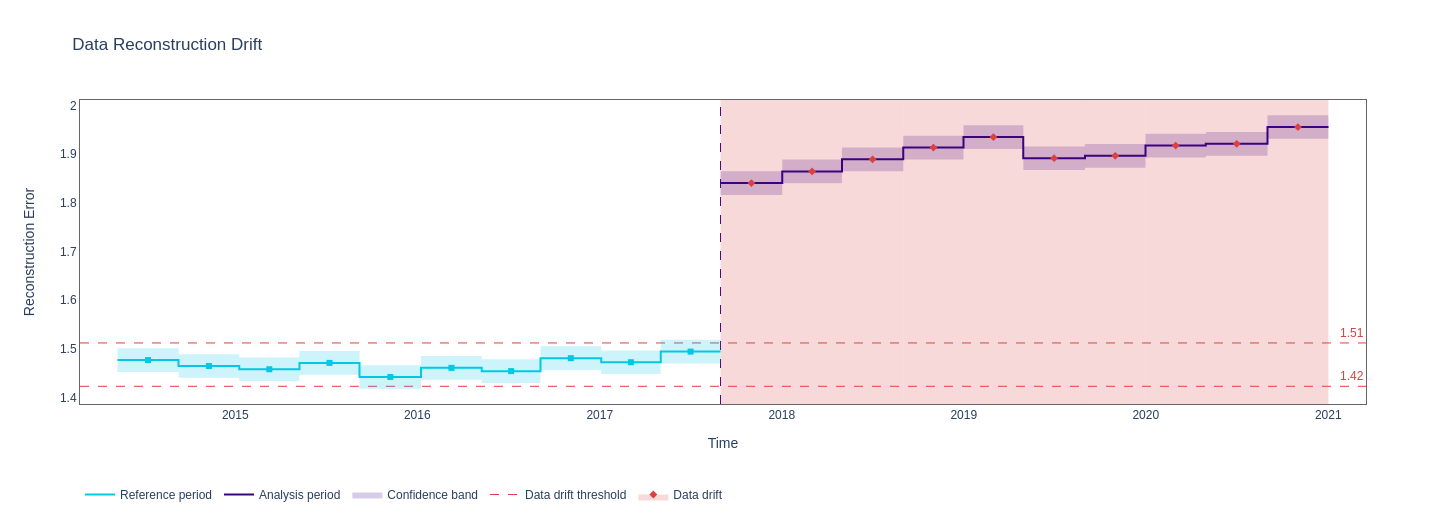 Same data and calculator, `BootstrapChunker(chunk_count=10, n=5000) ` 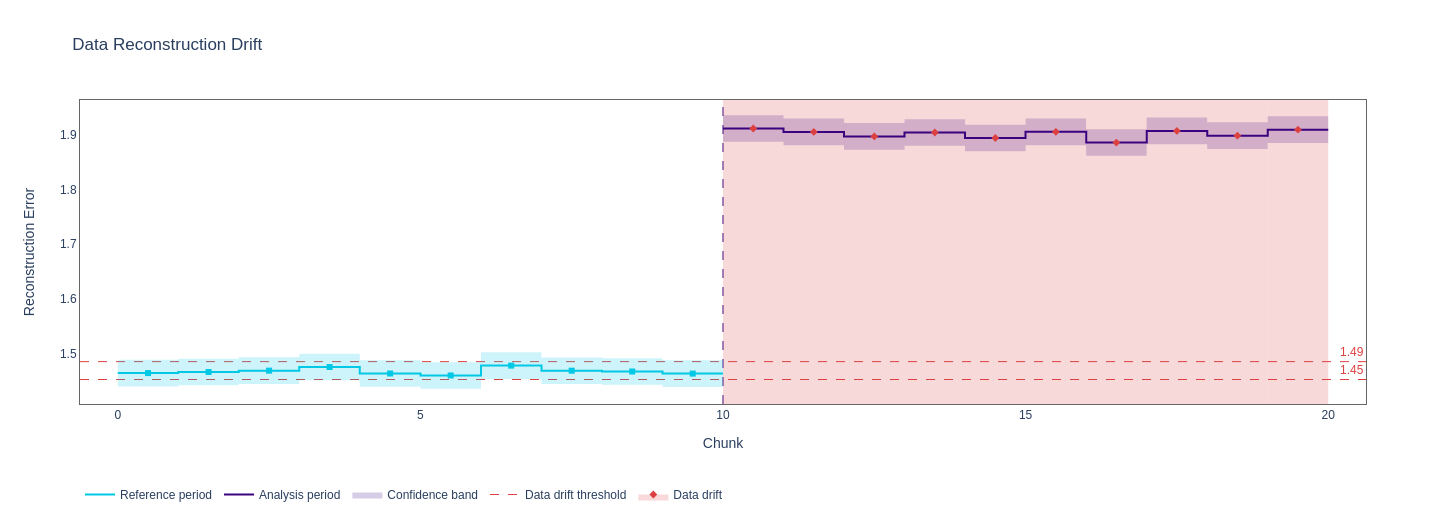 `BootstrapChunker(chunk_count=20, chunk_count=10000)` 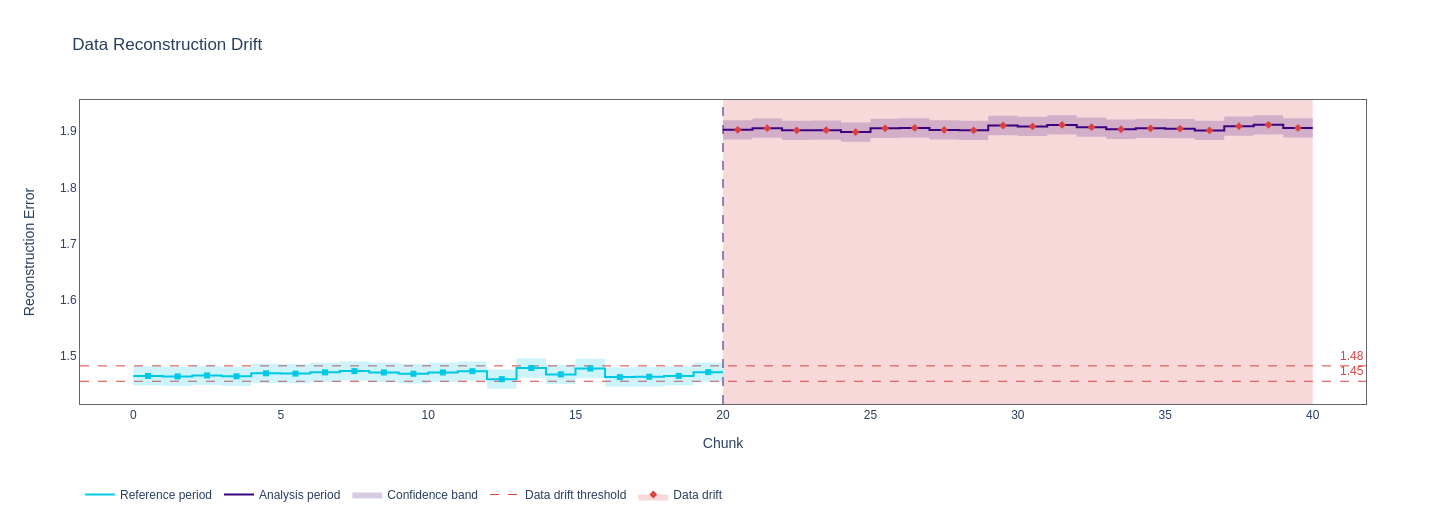 `BootstrapChunker(chunk_count=30, chunk_count=10000)` 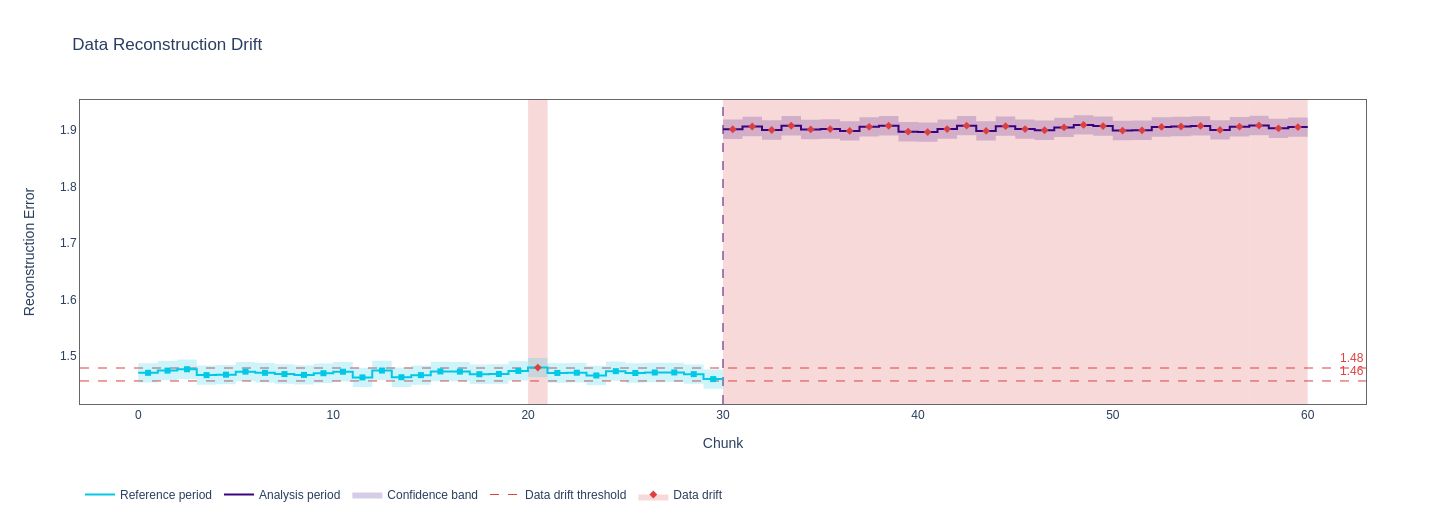
Hey Kishan, sorry for being somewhat slow to reply. ### What went wrong This exception is due to the "chunking" of the given datasets. The size of the combined reference...
Thanks for the extra information all. We'll try to include a fix in the next release, coming next week!
> Looks like the required numpy version (`>=1.14.0`) might be wrong. It seems like it should be closer to `>=1.21.0` (at least based on the current nannyml code). > >...
Hi Andrew, these functions do exist within the `nannyml.performance_estimation.confidence_based.cbpe` module, but they were kept protected up until now. I don't see any issues with making these public, people will just...
Update: we've received a great PR (#172) by @Jebq that incorporates the `numpy.historgram_bin_edges` functionality.