HuYong
分词精度问题

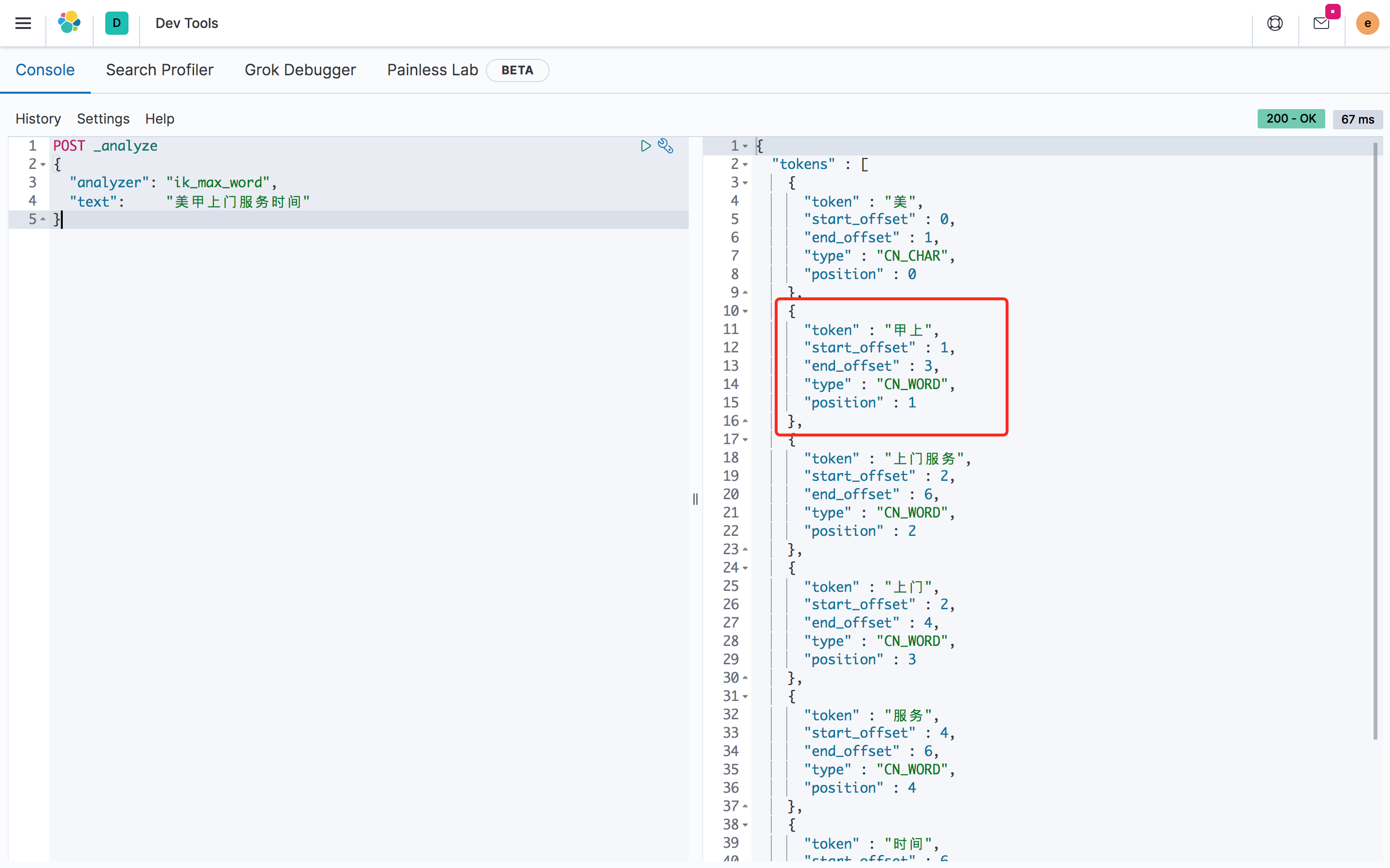 请教一下,为什么这句话中「甲上」切成了一个词? 
无法下载训练数据
RT
感谢作者开源这个很有价值的工作 在我的测试中float16, int8, int4速度上没有明显的差异,大概均为13ms/token - 15ms/token 达不到报告中的176tokens/s,相当于5.68ms/token 我的硬件环境为: cuda11.8, A100 测试code如下,dtype可以调整为"float16", "int8", "int4" ```Python tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True) model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True) model = llm.from_hf(model, tokenizer, dtype="int4") # 可以调整为"float16", "int8",...
Could you provide the benchmark of the comparison of lightseq and OpenNMT/CTranslate2 on some basic models, such as BART, T5. Thanks a lot.
ChatGLM is a popular ChatGPT-like model in Chinese: https://github.com/THUDM/ChatGLM-6B Could ct2 support ChatGLM, and speed up the inference. Thanks a lot.
在评估tokenizer的部分给出的是tokenizer自身的评估指标,比如压缩率 但是,高压缩率的tokenizer并不意味模型的效果也更好,是否能给出最终模型层面的效果? 例如:sentencepiece实验中的BLUE https://github.com/google/sentencepiece/blob/master/doc/experiments.md#english-to-japanese