lz20061213
![]()
lz20061213
这个项目剪枝方式是卷积核的数量变少
I have a small question. If we add L1 norm to all BN layers in training but don't prune the layers related to the shortcut layer, is it still works?
同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值) 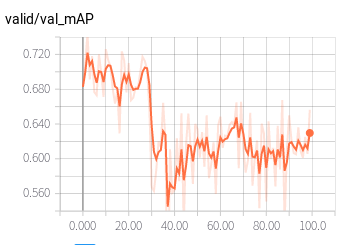
> > 同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值) > >  > > 请问你测试作者剪枝后的模型了吗,为什么感觉测试的时间并没有变少啊 对 我用的TitanXp 时间少的不多
> > > > 同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值) > > > >  > > > > > > > > > 请问你测试作者剪枝后的模型了吗,为什么感觉测试的时间并没有变少啊 > > > > > > 对 我用的TitanXp 时间少的不多...
> > > > > > 同样的问题,测试AP值较低 (颜色浅的为实际AP,深的是平滑的值) > > > > > >  > > > > > > > > > > > > > > >...
直接训练剪枝后的模型有可能会达到相似的效果
首先剩余的bias需要经过激活函数,然后跟下一层的权值相乘,之后加入mean(下一层含BN)或者bias(下一层不含BN)中
> 为什么不加入下一层(含BN)的bias,只加入到running_mean呢? BN层没有bias
> > > 为什么不加入下一层(含BN)的bias,只加入到running_mean呢? > > > > > > BN层没有bias > > BN层有两个参数,一个gamma,一个是shift,我说的bias是指shift的参数,感觉应该跟running_mean一起更新才对 我的理解是这样的: 1. 假设当前层(i)通道裁剪对应记录列表为mask, 1表示保留,0表示扔掉;当前层的shift = mask * shift + (1-mask) * shift,后面(1-mask) * shift表示剩余的shift, 记为remain_shift; 2....