venus
venus
I have error too, tritonserver r21.10 @Taka152 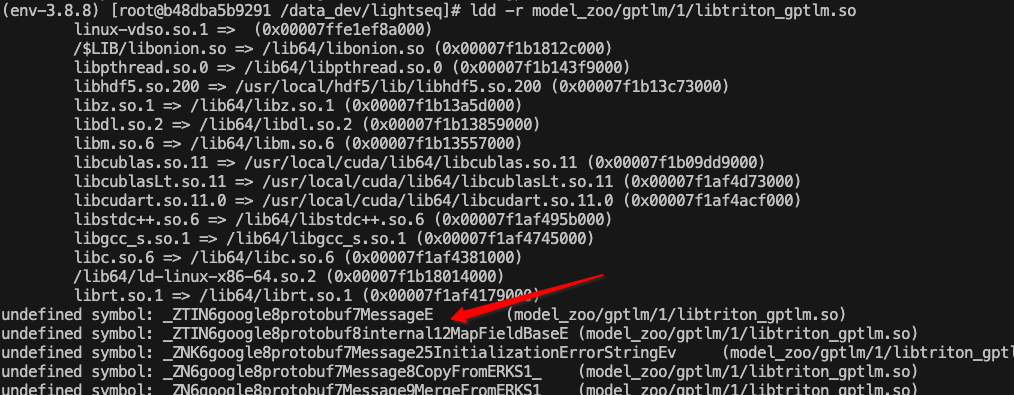
@Taka152 that seems is Protobuf problem,(I aright keep same version) cmake version 3.20.6 Protobuf version 3.20.1 I fixed this issuse, Protobuf version problem
@Taka152 更新一下,使用USE_TRITONBACKEND ON生成对应libtriton_lightseq.so文件进行load模型或者rdd -l都可以正常; 使用server/ 下的so文件仍然报undefined symbol: _ZN6nvidia15inferenceserver19GetDataTypeByteSizeENS0_8DataTypeE 错误;
just confirmed, V2.2.0 version CMakeList.txt require cuda version is 10.1 latest version require cuda version is 11.6 that means base on your version of cuda, build different .so file, right?...
can you introduct how to generated them? like gpt.pb.h ,bert.pb.h
base on https://github.com/bytedance/lightseq/tree/master/lightseq/inference/triton_backend, I built dynamic link library ,after cmake,when I do make install, then cannot find bert.pb.h (env-3.8.8) [root@bedd035bb520 /data_dev/lightseq/lightseq/inference/triton_backend/build]# make install -j 10 Consolidate compiler generated dependencies of...
> initializing bart tokenizer... creating lightseq model... Parsing hdf5: /home/sysadmin/downlaod/lightseq_models/lightseq_mbart_base.hdf5 loading 976 MB of embedding weight. Finish loading src_emb_wei from host to device loading 1073 MB of embedding weight. Finish...
### single GPU error: even If I train sd-lora or sdxl-lora using single GPU, it all have this error: sd-scripts commit ID: f8f5b1695842cce15ba14e7edfacbeee41e71a75 ### Command: python -m accelerate.commands.launch --num_cpu_threads_per_process=2 sd-scripts/train_network.py...
if I use 2 GPUs, everything is fine:  
same, my env is 2.3.1+cu12.1