kusoge
You can retry the download now, it seems to have fixed itself (at least on my end). I temporarily closed the issue on the new fork release since it's working...
It runs fine on my system. GPU RTX 3060 12GB 16GB RAM CPU Ryzen 5 5600G
Tick the CPU option, it's gonna be painfully slow though.
I managed to run the ggml-alpcca-13B model quite easily. Hopefully it will be supported soon.
When you loaded the webui you are probably on [instruct] mode.  If you click a character profile in that mode, it throws that error. Just switch to chat
What are your parameter settings? IF you set the max-new-token to 2000(default maximum-unless you changed the max if you were using the MPT model), the AI will ignore context/chat history.
Check ooba's post on reddit. He mentioned something about making it not necessary to go through command-line parameters and improve the UI experience. Perhaps, a fix should be to load...
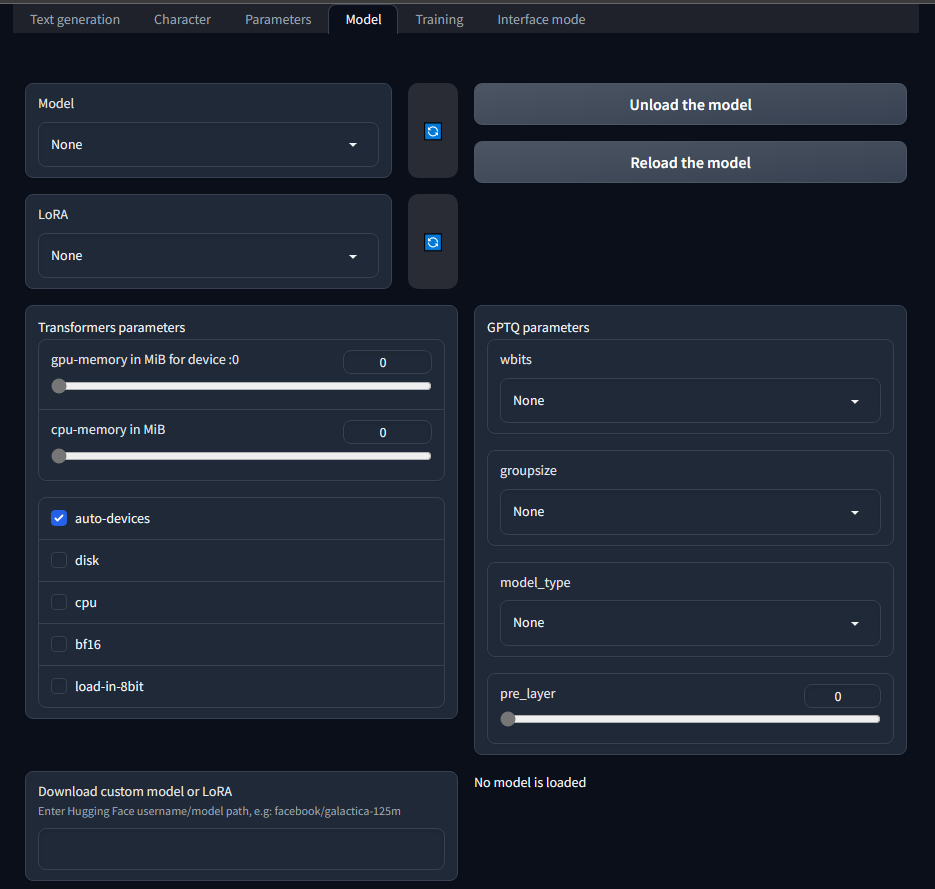 You can manually load the model now from this tab
Models that outputs gibberish stuff like that for me are: Neko-Institute_LlaMA-13B-4bit-128g TheYuriLover_llaMA-13b-pretrained-sft-do2-4bit-128g-TRITON Bradaar_toolpaca-13b-native-4bit-128g-cuda Braddar_gpt4-x-alpaca-native-4bit-128g
I'm also getting gibberish response from the newer vicuna-13b-1.1-gptq-4bit-128g model. Apparently, according to the uploader: The safetensors model file was created with the latest GPTQ code, and uses --act-order to...