Gabe Joseph
Gabe Joseph
This is awesome @rjzamora, great thinking! This seems vaguely related to https://github.com/dask/dask/issues/8361. It also makes me wonder if we could simplify/do away with the `split_out` (and maybe `split_every`?) parameters with...
I definitely think of this as a bug. Would applying standard graph optimizations to the SubgraphCallable help here? Or is the subgraph being constructed in some pathological way by Blockwise...
Great to hear, thanks @FredericOdermatt! I'm curious, did you ever try `shuffle="disk"`? This PR is primarily designed for multi-machine clusters, so on a single machine, the disk-based shuffle should work...
My intuition is that this would not be easy to do without adding complexity. In order to do it, you'd have to be able to inspect the graph of the...
> I don’t see any reason why we couldn’t implement a simpler delayed-specific optimization for this (one that doesn’t materialize the target Blockwise Layer) I'm all in favor of removing...
Sorry about that. Yeah, `client.restart` is now stricter and verifies that the restart was actually successful. I don't understand what you're doing with the socket, but presumably you're doing something...
Also, at some point soon-ish, I'm hoping to finish up and merge https://github.com/dask/distributed/pull/6427. This might break your test yet again. Currently, the `Nanny.kill` process goes: 1. Call `Worker.close` 2. If...
This is still failing frequently: https://github.com/dask/distributed/pull/6696 seems relevant? cc @graingert
Sweet, thanks @charlesbluca! How can we test this out? Seems like tests don't actually run when you just modify the GitHub actions yamls. Maybe push a spurious change to something...
In other PRs, I'm used to seeing jobs at least queued, if not running, as soon as something gets pushed. Like on https://github.com/dask/distributed/pull/6856 right now, I see: 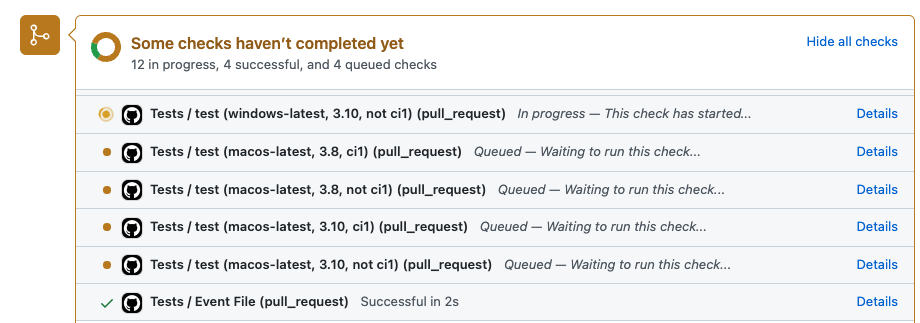 Maybe try...