frankxyy
frankxyy
> @frankxyy 您好,这个代表这个模型的输入是动态shape,在下面输入-1,3,224,224即可 > > 另外还有两个问题需要描述一下: 1、具体业务场景 2、为什么有转到Paddle部署的需求呢? > > 感谢~ 你好,我是想用paddle serving 部署 pytorch导出的onnx模型哈 请问这样的使用方式是正确的吗?
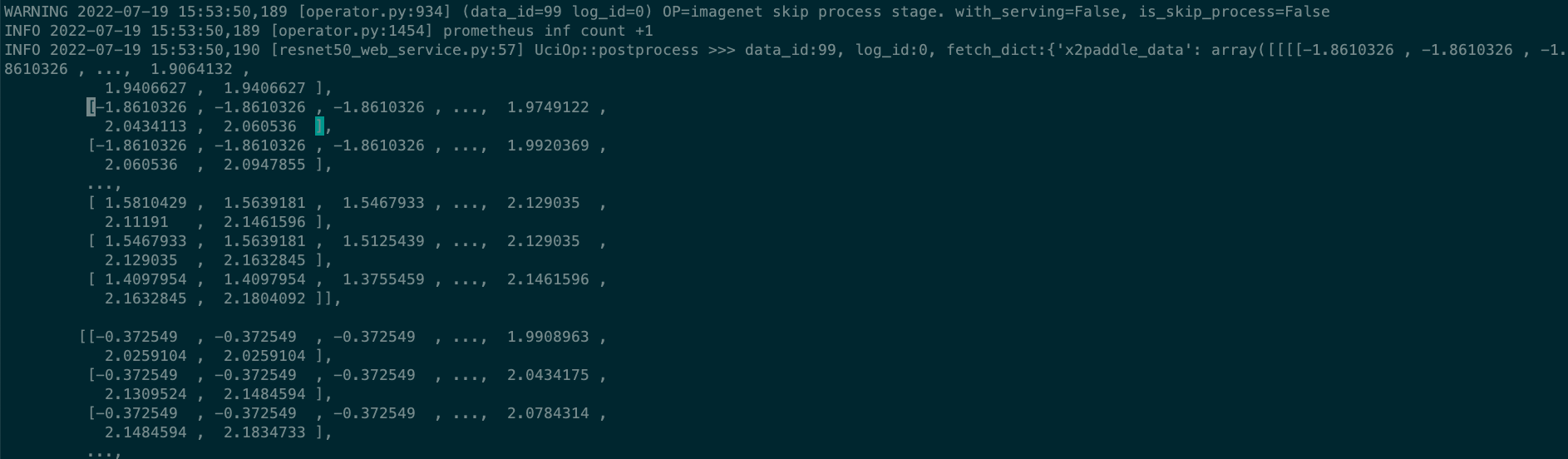 接上,onnx转pd模型,serving后发现response和request相同,请问什么原因? serving prototxt如下: 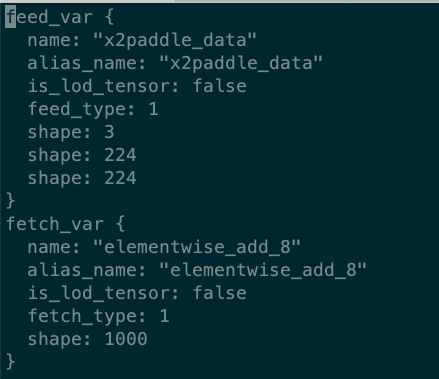
@szalpal Got it. Sorry, I will collect the background information then
hi @krishung5 ,the original libtritonserver.so works with the ensemble model containing a bls model. The version of Triton is 22.07. Other relating information I will provide in the post as...
I think i may find the reason. In the original code of triton core in rate_limiter.cc,the `instance_index` variable is not initialized, which may cause the dequeueing of payload uncertain. After...
Hello, how is the processing progress of this issue? Do I make the correct investigation?
Hi @krishung5,I checked my code and confirm that all the depended projects are all set with repo tag 22.07,and the only change I made to the triton core project is...
Hello @krishung5 , I want to know about the progress of the investigation of this issue. Thank you a lot!
@FrankLeeeee,I hot fixed this problem. I change the dns and pip install successfully.
config file: vit_pipeline.py training command: node 1: ``` TORCH_DISTRIBUTED_DEBUG=INFO NCCL_DEBUG_SUBSYS=ALL NCCL_DEBUG=INFO NCCL_SOCKET_IFNAME=bond0 cuda_visible_devices=4,5 torchrun --nproc_per_node=2 --nnodes=2 --node_rank=0 --rdzv_backend=c10d --rdzv_endpoint=172.27.231.79:29500 --rdzv_id=colossalai-default-job /home/xuyangyang/colossalai-examples/image/vision_transformer/hybrid_parallel/train_with_cifar10.py --config /home/xuyangyang/colossalai-examples/image/vision_transformer/hybrid_parallel/configs/vit_pipeline.py ``` node 2: ``` TORCH_DISTRIBUTED_DEBUG=INFO NCCL_DEBUG_SUBSYS=ALL NCCL_DEBUG=INFO...