efwfe
**I fix this error, just add the env to the docker-compose.backend.** the source code as bellow. 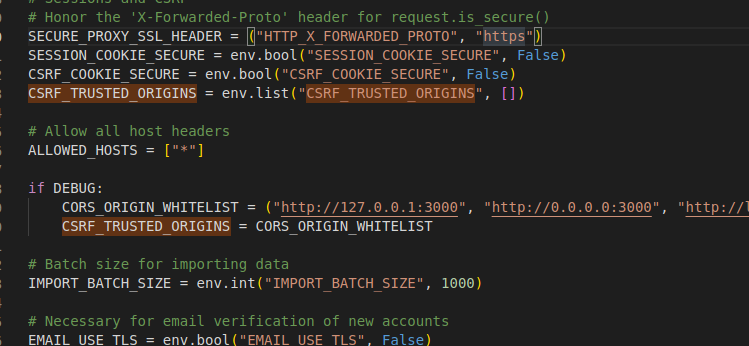 add your own server address,I deploy the server to my vm. 
> Do you still get the same error when setting a Preprocessor before selecting a model in controlnet? Still same error. Does your contolnet work well.
no problem. just the controlnet version not match base model version.
可以修改一下这个函数, utils.py里面: ```python def auto_configure_device_map(num_gpus: int) -> Dict[str, int]: # transformer.word_embeddings 占用1层 # transformer.final_layernorm 和 lm_head 占用1层 # transformer.layers 占用 28 层 # 总共30层分配到num_gpus张卡上 num_trans_layers = 28 per_gpu_layers = 30...
> > 可以修改一下这个函数, utils.py里面: > > ```python > > def auto_configure_device_map(num_gpus: int) -> Dict[str, int]: > > # transformer.word_embeddings 占用1层 > > # transformer.final_layernorm 和 lm_head 占用1层 > > #...
> > > 可以修改一下这个函数, utils.py里面: > > > ```python > > > def auto_configure_device_map(num_gpus: int) -> Dict[str, int]: > > > # transformer.word_embeddings 占用1层 > > > # transformer.final_layernorm 和...
In "NVIDIA L4 24G", "--disable-cuda-malloc" is also required ( Driver Version: 535.171.04)
That's could be possible, but you have to change source code to use shared memory or some memory database like redis or memocache. I dont't think it's a good idea...
A10G 24G works fine with `batch size = 8`
> Great — based on my Stack trace, what am I doing wrong? > […](#) > On Thu, 21 Mar 2024 at 13:30, efwfe ***@***.***> wrote: A10G 24G works fine...