burkliu
burkliu

pip install kaldifeat Looking in indexes: http://mirrors.cloud.tencent.com/pypi/simple Collecting kaldifeat Using cached http://mirrors.cloud.tencent.com/pypi/packages/2d/7b/0a5c9254de6a62cdca7bea829bd8d5d646e18508d34f9214f048ee003fed/kaldifeat-1.17.tar.gz (477 kB) Preparing metadata (setup.py) ... done Building wheels for collected packages: kaldifeat Building wheel for kaldifeat (setup.py)...
In locally sync mode, the GPU utilization is unstable (sometime 100%, sometime 0%), and the average GPU utilization is about 60%. I think this question may caused by IO when...
https://github.com/tensorflow/lingvo/blob/2d05484a7d5d73db23f8a4b47d6d729b5e01fa6a/lingvo/tasks/asr/decoder.py#L1059 i found that ComputePredictionDynamic is too slow for schedule sampling, so i tried to add schedule sampling in the cell function RnnStep but failed following is my code ```...
`2020-08-17T03:05:45.568884032Z File "neural_sp/neural_sp/models/seq2seq/decoders/transformer.py", line 968, in beam_search 2020-08-17T03:05:45.568887299Z rightmost_frame = max(0, aws_last_success[0, :, 0].nonzero()[:, -1].max().item()) + 1 2020-08-17T03:05:45.568890475Z RuntimeError: invalid argument 1: tensor must have one dimension at /pytorch/aten/src/TH/generic/THTensorEvenMoreMath.cpp:590` I...
hello! I opened the event output using tensorboard, but I couldn't find the attention summary of decoder, how should I do?
作者你好,我是eve手游玩家,程序员,目前基于python开发了一个机器学习算法,可以自动计算优化挖取目标成品材料所需要的原矿种类以及数量,有意请与我联系,QQ616310753  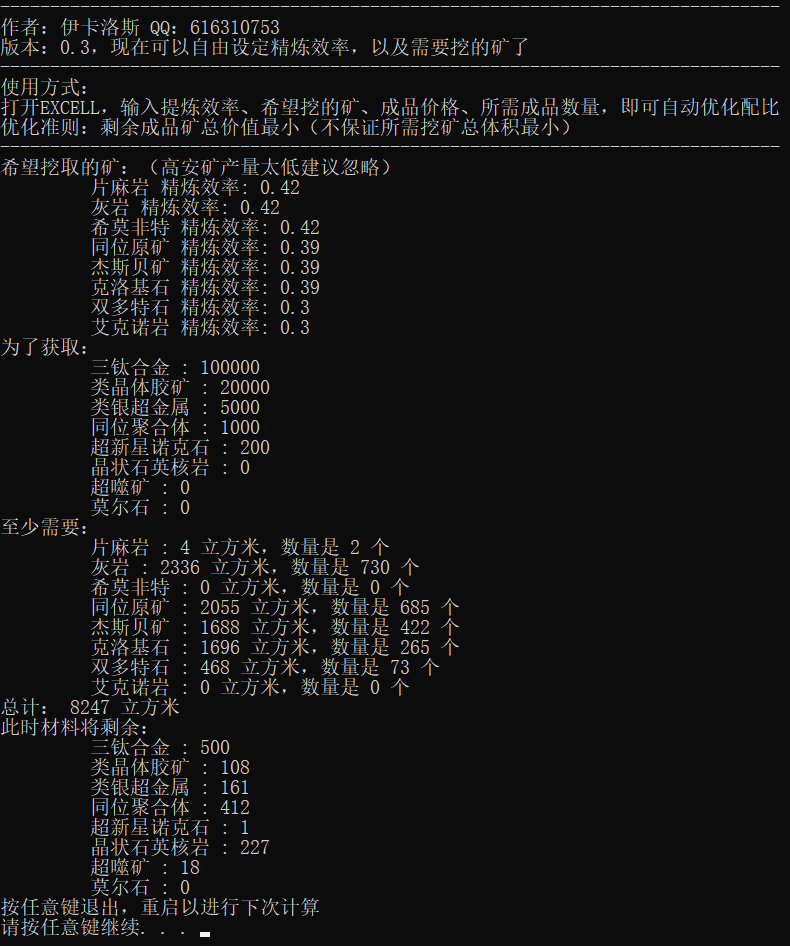
Hello guys, I wrote a streaming inference pipeline in Python for this project, including torch jit script, int8 dynamic quantization, and streaming interface for the audio encoder and decoder (style...
https://github.com/ubisoft/ubisoft-laforge-ZeroEGGS/blob/4992d9ab5e28bc4bb13219a598906562f5786448/ZEGGS/modules.py#L461C5-L481 consider relace with ``` def forward(self, x): """ Forward function of Positional Encoding: x = (B, N) -- Long or Int tensor """ # initialize tensor nb_frames_max = torch.max(torch.cumsum(x,...
I tried to replicate your experiment on lingvo, and I tried to keep everything you mentioned same. However, I can only get minimum WER of 25% upon all my experiment....
#379 问题2的解决方案 flowmatching中的z和mu,跨chunk时对于每个index不是定值,是导致衔接处频谱模糊的因素之一(本质是flow的attention context问题,无解。需要重训模型+context cache,非常复杂) 有益效果: 1、可以改善衔接处频谱模糊、发音不清晰问题 2、可以改善衔接处断音问题 3、可以改善音量突变或音量异常问题 图中是flow的tts_mel输出,用于对比上下文及频谱模糊的问题 大图1列:不带cache;2列:带cache 小图左:前chunk最后34;中:(前+后)/2;右:后chunk开头34 可以发现带cache的,tts_mel频谱更清晰 需要注意的是,对于zeroshot,由于带了prompt输入,所以这部分的cache也需要额外考虑 备注: 1、由于后续的mel fade、hifigan cache、speech fade的挽救,该项虽然更本质,但最终听感提升概率较小 2、对于默认配置,断音出现周期为2s,若此时刻恰好没有发音,就难以发现区别,因此不保证每条case必然出现至少一处改善 3、flow matching 的输入Z和MU使用cache结果是有意义的。首先可以减少随机性、提升结果稳定性;其次未来做causal同样需要使用此cache,是可以复用的 已测有效的用例: SFT `cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-SFT') cosyvoice.inference_sft('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '中文女',...