andylee
andylee
FastWordQuery提供了两个网站的API,dreye和eudict,这两个网站的数据我感觉比较好,可用度比较高。但是大批量的跑这两个网站很慢,而且基本不可能成功,一两百次就会被网站ban掉。于是我就花了一段时间把两个网站上单词查询的html结果本地保存下来,大概三万四千左右的单词量,应该满足大部分的制卡需求,然后按照各自网站的目录结构,在我本地搭建了nginx,然后将FastWordQuery的请求地址都改成http://127.0.0.1/.....; 大大加快了批处理速度,经过多次跑批测试,效果很完美。 ng目录,整个包压缩后八百多兆,不知道怎么分享出来 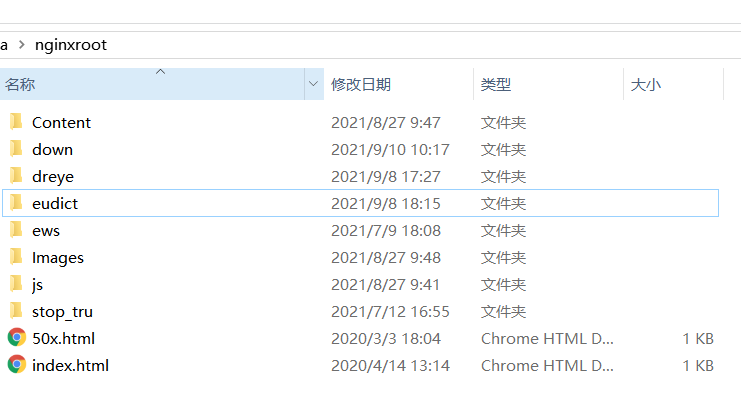 网站请求演示 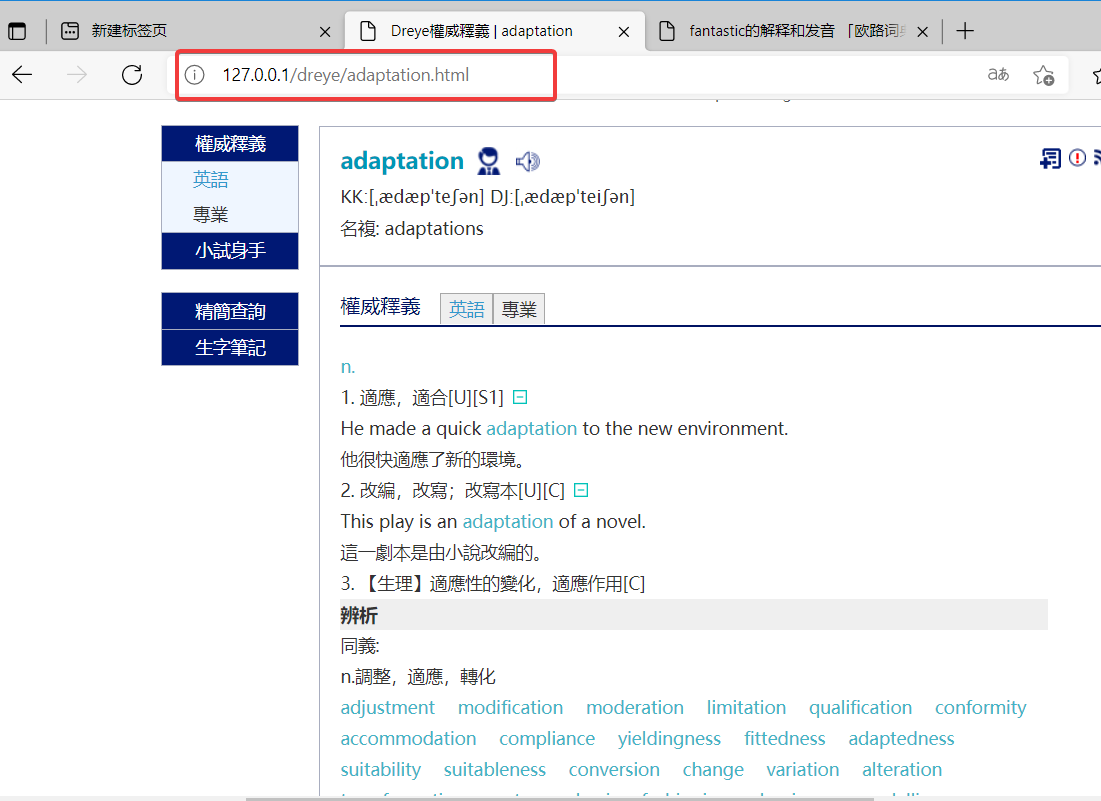 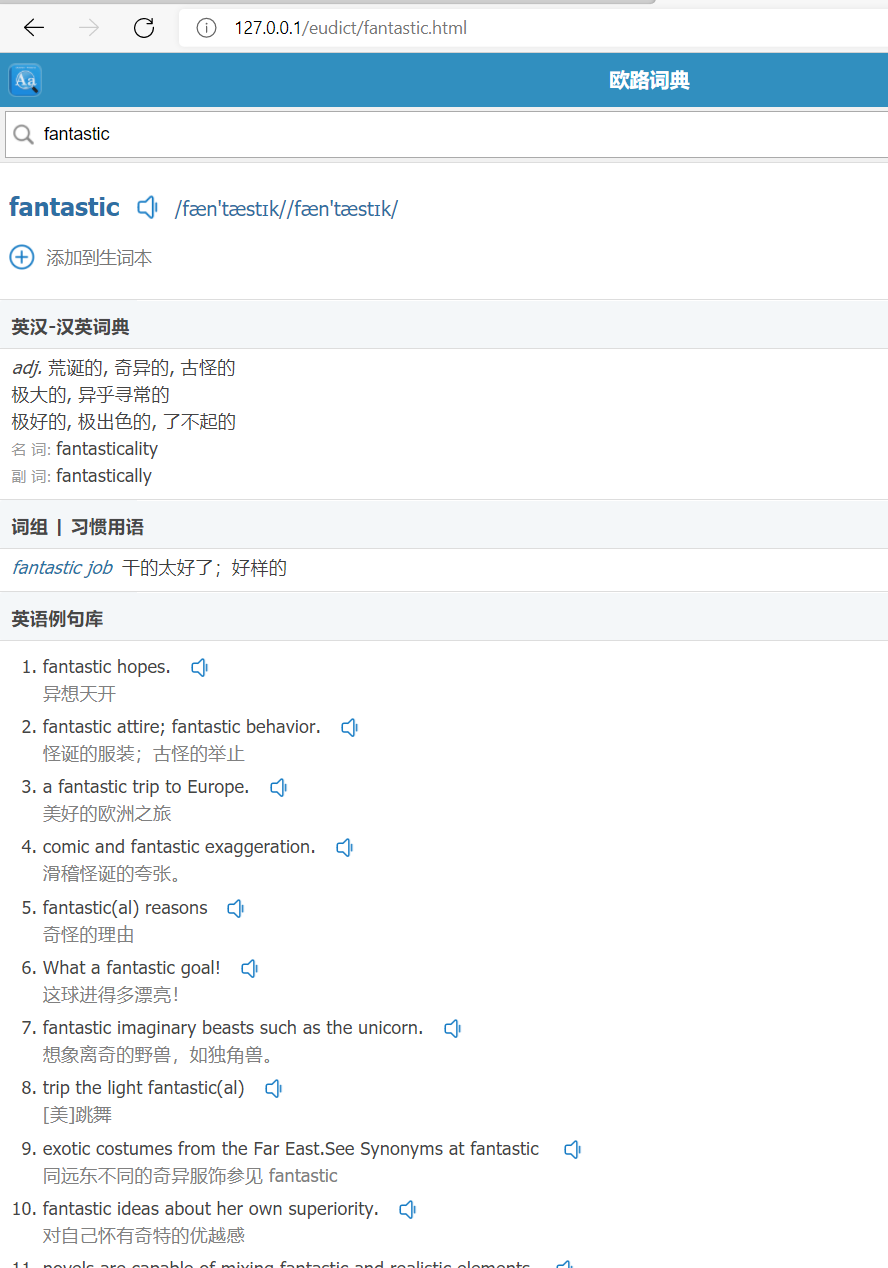 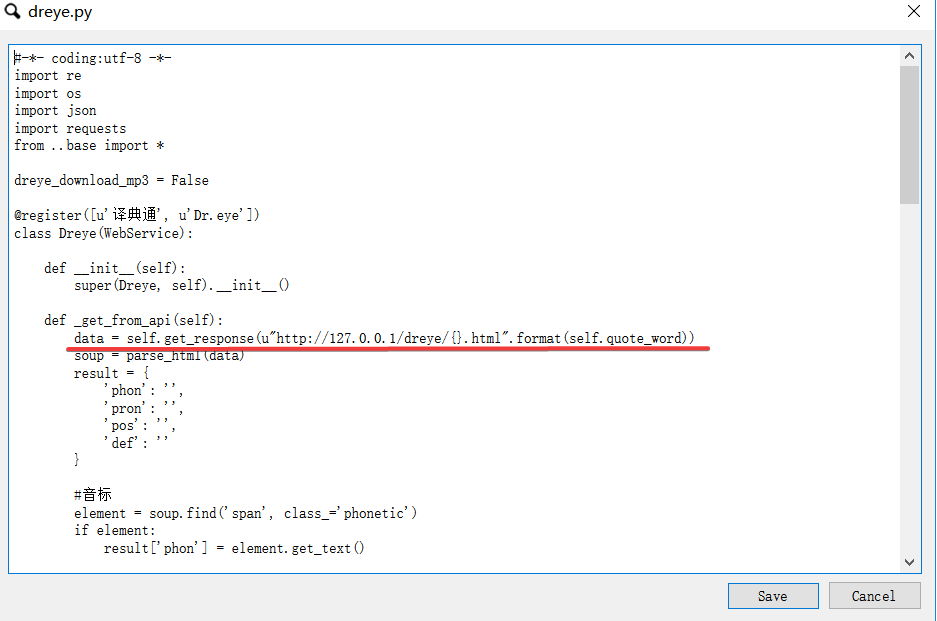 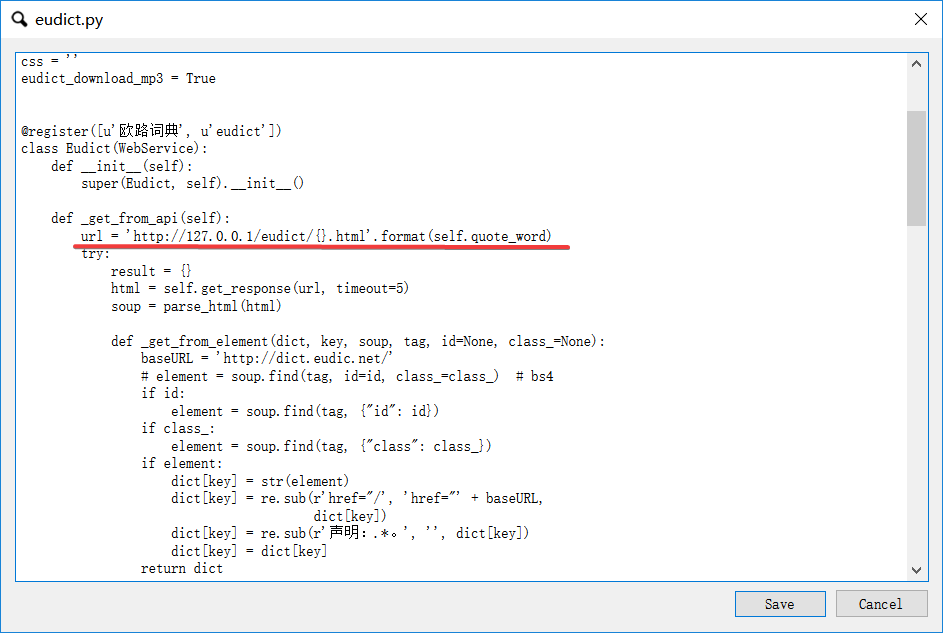
8000左右的卡片就会占用7G的内存,不知道是anki浏览器的问题还是FastWordQuery在处理过程中没有清理内存,跑完,关掉Anki浏览器就会释放内存。 
更新两处代码

## 1.有道词典释义过滤"人名"释义, 人名释义在背诵过程中是个不好的干扰因素,于是加上了过滤代码 ```python explan =[] for item in doc.findall(".//custom-translation/translation/content"): if not re.match('.*人名', item.text): explan.append(item.text) explains = ''.join([item for item in explan]) ``` ```txt {'phonetic': 'UK [ˈkɒnstənt] US [ˈkɑːnstənt]', 'us_phonetic':...
去除"人名"释义
使用fastwordquery将词典导入anki进行记忆时发现很多高频单词都有"人名"释义,在过去半年背单词的过程中这个"人名"解释在记忆过程中是个很不好的干扰因素,在记忆过程中想过滤人名再导入  我基于原始文件concise-bing.mdx导出一份txt,并使用正则去除人名释义之后,再使用MdxBuilder3.0和4.0进行再压制都失败 `.*\n.*n.\n.*.*人名.*\n.*\n` 