Qing
Qing
请问有什么通用式的检测模型吗?我看到原论文里main body detection部分用的是类似YOLO的模型结构,在任务里把所有物体都视为前景。这样的模型应该是基于语义判断检测物体位置,对于不在原数据集里面的物体类别模型应该是检测不出来的吧。
在m1的macos 13.4.1上无法使用,显示 应用程序“合成视频.app”无法打开。
其实我比较疑惑的是图中的similarity preserving loss体现在配置文件或者代码的哪一部分? 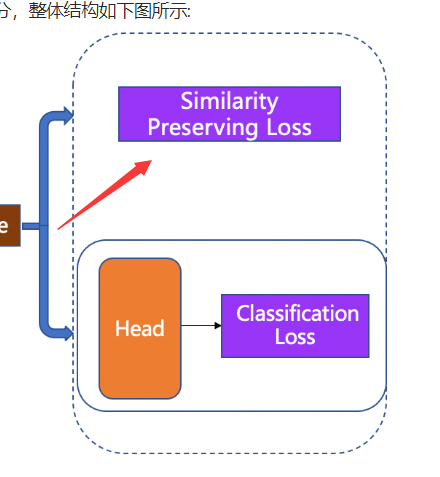
> https://github.com/jyeric/BBDown/actions/runs/7883215503/artifacts/1240726625 先去actions下载一个老版本的BBDown.exe,然后正常登录,得到cookie,把文件放到和ffmpeg和最新的BBdown一起,然后就可以去下载了 有用