USBhost
USBhost
> @USBhost `For warm up steps that should only apply to constant with warm up scheduler. Iirc.` 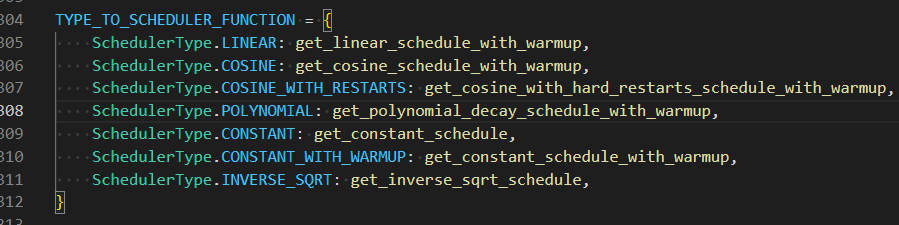 > > All schedulers other than `constant` support a warmup. (inverse_sqrt does...
~~https://github.com/kohya-ss/sd-scripts/blob/main/library/train_util.py#L2451 valid example? AdamW8bit would be nice to have. It will save some vram but idk how much.~~ Forgot iirc that broke after bnb 0.35.0 for SD at lest. edit:...
So I have been testing this pull and I am running into some issues. ``` export CUDA_VISIBLE_DEVICES=0; python server.py --listen --model llama-13b --load-in-8bit bin /UI/text-generation-webui/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so Loading llama-13b... Loading checkpoint shards:...
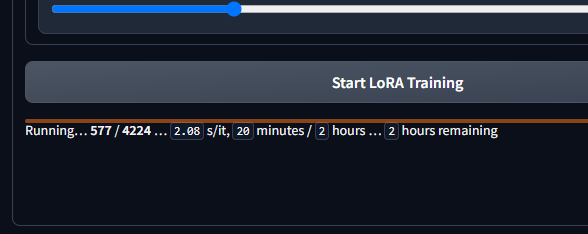 Then I interrupt it. 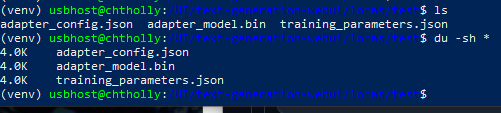 When It does not error out do to float division by zero error, it saves? but for a 32 rank is 4k adapter_model.bin size...
This is what I'm talking about, something's not right. @mcmonkey4eva 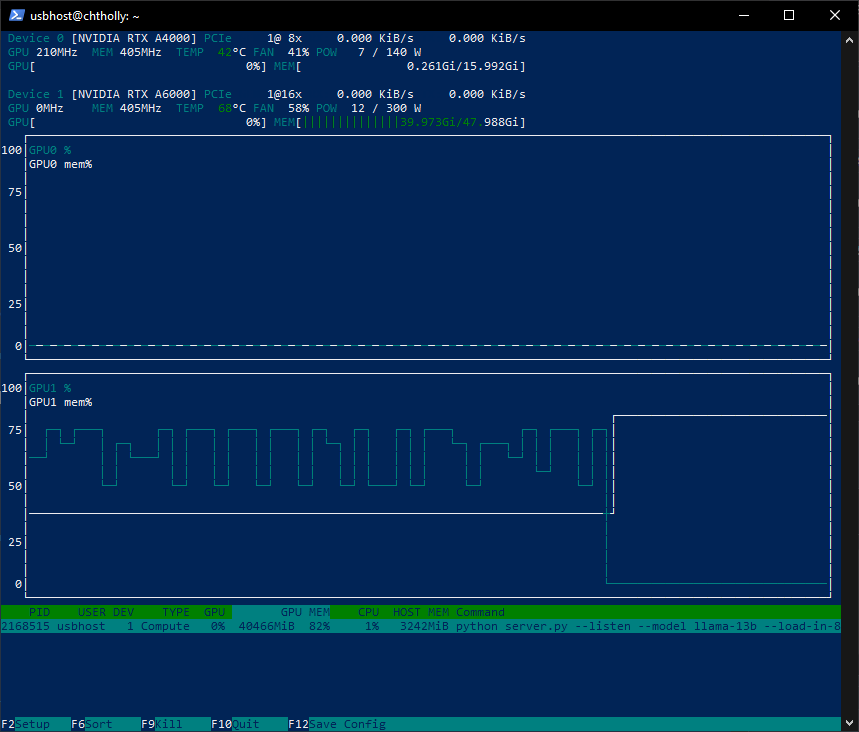 ``` export CUDA_VISIBLE_DEVICES=0; python server.py --listen --model llama-13b --load-in-8bit bin /UI/text-generation-webui/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so Loading llama-13b... Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:12
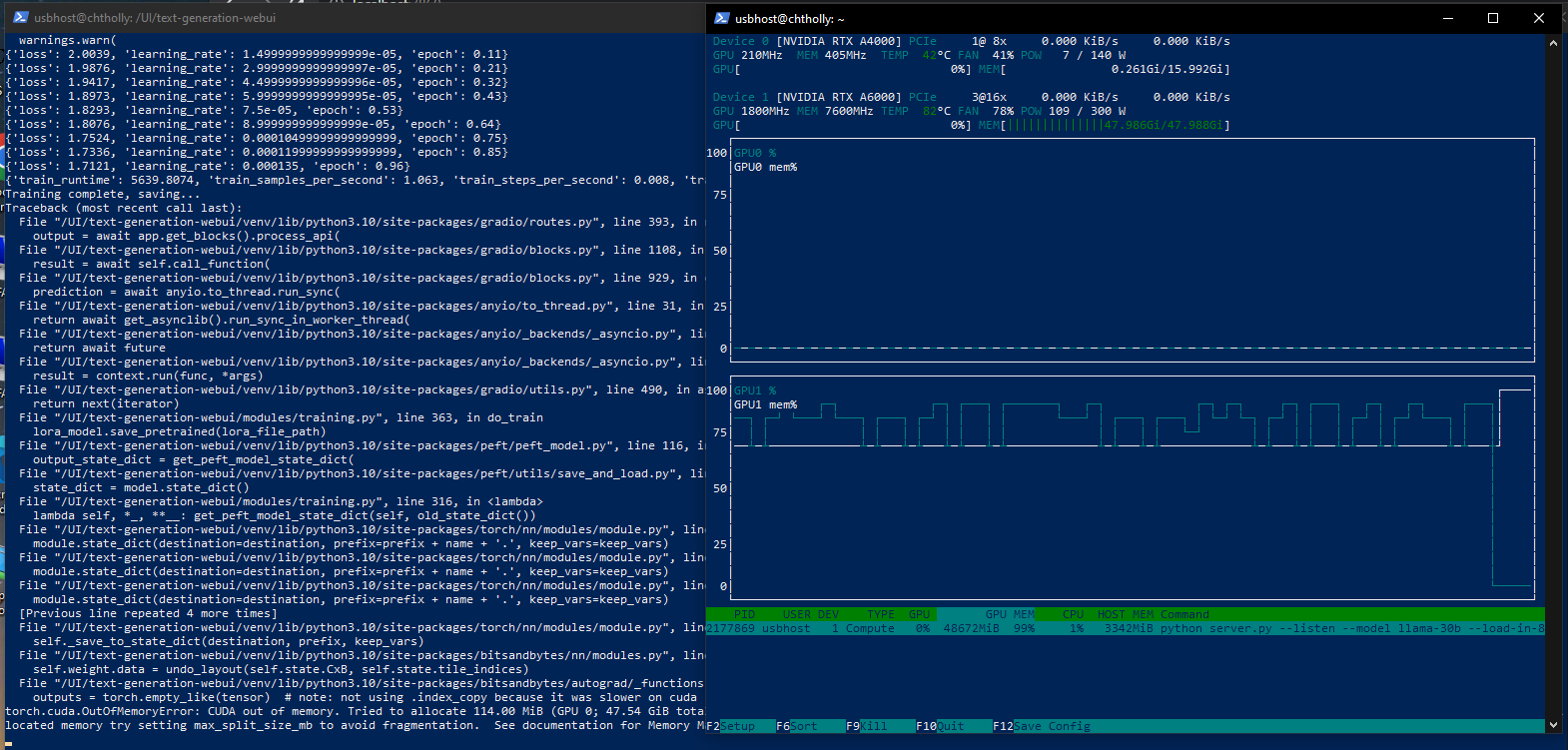 I oom training 30b because the vram jumps 2x like on 13b from what it takes to train. again stock/default settings but I changed the epoch to 1.
Did you see any VRAM issues? Could peft have caused it as well?
I can confirm going back to 0.37.2 fixed my vram jump.
https://github.com/TimDettmers/bitsandbytes/issues/324 Finally got reported to bitsandbytes
"Transformers bump" commit ruins gpt4-x-alpaca if using an RTX3090: model loads, but talks gibberish
@thot-experiment well currently ooba is broken for whatever reason. 