SuperMaximus1984
SuperMaximus1984

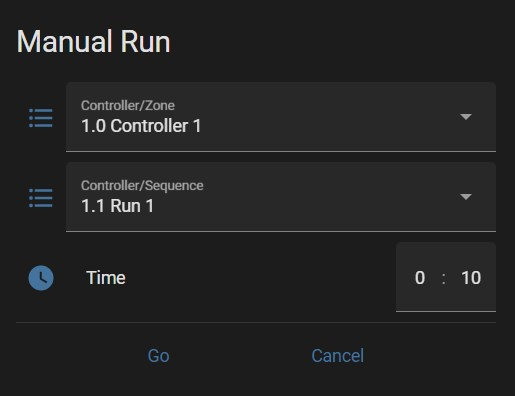 Example is above. Setting time in Manual Run like 0:10 results in 00:01:00 (1 minute). What is the proper way to set a manual run for an exact period...
I have the following response in Terminal when launch Lama-Cleaner: ``` flaskwebgui - [INFO] - Opening browser at http://127.0.0.1:59494 flaskwebgui - [INFO] - * Running on http://127.0.0.1:59494/ (Press CTRL+C to...
Changing 'run_interval=120' to any other figure does not impact polling interval. It remains at default figure 30 seconds. I need to make it 10 seconds. How? Should I recreate containers,...
I cloned the repo, downloaded the weights file `yolow-v8_l_clipv2_frozen_t2iv2_bn_o365_goldg_pretrain.pth` But when I attempt to run the demo, I get this: ``` D:\Python Stuff\yolo-world>python demo.py configs/pretrain/yolo_world_l_dual_vlpan_vlpan_l2norm_2e-3_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py yolow-v8_l_clipv2_frozen_t2iv2_bn_o365_goldg_pretrain.pth 2024-02-15 18:53:13.530020: W tensorflow/stream_executor/platform/default/dso_loader.cc:64]...
### Describe the problem you are having **No frames have been received, check error logs** appears periodically in Frigate's Web Interface Restart of Frigate may temporarily help with some cameras,...
Trying to run Gradio demo with: `python demo.py configs/pretrain/yolo_world_v2_l_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py yolow-v8_l_clipv2_frozen_t2iv2_bn_o365_goldg_pretrain.pth` Receiving this error. I have mmyolo 0.6.0 installed, mmdet 3.0.0 ``` 03/04 12:32:52 - mmengine - INFO - Load checkpoint...
Hi! Is there any instrumnet to force HA to refresh Gauges in mobile app? Obsolete data remains (sensor figures) on gauges, only after app closing / reopening again the gauge...
When I run `nvidia-smi` I see only 1st GPU is utilized. How do I run SadTalker using all 4xGPU? Thanks!
When I run `InstructPix2Pix_cuda:0` I receive an error `RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.HalfTensor) should be the same` Whenver I run it `InstructPix2Pix_cpu` everything works well, but slow....
Please help to resolve this, what can it be? ``` [Step 0] Number of frames available for inference: 1231 [Step 1] Landmarks Extraction in Video. Downloading: "https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth" to /root/ .cache/torch/hub/checkpoints/s3fd-619a316812.pth...