zhoulei
zhoulei
> > 请问为何在13B的时候将位置编码从ROPE改为Alibi了。如果从长度外推的角度来考虑,我们最近看论文Rope通过插值也能做到很好的长度外推,请问改成Alibi是基于其他的一些考虑吗?谢谢~ > > 实际上,Alibi位置编码也具备RoPe的[位置插值](https://arxiv.org/pdf/2306.15595.pdf)特性,以下是Baichuan-13B-Chat在shareGPT-zh 1w token以上的样本做的实验。可以看到,插值的效果是优于外推的,并且插值并没有微调。 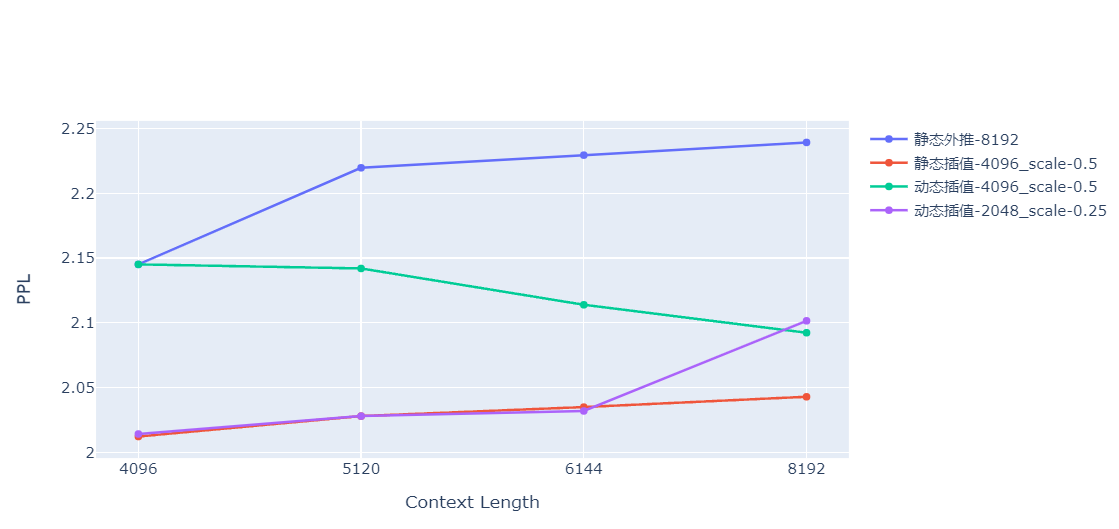 > > 也可以看到,ALiBi的外推能力在本测试集上是优于RoPe的,之前的7b模型在8192的点为上PPL是34+,而这里是2.24。 > > 图中还有个有趣的实验,就是插值是按静态插值(按固定最大长度计算缩放比例)和动态插值(按当前文本长度计算缩放比例)。如果这个实验靠谱,可能会得出几个猜想结论: > > 1. 想办法把超长的推理文本的位置编码压缩到模型训练的最大长度之内,模型的表现就会变好。 > 2. 在1.的基础上,统计SFT数据token的长度分布,将推理文本token长度压缩到该分布密度最高的长度上,模型表现最佳。 > > 以上结论和猜想仅供参考,实践需要自己根据自己的数据做测试。 这里Alibi静动态插值的code方便share吗