ChenYang He
ChenYang He

现在fate编排一个dsl、首先是reader、然后需要接一个datatransform(也就是以前的dataio)、然后再接其他的一些算法组件 其中datatransform这个组件主要就是做一些数据预处理、对数据做一些不同的预处理功能、类似定义标签列、指定标签列类型、指定数据分隔符等等 但是我测试了下、如果dsl中,reader组件后面不接datatransform、直接接类似lr这个算法组件、会直接报错,报错如下: 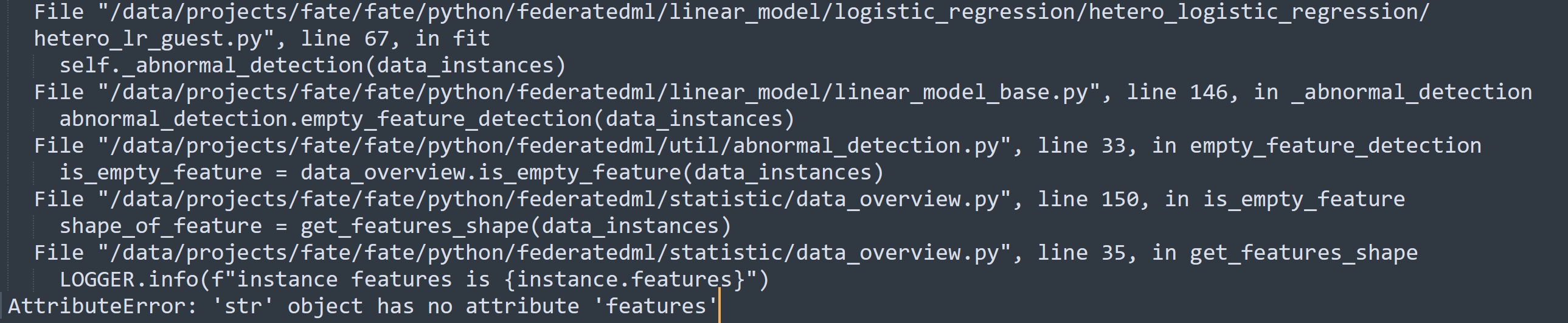 报错的原因在于数据类型不对、因为datatransform里有一个操作、就是会将从reader中读到的数据、转换成federatedml.feature.instance.Instance这样一个数据结构、只要执行了这个操作、dsl中后面的算法组件如lr就可以执行成功,如下图:  但是 “将从reader中读到的数据、转换成federatedml.feature.instance.Instance这样一个数据结构” 这个转换操作、是datatransform里面的一个必做操作、就是说即使datatransform组件暴露出来的任何参数用户都不配置、也会执行将reader读出来的数据转换为federatedml.feature.instance.Instance这样一个数据结构的操作 那么为啥不考虑将这个:“将reader读出来的数据转换为federatedml.feature.instance.Instance这样一个数据结构” 的操作做到reader里面呢? 这样的话,如果我不想做任何数据预处理操作、即使是指定标签值(y列)我都不做,那么我可以直接配置由reader -> intersection -> lr这样一个dsl执行成功一个训练,而不是必须要配置一个 reader -> datatransfrom -> intersection -> lr这样一个dsl的同时datatransform里面的参数却一个都不配置,这个情况下,如果datatransform一个参数我都不配置但是还必须在dsl中配置一个datatransfrom、就有点让建模人员感觉有点奇怪 补充: datatransform这个组件对于建模人员来说,只应该关注一些数据预处理的操作、但是这个组件里面的类型转换操作应该是建模人员不关心的、但是现在datatransform里面的数据转换操作却造成了建模人员必须去配置一个datatransform,所以我的问题集中在、datatransform组件内部的类型转换动作是不是太强制了?如果建模人员准备的训练数据很好、不需要做数据预处理、但是却还要必须配置datatransform这个组件、这等于是把建模人员不关心的fate内部数据结构的转换暴露给建模人员、所以是不是可以把这里面的转换操作移动出datatransform组件中?
**System information** - FATE Flow version (use command: python fate_flow_server.py --version): 1.8 - Python version (use command: python --version): 3.6.9 - Are you willing to contribute it (yes/no): yes **Describe...
版本: kuscia:0.13.0b0 描述: 在两台linux虚拟机上分别各部署了一套allinone的环境,其中一台(作为发起方)的io性能数据如下: 在画布页面提交一次PSI任务出现报错,创建容器失败: 查询后台日志,kuscia日志如下: containerd日志如下: 个人分析: 1. 当前环境磁盘IO性能较差 2. extract layer... 报错触发容器创建失败,当 containerd 在拉取/解压镜像层时遇到 context deadline exceeded 报错,说明解压或下载过程超时,导致容器创建流程异常终止。 3. 失败后触发清理机制,containerd 检测到创建失败后,会尝试清理相关资源,包括临时的容器、网络、镜像层等。你日志中有 "apply failure, attempting cleanup" 这样的信息。 4. 清理不彻底或延迟,由于...
#478 验证截图如下:
错误较为明显,原函数实现及引用均已修改
错误较为明显
1. GraphBuilder中的node2inputs定义为局部变量使用即可,方法执行结束立即回收,满足最小可见性原则的同时无需GC时随对象实例回收,减少对象长期持有的内存 2. 其余修改中通过Spring注入的不可变对象增加final修饰,防止后续维护时意外修改字段引用,保护对象完整性
多处代码中分别出现随意的数组预分配处理(有的按照0,有的按照.size()取大小),较为不统一,当前修复采用性能较高的数组预分配同size()处理,理由见如下代码分析: 预分配同样大小数组可直接调用jvm实现的native方法system.arraycopy,可进行性能提升; 给0值则需要newInstance一个对象后再调用native方法。
ValidationUtil :每次调用都获取新 Validator 实例,Validator虽是线程安全的,但频繁创建影响性能 CloudLogServiceFactory :无需多次重复调用getter方法 HttpUtils:完善客户端读写超时、IpFilterUtil对应Bean单例初始化
1. 原实现存在资源泄露风险,使用try-with-resources管理InputStream/OutputStream,100%避免资源泄漏 2. 空数据处理中,使用StandardCharsets.UTF_8,跨平台行为一致以避免中文等特殊字符乱码 3. 调整缓冲区大小,1kb -> 8kb,减少系统调用次数提升传输效率 4. 合理进行响应体设置,对正常数据和空数据均正确设置Content-Length 5. 错误日志记录请求关键参数(nodeId, domainDataId)和完整堆栈 6. 优化异常处理,单独捕获IOException,区分IO错误和系统错误 7. 流结束判断改用!= -1严格判断EOF,参见[Returns the number of bytes actually read, or -1 if the end of...