Luffy
Luffy


`mean, logstd = tf.split(axis=len(flat.shape)-1, num_or_size_splits=2, value=flat)` Why is this problem?
windows下使用 tf.keras,tf== 2.4.0 运行 task_iflytek_gradient_penalty 的例子 当调用 search_layer 函数遇到错误:'Tensor' object has no attribute '_keras_history' 后来发现是 _keras_history 是keras tensor特有的属性,tf tensor 没有 于是改成如下的方式:  能跑起来,但请问苏神这种方法是否也可行,感谢苏神
苏神中午好! 最近clone了您的代码, 准备从零开始感受一下BERT和 如今如此众多基于BERT变化或改进的模型 之间千丝万缕般的联系和惊为天人的设计思想。 然而进行的并不顺利,所以才来向您请教! 关于BERT的输入问题,BERT论文中提及应该是 token,segment,position。 token 是词句映射输入 segment 标记不同句子,是做nsp任务所需要 position 应该是解决做selfattention时没有词句位置信息的问题 但是在bert4keras中只有前两者输入,并没有position的信息,后来看了源码才知道是在内部做了处理,所以不需要。 关于 PositionEmbedding 的实现部分没有看的很懂,以及 merge_mode 的参数,还希望苏神能解惑一下,谢谢苏神!!!
My training images: 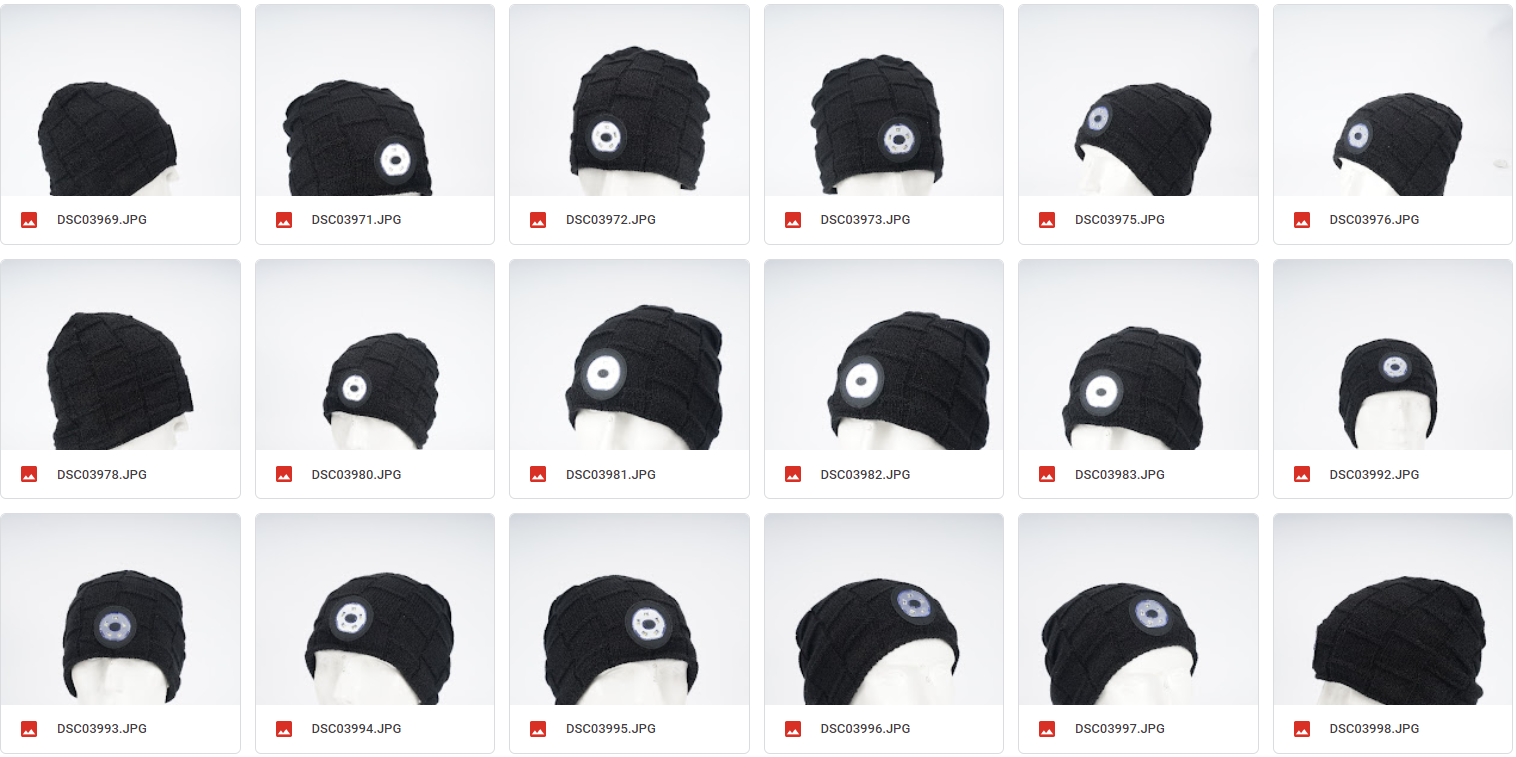 My regularization images, 100 sheets: 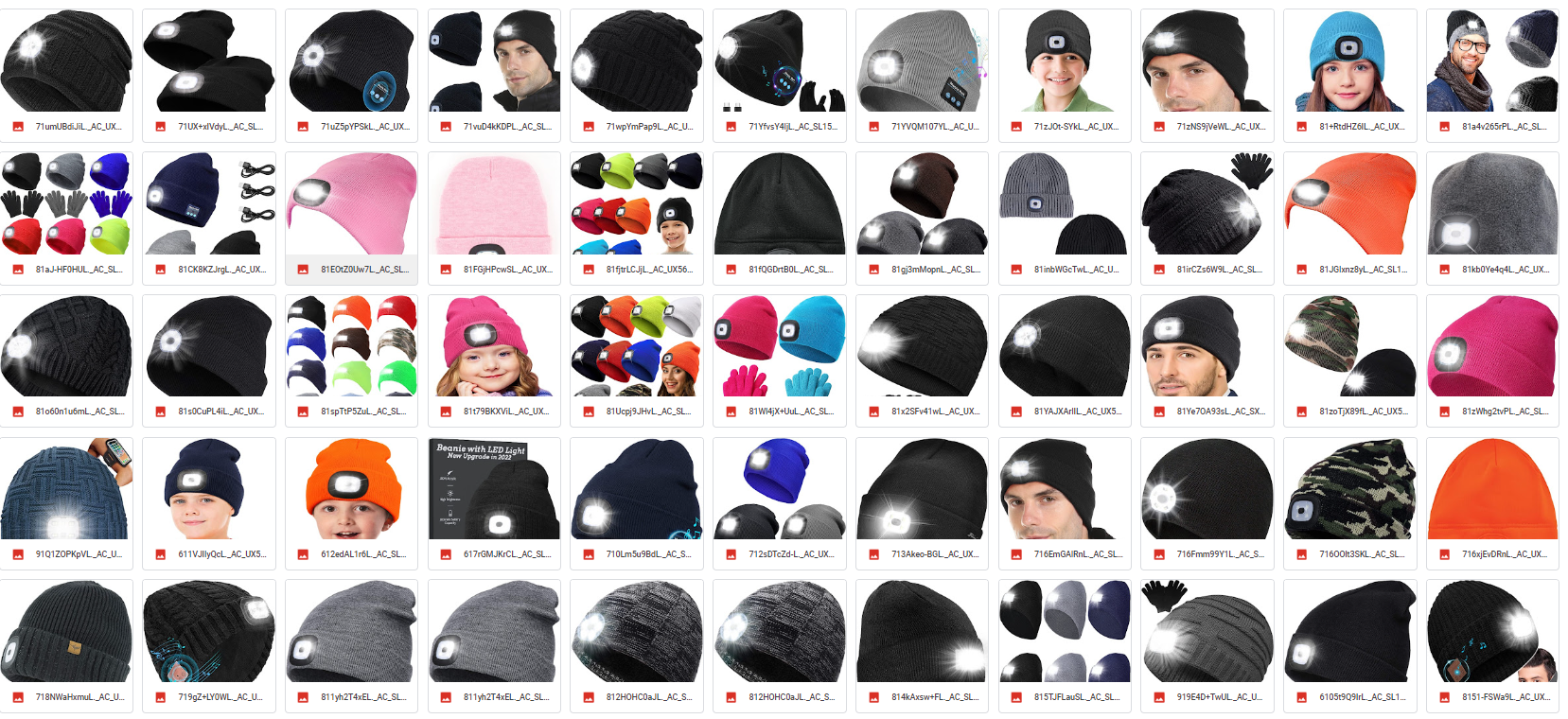 Results obtained from prompt "a man wears a sks hat in winter": 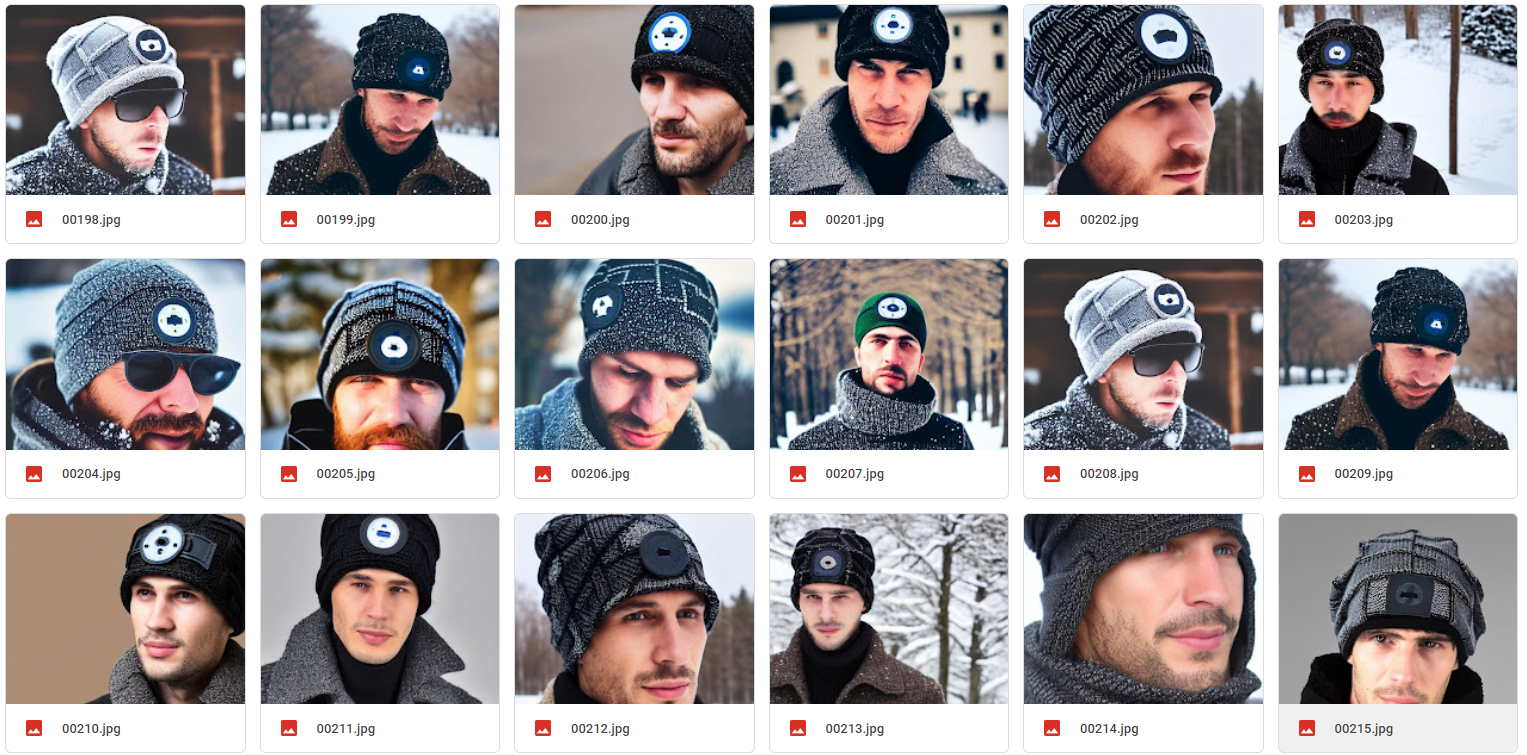 It seems that there is a gap...
My training data      logs ouput images --- Epoch 2 ---  --- Epoch 10 ---  --- Epoch 20 ---...
对应 task_sequence_labeling_ner_crf.py,有个地方没看懂,想请教一下苏神:  经过观察,categories 是一个['PER','LOC',‘ORG’] 三类别的List 不太理解,这个label为什么是这样设计的: `labels[start] = categories.index(label) * 2 + 1` `labels[start + 1:end + 1] = categories.index(label) * 2 + 2` 谢谢苏神!!!
After finishing the second picture, original dog lose a lot of detail  