Bin Lin (林彬)
Bin Lin (林彬)
thank you for your excellent work, I want to know where can download the 'vit_base_patch8_384.pth', thanks again!
### Discussion Hello, esteemed LLaVA developer, thank you for contributing such robust code and data to the community. We have extended LLaVA to [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA), which with just **3B sparsely activated...
- 项目名称: MoE-LLaVA:大型视觉语言模型的混合专家模型 - 项目地址: Github: https://github.com/PKU-YuanGroup/MoE-LLaVA Paper: https://arxiv.org/abs/2401.15947 Demo: https://huggingface.co/spaces/LanguageBind/MoE-LLaVA - 项目简介 (**100** 字以内): MoE-LLaVA只有3B个稀疏激活参数,表现与LLaVA-1.5-7B在各种视觉理解数据集上相当,并且在物体幻觉基准测试中甚至超越了LLaVA-1.5-13B。通过MoE-LLaVA,我们旨在建立稀疏LVLMs的基准,并为未来研究开发更高效和有效的多模态学习系统提供宝贵的见解。并且MoE-LLaVA团队已经开放了所有的数据、代码和模型。 - 项目截图 (**6**张以内):     https://github.com/GitHubDaily/GitHubDaily/assets/62638829/586ae7ab-463a-403c-a4fb-2fd8f47d91bc 
项目名称: Video-LLaVA & LanguageBind:北大ChatLaw课题组开源五模态大模型、视频大模型,视频问答新SOTA! 项目地址: https://github.com/PKU-YuanGroup/LanguageBind https://github.com/PKU-YuanGroup/Video-LLaVA 项目简介 (100 字以内): ChatGPT浪潮展现出了人们对于通用人工智能(AGI)的期望,受到业界广泛关注,我们也做了以ChatLaw为代表的语言模型,受到一致好评。然而,由于单纯的文本语言模型不足以解决AGI的所有场景,所以我们决定在图片、视频、音频等多模态大模型领域持续展开工作。 我们将其他模态的信息通过几个全连接层映射成类似文本的token,让LLM可以理解视觉信号。 我们首先提出了LanguageBind这个五模态大模型并会于不久之后开源该五模态数据集。 接着我们将五个模态绑定到语言空间,训练出视频大模型——Video-LLaVA。该框架使得一个LLM能够同时接收图片和视频为输入。在视频任务上刷榜多项榜单,这项工作关注到统一LLM的输入能让LLM的视觉理解能力提升。 所有代码全开源! ## 一、LanguageBind 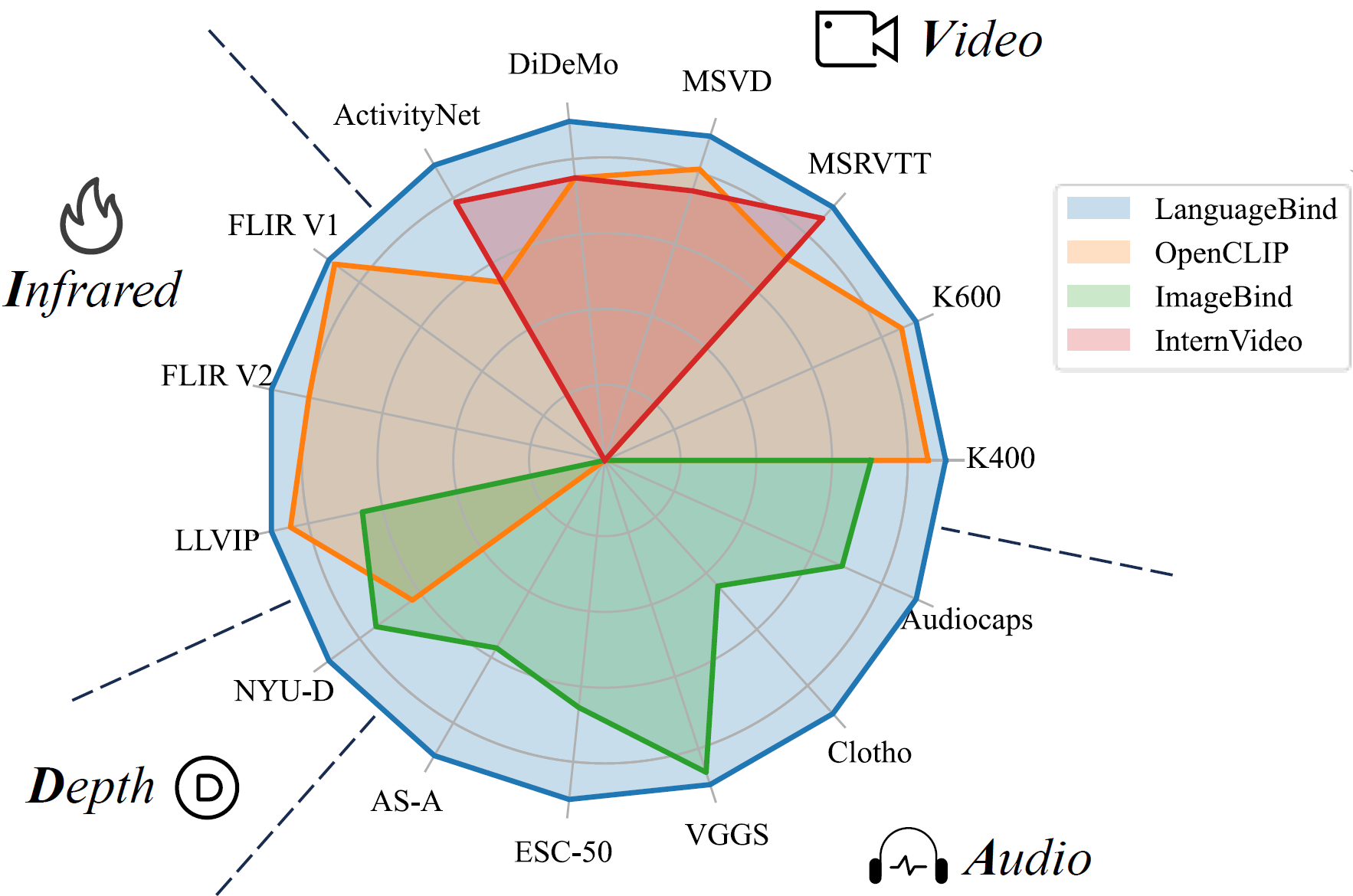 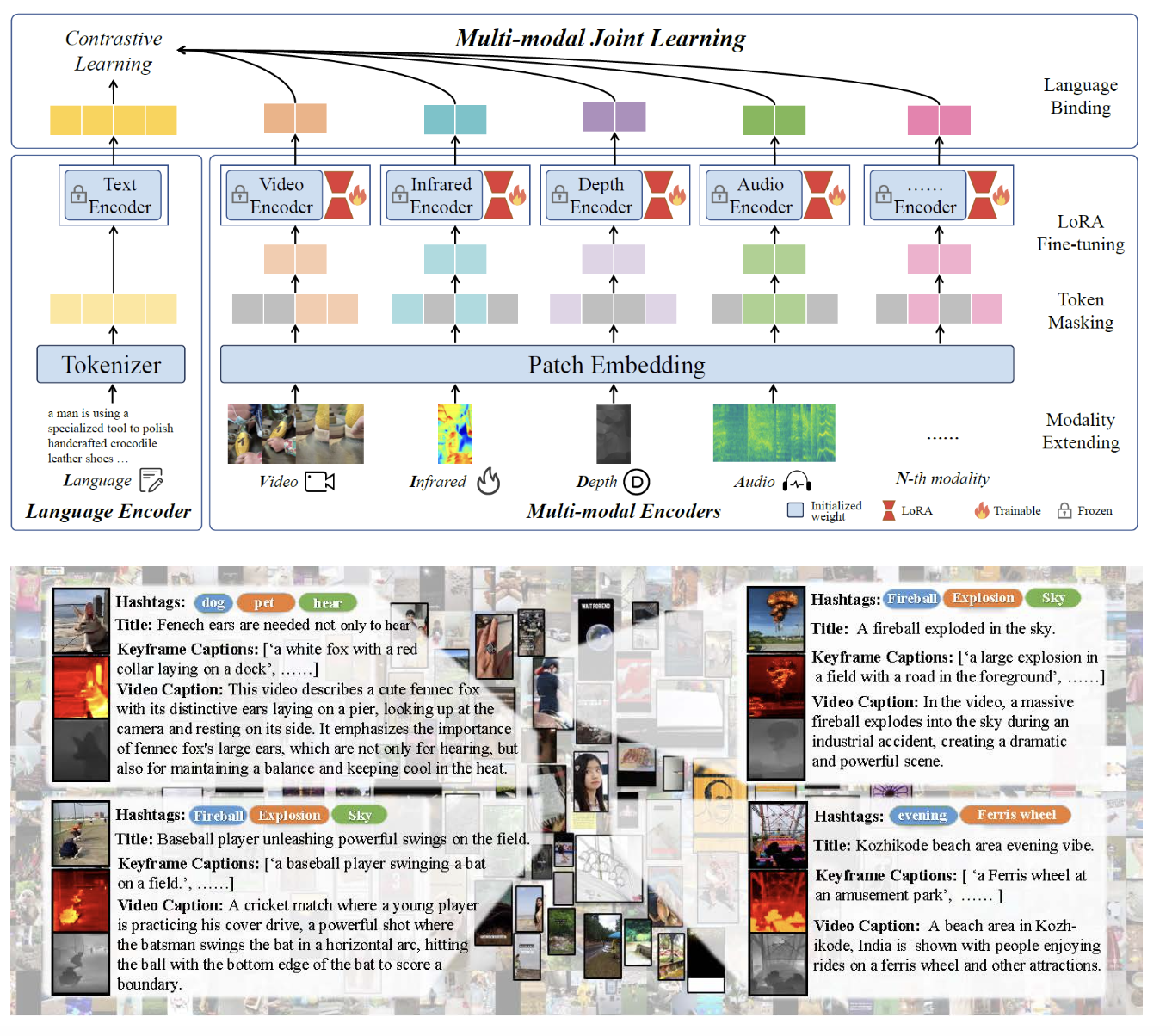 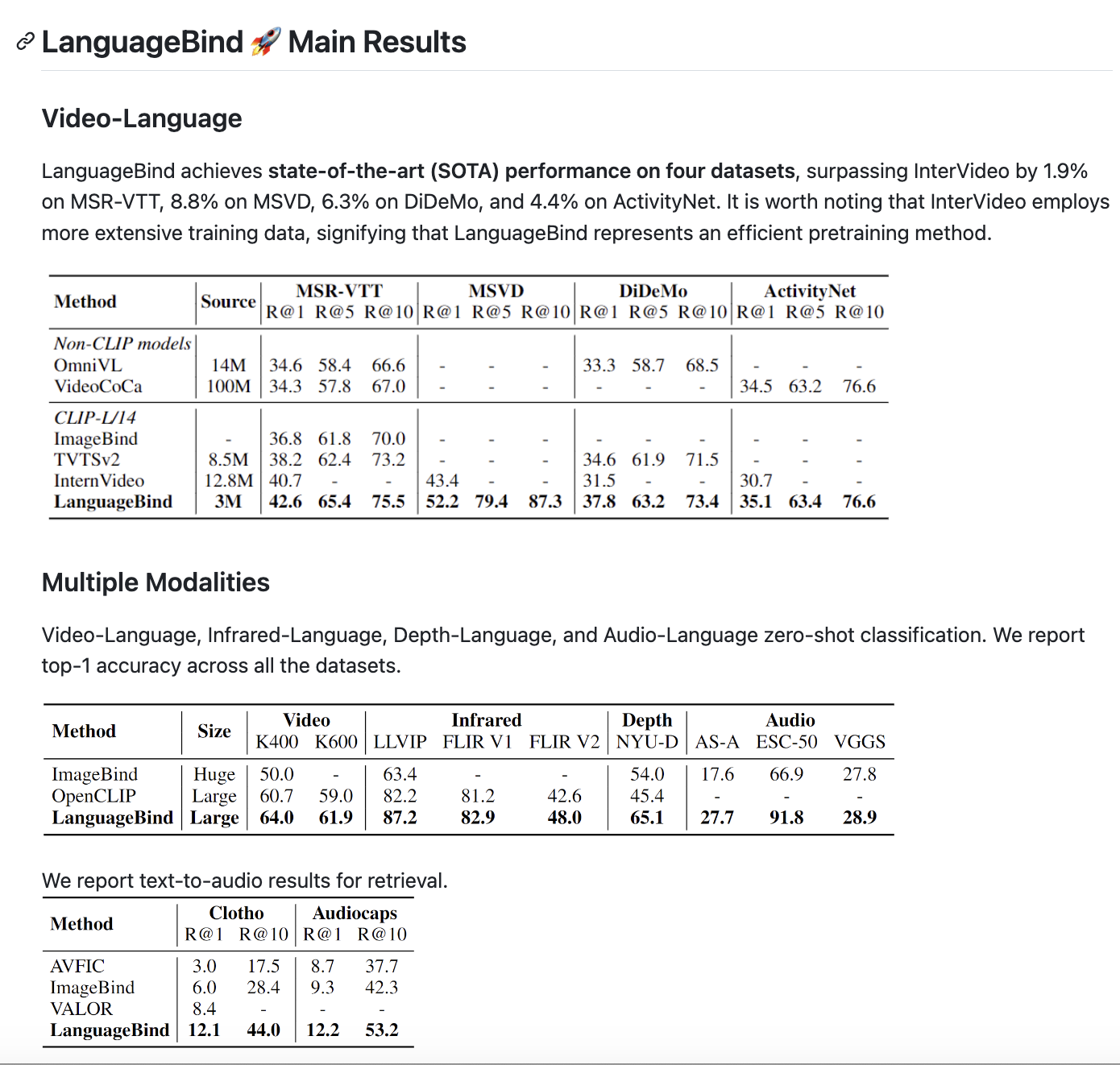 ## 二、Video-LLaVA 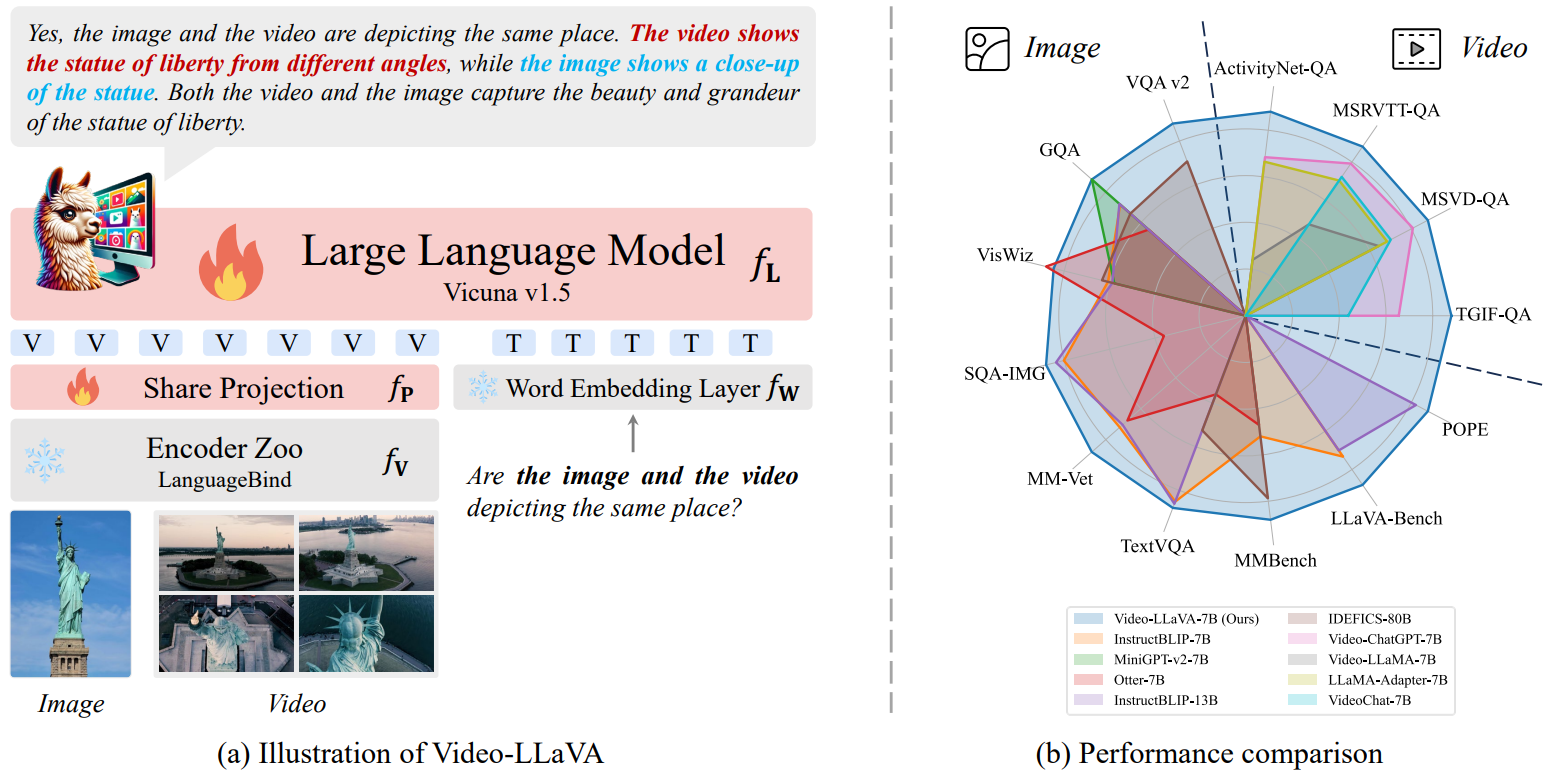 [](https://github-production-user-asset-6210df.s3.amazonaws.com/62638829/284110937-71ab15ac-105e-4b18-b0b5-e1b35d70607b.mp4) 
wonder work! but I'm confuse about that why use pooling token instead of [CLS] token? Is performance become worse? or anything I miss?

 I have 1 video (already encoded offline as 16 images), 1 image (encoded in .pth), 1 title, 8 captions, and I use a custom decode function to decode them....
I am a freshman in RLHF, so will you upload a demo code of RLHF? or slide file of RLHF?
I want to mask part of the image and then rebuild it, not randomly.
In appendix A.2 it is mentioned that the class label is concat as another input to the padded feature. I would like to ask how to encode from a text...