GG22G2
GG22G2
page.getHtml().links()使用us.codecraft.webmagic.selector.LinksSelector挑选a标签。 在获取a标签的href属性时,调用会org.jsoup.internal.StringUtil#resolve(java.net.URL, java.lang.String),用来把相对路径的请求转换为绝对路径。resolve中又使用URL类来解析href属性. 对于``,URL类会把href中内容解析为javascript协议,并调用getURLStreamHandler获取协议对应的URLStreamHandler。因为JAVA中没有对javascript协议的实现,会导致大量无用查找过程。 具体影响可能跟javascript:数量有关。 我母亲通过 URL.setURLStreamHandlerFactory来解决,但是setURLStreamHandlerFactory只能被调用一次,感觉很多时候不合适 > URL.setURLStreamHandlerFactory(new URLStreamHandlerFactory() { URLStreamHandler javascriptHandler = new URLStreamHandler() { @Override protected URLConnection openConnection(URL u) throws IOException { return null; } }; @Override...
根据响应状态码判断是否走重试机制

我今天在使用免费代理,正常应该是要爬取1000个页面,结果只爬取了几十个。 最后发现是因为代理质量查,经常导致请求后返回400状态码,响应体也是错误的。但其实不用代理就能返回正确内容。 我原本以为这样的情况一定会走重试机制,但最后发现是,HttpClientDownloader中不论htttp请求的响应体状态码是200或400,只要请求没有报错。那么Page.downloadSuccess就置为true。us.codecraft.webmagic.Spider#processRequest中只要downloadSuccess为true,就不会走重试的分支。
jsoup中有一个selectFirst方法,匹配成功一次就结束了,相比于select要做全文档匹配会好不少。 webmagic项目引用的xsoup中的jsoup版本是1.8.3,这个版本的jsoup还没有selectFirst方法。 我主要看了下xpath方式,最后调用的org.jsoup.select.NodeTraversor#traverse,所以每次都要全文档匹配。 如果不修改xsoup,我能想到的方式是: 直接调用 XPathEvaluator compile = Xsoup.compile("//div"); 通过反射获取compile中的evaluator属性,然后调用 ` Collector.findFirst(evaluator , page.getHtml().getDocument().root()); ` 所以是否能为webmagic加上selectFirst方法。
I have ip and three public network ports available. I want to show more than 10 rtsp streams in my html. Because of the limited port, I can only play...
这个网站无法加载翻译图标,也不会展示翻译结果。 查看控制台,显示scp策略导致的 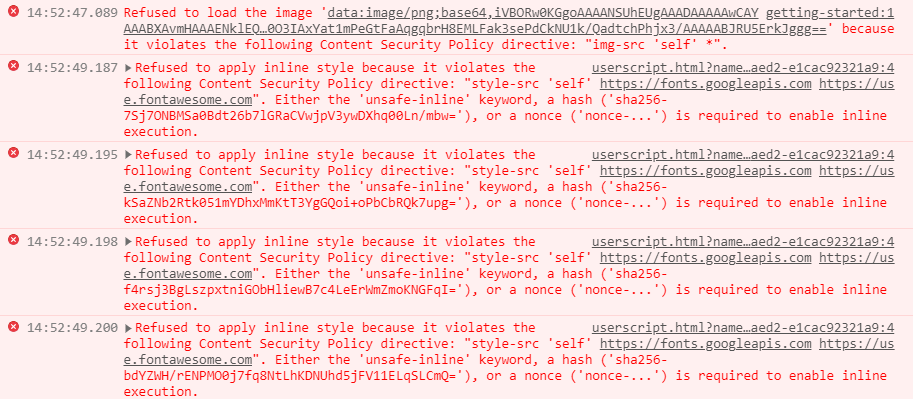 最后在页面上找到这个 ``
OpenSharedResource创建失败,我debug obs对比发现,obs获取到的IDXGIAdapter是我的gpu,但是你通过 D3D11CreateDevice(NULL,...)创建的,好像IDXGIAdapter是cpu的集显,导致OpenSharedResource失败。