Lily Erickson
Lily Erickson
> Thanks! Do you have a small reproducer? Oh dear, thank you for asking. It appears I've made a very small mistake and jumped to conclusions early. Allow me to...
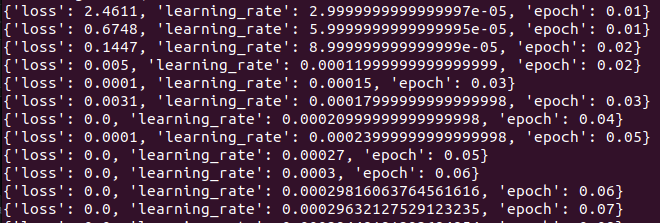 Loss and learning rate go sub-0 pretty quick. Usually they're expressed using e-x. Are you sure your terminal isn't just truncating the output?
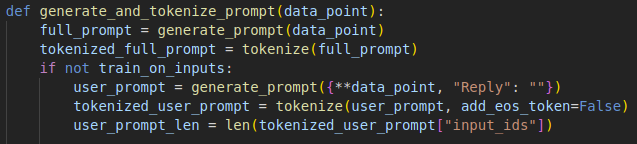 So I discovered an issue where, when switching to a new dataset, the attention mask actually just sets the dictionary key for the Output to be "", before calling...
Yes, the original cleaned version worked fine. After fixing the problem, Loss appears to stay steady for a single epoch.
7bn works with the cleaned alpaca dataset, and Another dataset of mine that uses a similar, yet not identical, format, with different key names. On Sun, Mar 26, 2023, 9:14...
Your json dataset will have a list of dictionaries. If your output key is something other than "Reply", (Maybe it's "Output", or "output", they're case-sensitive) you should change the "Reply"...
Try putting `with torch.autocast("cuda"):` at the start of your evaluate function ``` def generate_response( instruction, inputs=None, temperature=0.7, top_p=0.75, top_k=40, num_beams=4, max_new_tokens=128, **kwargs, ): prompt = prompter.generate_prompt(instruction, inputs) with torch.autocast("cuda"): #Useful...
Hmm, I'm not sure then peft_model is just a wrapper for LoRA though, it should use the same mechanism for both
In CPU? I have no experience, but llama.ccp is a CPU pipeline for llama, you could check out their repo (or try autocasting to CPU maybe? Idk, never done it)...
> I ran into the same error message when launching. In my case, I commented out this section in `generate.py` since I'm purely on a CPU. > > ``` >...