EVAKKKK
EVAKKKK
@Daming0508 你好,我最近也在跑这个代码,但是运行出来的结果很奇怪,actor和critic的损失都很大,请问你也是这样吗? 
@Daming0508 我尝试调整参数了,但是收效甚微,如果你修改成功可以分享一下吗,非常感谢!
@Daming0508 很抱歉再次打扰你,但是最近一直没什么思路,请问你解决了吗,这个损失过大的问题,sad....
我不知道那里出现了错误,一直提醒这个地方有错
已经改好了,确实是数据集的问题,在embedding前转成int64就可以了,可以问一下几个变量的意思吗,多次出现了以feat命名的变量,比如feat_embed_size,self.total_feat = static_feat + dynamic_feat.等等,想问一下这是什么意思。
@massquantity 我在研究DDPG.py这个文件的时候 发现这个前向传播的函数我有点不太理解 为什么要处norm 进行归一化吗?这个scores的计算为什么是这样的呢scores = torch.matmul(action, item_embeds.T),是对用户采取动作与embedding layer相乘进行一个处理吗? 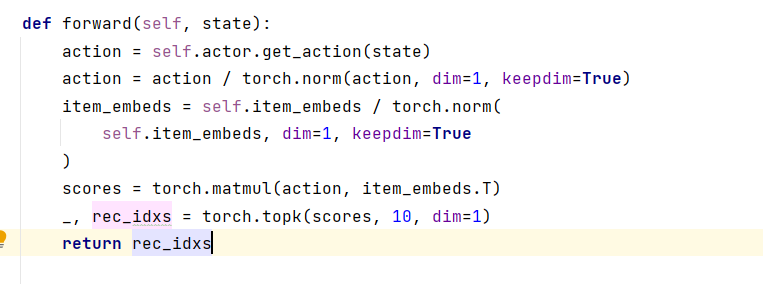
@massquantity 我看原文的奖励的定义是 skip/click/order an item is 0/1/5 能问一下你的这些是什么意思吗 最后一个5是购买我知道 
> 使用的数据是来自淘宝的,pv 是浏览,cart 是加入购物车,fav 是加入喜欢,buy 是购买。reward 是随意定的,RL 里的 reward 定义本身就是难点。 我终于找到了能跑的服务器,运行ddpg之后,这个损失正常吗?看起来很奇怪 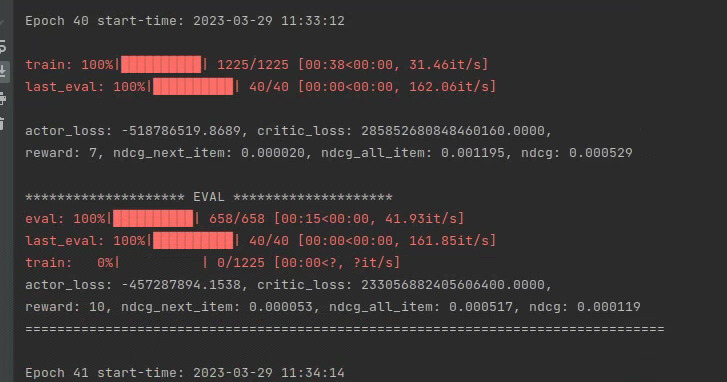
@massquantity 我又重新运行了一遍但是这个损失还是非常大,NCDG的值又很小,请问你运行的结果也是这样吗,看起来数值很奇怪,像是哪里出了问题,如果你方便的话可以回复一下吗,非常感谢!
@massquantity 我回看你的博客后发现你当时也有发现这个问题,请问目前GitHub上面的项目是修改过后的吗,为什么损失还是那么的大 