fanc_
![]()
fanc_

树莓派系统信息如下: 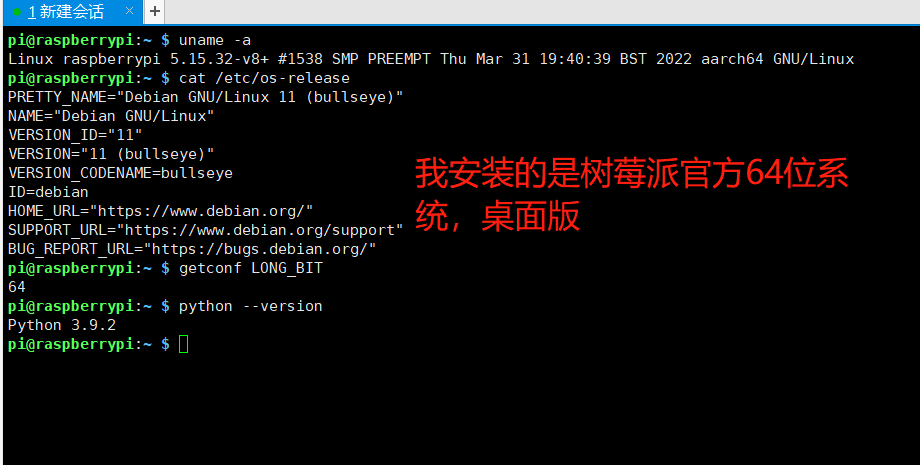  编译命令为: ./lite/tools/build_linux.sh \ --arch=armv8 \ --with_python=ON \ --with_extra=ON \ --with_cv=ON \ --python_version=3.9 编译结果: 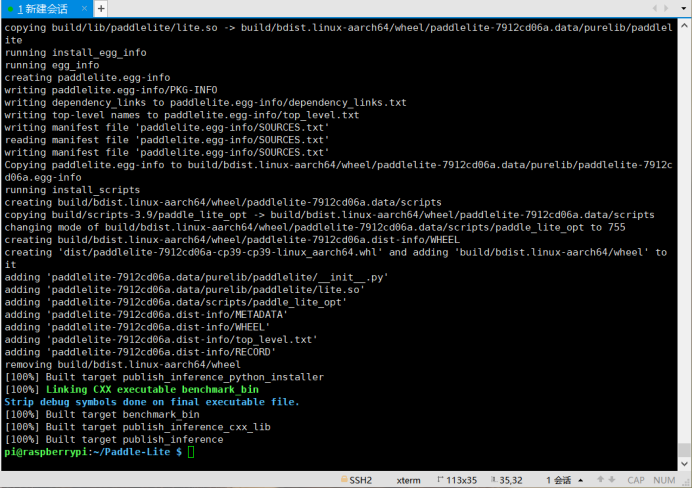  安装成功:  pip list查看: 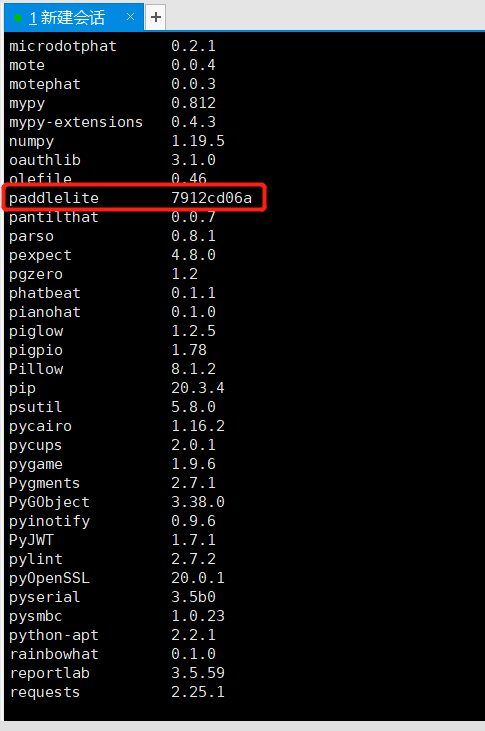 验证是否安装成功:  想请问为什么版本号显示是这样,是因为python版本不对应吗
### 问题确认 Search before asking - [X] 我已经搜索过问题,但是没有找到解答。I have searched the question and found no related answer. ### 请提出你的问题 Please ask your question 在原有配置文件四个算子下,根据官方文档,另外加入随机擦除算子:   所报错误如下:  请问是什么原因,求大佬解答。
### 问题确认 Search before asking - [X] 我已经搜索过问题,但是没有找到解答。I have searched the question and found no related answer. ### 请提出你的问题 Please ask your question 问题1:log_iter设置的是什么,看过一些项目里对其的解释是显示训练信息的迭代间隔,有点不太理解什么意思,控制下图红框中的信息吗,是怎么算得的 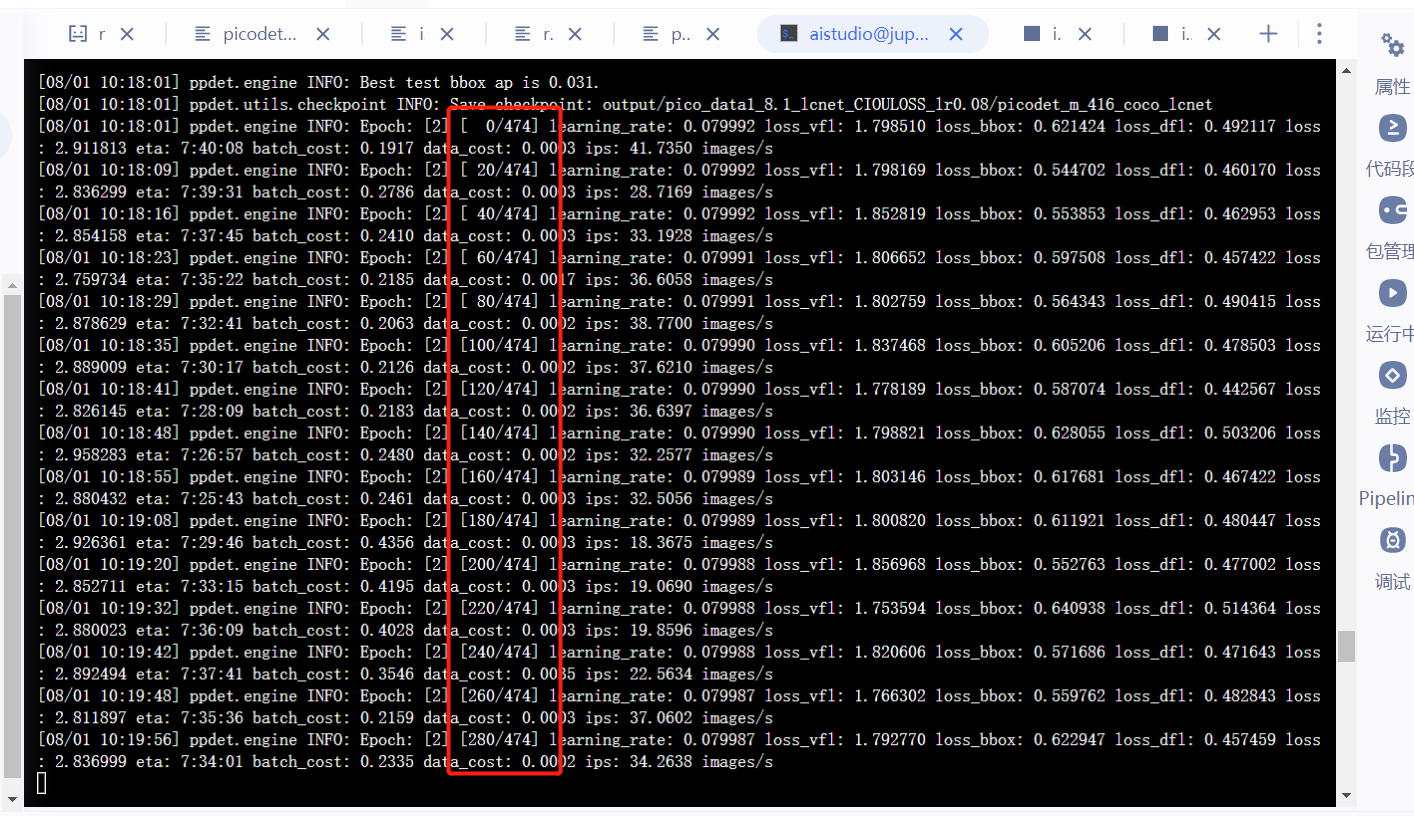 问题2:如图,没有CIouLoss吗 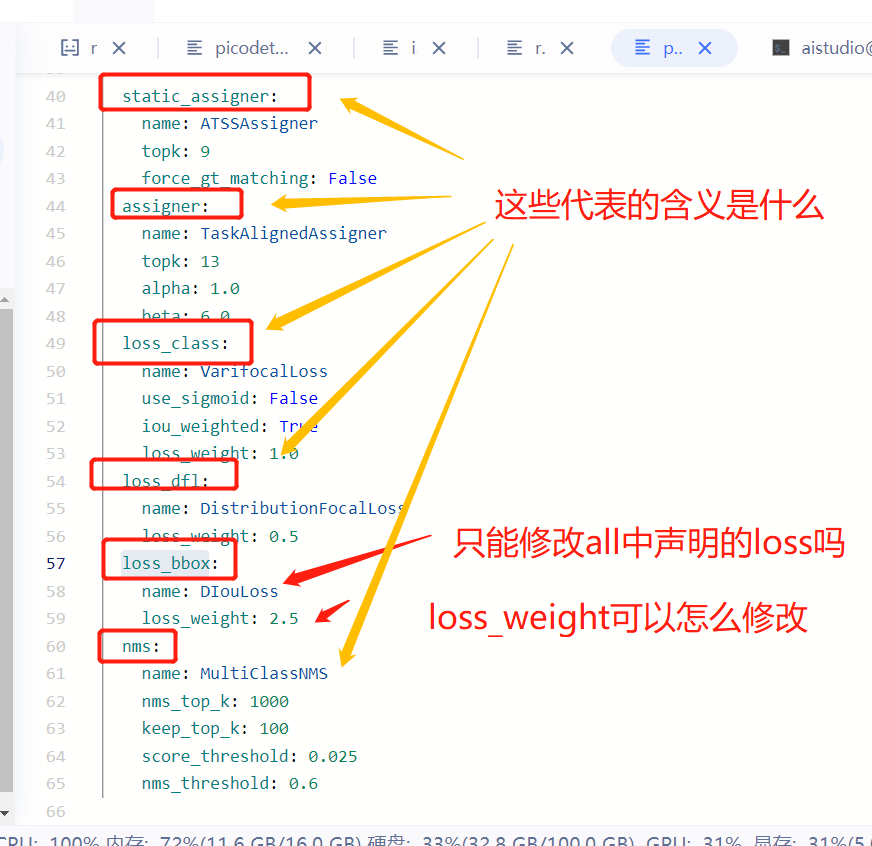  问题3:单图和batch数据增强最多可以加几种,有什么先后顺序吗 ...
### 问题确认 Search before asking - [X] 我已经搜索过问题,但是没有找到解答。I have searched the question and found no related answer. ### 请提出你的问题 Please ask your question 请问下中途中断训练 想要重新训练 是从output里最大的那轮开始还是best_model开始 一开始的训练语句如下: CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python tools/train.py...
### 问题确认 Search before asking - [X] 我已经搜索过问题,但是没有找到解答。I have searched the question and found no related answer. ### 请提出你的问题 Please ask your question 问题1:混合精度和正常多卡训练有什么区别吗 问题2:按照官网示例的混合精度语句,报了如下错误是什么原因 语句(train的bs由默认的8调整为4): python -m paddle.distributed.launch --gpus...
请问我按照示例启动多卡训练为什么会报这种错误,不知道哪里出的问题  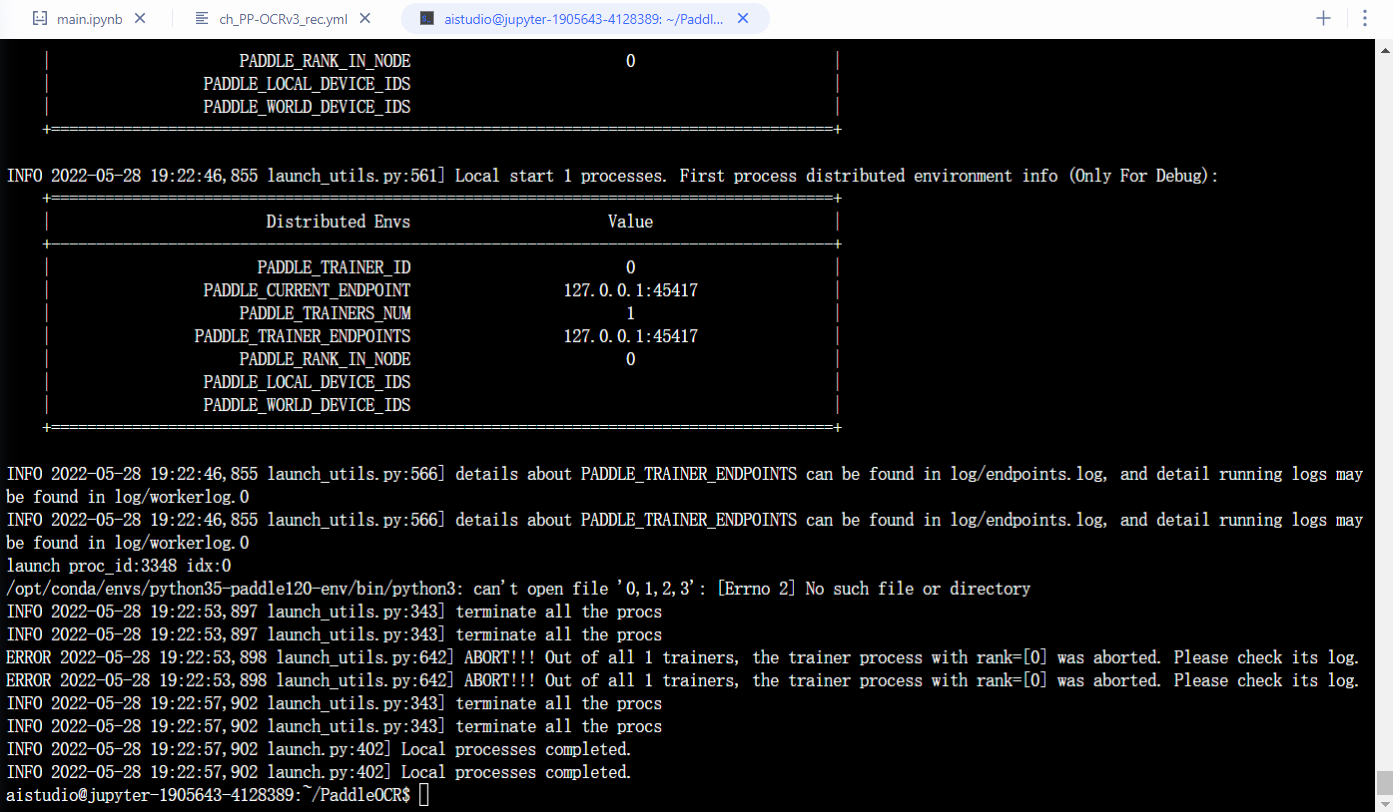 和官方文档中的示例也基本类似 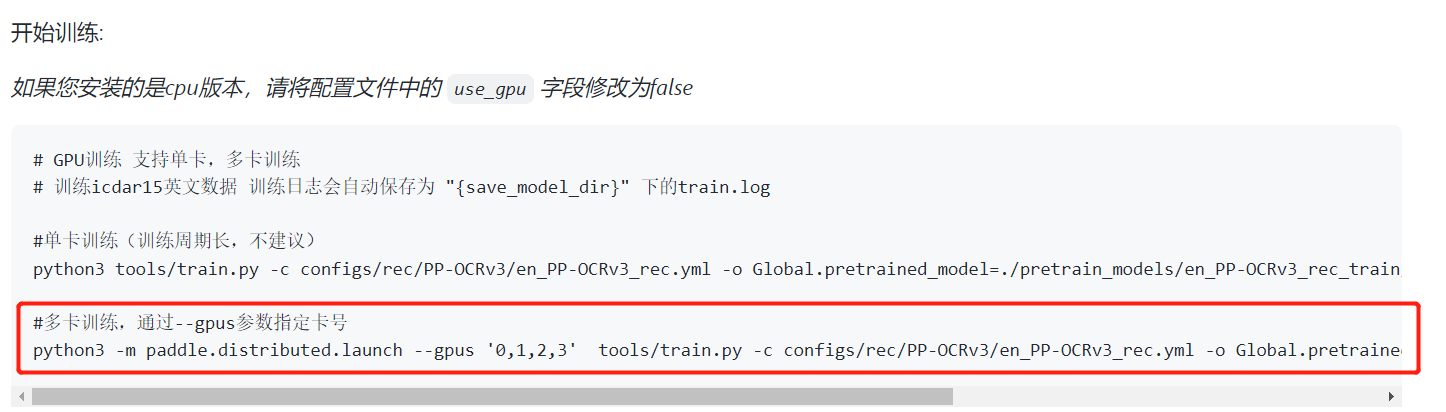 求大神解答,感谢!
请问我想在Jeston nano上部署PP-YOLOE模型,使用FastDeploy和Paddle-Lite哪个比较合适
请问手工标注的图片在哪个压缩包里,Annotation里是标注好的嘛,但是我看只有1431个,还有positive-Annotation里的是什么
### 问题确认 Search before asking - [X] 我已经搜索过问题,但是没有找到解答。I have searched the question and found no related answer. ### 请提出你的问题 Please ask your question 1.请问下DCNv2算是特殊算子吗,对于使用Paddle Inference推理来说,我看某篇文章说yoloe避免使用DCN和matrix nms之类的特殊算子,使用DCNv2改进是否可行呢 2.目前更换第四个stage的卷积后效果较baseline有提升,但是导出后推理时出错,效果如下(第一个为Baseline,第二个为更改最后一个stage中的卷积为DCNv2的效果,部署于jeston nano上用padd lnference推理): ...