AlexRain
AlexRain
没有复现, 我在 langchain==0.0.146 上是可以的
> @AlexRainHao 我用的也是 langchain==0.0.146,但跑不通,安装包版本都是以requirements.txt下的 那挺奇怪了, 我这边是 python3.10, linux 上运行, 试着检查下 `1.txt` 的编码格式呢 按照你给的代码, 我可以正确输出 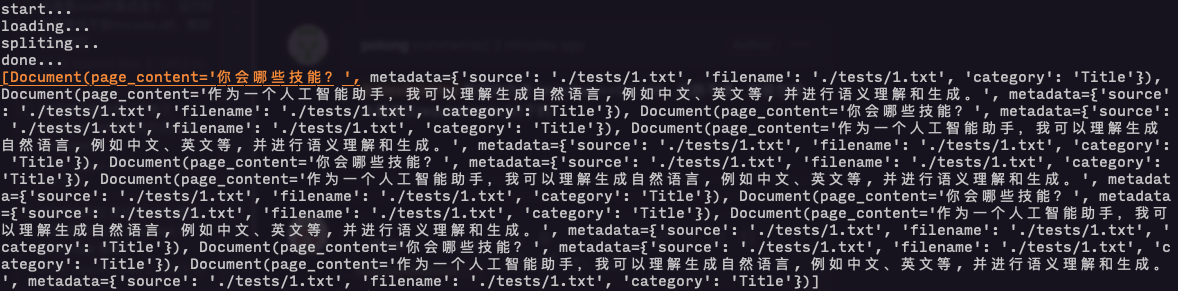
P100 换了不同的 11.x 的 CUDA toolkit 仍然不行 😵
same error, within docker enviroment, I can only training with only one CUDA card, and have no idea how to solve this issue
> same error, within docker enviroment, I can only training with only one CUDA card, and have no idea how to solve this issue fix it through liangwq/Chatglm_lora_multi-gpu#3, thx
> I update transformers and accelerate from 0.17.1 to 0.18.0 and it works. Thx, I've successfully conduct training and inference within docker enviroment
> Hi all, I stumbled upon the same error when using a kubernetes pod with 2 GPUs. I've updated both the transformers and accelerate packages but it still didn't solve...
> 是用的GLM还是GLM2? ChatGLM 的 4bit flm 模型, 是从您 huggingface 上下的