RockSAMA
![]()
![]()
![]()
RockSAMA

代码的智能提示其实是一个在开发中会比较少碰到的问题,更多的我们是在使用编辑器的时候很自然而然的就用上了这项功能,但是也没有仔细想过其中的原理到底是什么。 笔者之前做过补全的工作,但是受限于时间和能力,选择了将hue的自动补全功能迁移到其他平台的工作,完成相关工作之后看到 [黄子毅的这篇文章](https://github.com/dt-fe/weekly/blob/master/85.%E7%B2%BE%E8%AF%BB%E3%80%8A%E6%89%8B%E5%86%99%20SQL%20%E7%BC%96%E8%AF%91%E5%99%A8%20-%20%E6%99%BA%E8%83%BD%E6%8F%90%E7%A4%BA%E3%80%8B.md),也是另辟蹊径,是另一种自己从头开始做的做法。今天简单的说下自己看到hue中的自动补全是如何完成的。 --- ### 基本原理 大家可以先行阅读上面那篇文章,其实是有一个比较通用的点,就是把我们**光标位置设计为一个特殊字符**。其实如果要自己想出这个结论的话还是需要一些时间的。 这一点为什么重要?因为我们解析的时候是要构造一个树状的结构,所以不可能把前半部分和后半部分的文本分开进行构建,在lexer处理的时候都可能出现问题,就算能够成功的解析在后续构建语法树时也有极大可能会出现结构上的问题。 相较与黄同学的从底层的解析一层层做起,我们选择的方法是使用直接的jison方案进行解析。[hue的jison文件]() jison本身就是js版本的bison和flex的合集,他是其在js上的一层实现,我们可以用它完成编译器的前端工作(此前端非彼前端)。 他的语法这里就不赘述了,网上有很多教程,因为我们要做的是SQL的自动补全,整体的语法还是比较简单的,主要的也就create,insert,select这几种DML,DDL。 要写出整个解析语法的解析规则还是一个体力活。在书写的过程中也要对编译原理有足够的了解,不然会收到编译器的大量警告和报错。由于解析的过程会有很多递归的操作,所以写的时候要小心自己写下的的语法规则。如果有不确定的地方可以去看看一些开源的方案的代码或者antlr等。 不过上面说的是如何生成AST,如果我们的规则不符合标准的语法结构咋办呢,比如像自动补全的情况?**这时候我们可以把光标当成一个特殊符号,在每一个结构中进行独立的补全处理配置。** 上面这话啥意思,我们一般的解析规则是 ```sql select a from b; ``` jison会把这个SQL按照这种规则进行解析(简化),得到一个树状的结构 ``` SelectStatement | \ SelectList FromSource | | SelectItem...
> 上一次说了webpack打包的原理,但是仅仅是打包而已,没有涉及到服务器和中间件还有热加载相关的东西,这次就来聊一聊 我们写这篇博客是有一个目标的,就是想着把dev-server应用到rollup上面重新实现一次,不过碍于二者的打包方式以及输出资源的方式都有所不同,这里我们就先看看dev-server源代码的执行方式,看搞清楚他们的原理之后会不会有方法将他们组合起来 + `webpack-dev-server`简写为`DS` + `webpack-dev-middleware`简写为`DM` + `webpack-hot-middleware`简写为`HM` + `EventEmitter`简写为`EE` ### 目标 + 搞清楚dev-server中使用express做了哪些事 + express和Socket是如何和谐相处的 + HM是怎样进行模块的热处理的 + express的中间件系统是怎样的,和koa的中间件系统有什么区别呢 + 文件变化检测的底层是怎么做到的啊 + 在不同平台,怎么『嘭』的一声打开浏览器呢 + react-hot的插件做了什么操作才做到无痕刷新 + 怎么react的热更新机制从之前的loader变成了现在的babel-plugin啊 +...
由于前端资源的特殊性,首屏有大量的优化都是体现在网络上的,在网络优化中有非常多文章进行说明,这里我就不再赘述了。但是其中有一个非常有意思的点,就是14KB的问题,大家基本都听说过,但是却很少知道其中的道理,我在网上也没看到很详细的解释,所以提出来说一下。 **为什么首屏的html资源要限制在14KB以内呢?** 1. 最普遍的说法(各种博客): 反正是14kb可以最好的利用网络带宽,可以让html在一次就传输完所以最快咯~ 2. 详细的说法(谷歌开发者文档): https://developers.google.com/speed/docs/insights/mobile > 鉴于 TCP 评估连接状况的方式(即 [TCP 慢启动](http://en.wikipedia.org/wiki/Slow-start)),新的 TCP 连接无法立即使用客户端和服务器之间的全部有效带宽。因此,在通过新连接进行首次往返的过程中,服务器最多只能发送 10 个 TCP 数据包(约 14KB),然后必须等待客户端确认已收到这些数据,才能增大拥塞窗口并继续发送更多数据。 > > 另外还需注意的是,10 个数据包 ([IW10](http://tools.ietf.org/html/draft-hkchu-tcpm-initcwnd-01)) 这一限值源自 TCP 标准的最近一次更新:您应确保自己的服务器已升级到最新版本,以便能够充分利用这次更新。否则,这一限值可能会降低到 3-4...
## webpack中的对象构造器 昨天在webpack这个[Issue](https://github.com/webpack/webpack/issues/5600)上面有人提到了个很有趣的问题,大概是说了3版本的webpack生成的代码是如何做到的引入了新的模块。比如像下面这样: ```javascript import foo from "module"; foo(1, 2); // x; function callDirect(o) { const foo = o.foo; return foo(1, 2, 3); } function callViaCall(o) { return o.foo.call(undefined, 1,...
# Hot Reloading in React > 本文是Dan Abramov发表于Medium文章的部分译文,只截取了其中部分内容,仅供学习交流,主要作为本人其他博客的素材使用,禁止转载 React Hto Loader是我第一个比较知名的开源项目,据我所知,这是第一个可以实现让使用者无需重新挂载组件组件或是丢失组件state的工具,在刚开始的时候我只是做出了一个Demo用于在台上进行演示,不过在之后我发现了大家对这个工具的巨大热情,所以我花费了几周的时间开发出了这个工具。  ### 第一次尝试: 直接使用HMR 在创建这个特别的项目之前,我曾想到直接使用webpack提供的HMR来替换项目中的根节点并且重新渲染我们的整个React树。 但是需要注意的是HMR根本不是为React定制的。James Long在这片文章中说的很不错。简单来说他只是一个「当新版本的模块可以使用过后,调用设置好的回调函数,让我们便于对新模块做一些处理」的作用。这件事情会发生在你每次保存修改好的文件的时候。 一个纯粹的HMR来实现热加载就像是这样的: ```js var App = require('./App') var React = require('react') var ReactDOM...
> 自己看源码的时候做的一些简单的笔记,感兴趣可以看一下,不保证完全正确 > 如果要看完整解析请还是看别人家的资料吧(~~这家的太烂了~~) 1. 判断是否使用new初始化Vue,通过其中的this指针指向判断在使用new初始化时,创建一个新对象,并寻找它的原型链上的元素,把其中的this指向自身  2. Vue自身的类非常简单,全部的功能都是用过mixin挂载上去的,这样有一个好处就是提高了 解耦程度,但是既然是mixin那他就是不符合函数式编程的概念的,对于共有属性的一些操作必须遵从顺序  #### initMixin(Vue) 3. 全部使用的都是flow进行类型检查,这样的对比ts有什么好处呢?根据尤雨溪本人所说,这样的做法是为了避免使用ts带来的巨大工作量,flow可以对每个文件单独进行改动,难度较低一些,而且相对于全部推翻重做风险低很多 4. 在对设置项option进行设置的时候,首先对内部模块进行了优化,因为其并不需要设置这些 配置项,然后对配置项执行了mergeOptions的方法,此放方法较为复杂,首先进行了数据的扁平化  可以看到也没有做函数式的操作,都是通过共享参数直接传进去处理(奇妙) 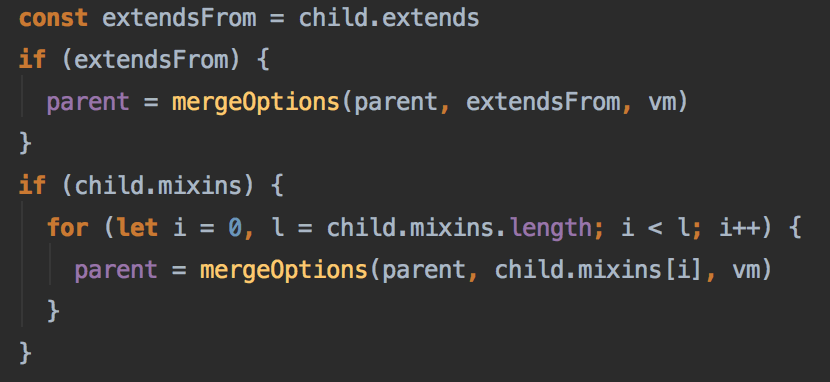 随即进行了递归操作,对子元素的配置项进行了遍历(应该是之后添加上去的) 5. 做了一个判断看是否原生支持Proxy代理,方法很粗暴,如果有就包装一层代理还设置了keyCode,不知道是要干嘛(开发模式使用,多半是快捷键刷新之类的) 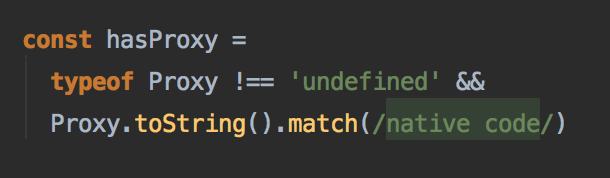 6. 喜闻乐见的有进行了几次初始化,当然中间有两个钩子函数的调用,可以看到在创建vue实例的时候进行了哪些工作 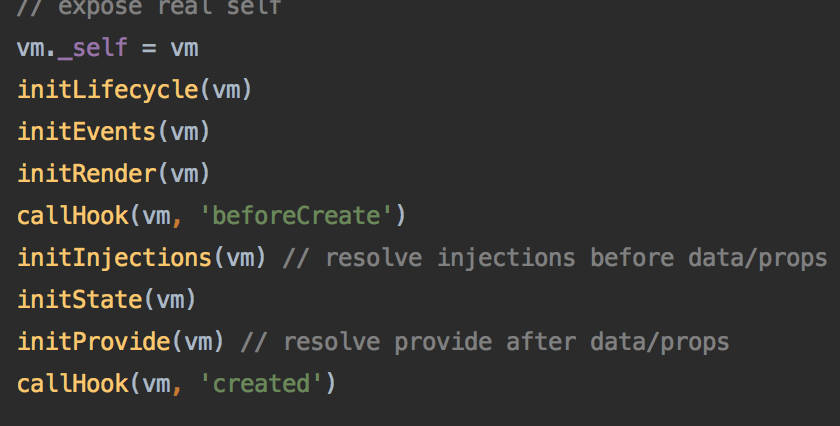 7. initLifecycle函数:对生命周期进行初始化,这个阶段挂载上了很多属性,应该是给后面做准备的用途...
> 说在前面: > > 这些文章均是本人花费大量精力研究整理,如有转载请联系作者并注明引用,谢谢 > > 本文的受众人群不是webpack的小白,仅适合有一定基础的前端工程师以及需要对webpack进行研究但是在阅读源码的过程中有些小的细节不明白时进行查阅理解使用,学艺不精,文章中很多地方可能有理解上的问题希望在评论区指正 ### 需要解决的问题 + tree shaking是如何做到的 + webpack操作流程中的variable有什么用 + scope hoisting是怎么实现的 + html-webpack-plugin最后怎么拿到的所有资源 + 源码有哪些值得优化的地方 + 默认使用的使用频率高的模块放前面有什么意义 + CommonChunk到底打包了哪些东西 + 最终拼接的资源有哪些东西 + 热加载(HMR)是如何做到的...
此篇博客紧承上一篇,上片讨论了我们的webpack整个处理单个文件的流程,这一节主要说一说webpack的文件打包问题,其实本身是比较简单的,但是有异步块和html-plugin的加入,使这个步骤变得尤为复杂,这里先介绍几个重要的概念: 1. Module,模块,我们的入口文件就是一个模块 2. Block,一个新的资源块,我们在最后进行打包的时候,块里的东西会被打包成一个新的资源 3. Dependency,依赖而已,所有依赖如果不进行处理会被打包到一起,然后通过她们存好的ID在最后使用的时候拿出来使用 4. Variables,不知道干什么用,暂时的使用中一直为空,最近才发现他会给我们的代码里面注入一些IIFE函数,这个过程叫做variable injection(变量注入)绑定一些需要计算的特殊值,比如global,process这一类,直接替换不太好,这是最终打包时的部分代码,可以看到我们的variable最后会被处理成为一个立即执行的函数,拼接出来的字符串参数在这里是module和global  在下面的call中参数进行拼凑时,通过我们的sourceId得到需要引入的对应资源  这样便形成了一个封闭的作用域,拿来干嘛呢?这里就是实际的演示了,他把我们的模块代码整个放到了这个IIFE中间,提供了变量环境,而且这里被包裹的还是lodash。。。他怎么会用到global?这个global又是在解析语法树的时候记录下来的吗 上一节中,我们成功的对每个文件进行了处理,并通过了process的方法对所有入口文件以及他们的依赖文件进行了处理,获得了最初的依赖文件列表,现在我们就可以对资源的依赖进行优化处理,本片的内容将从webpack/lib/Compiler.js:510的断点开始逐步的对源码进行分析 ### seal 在seal之前,由于一轮compilition已经执行完成,先调用finish方法进行收尾处理与之对应的是我们注册的finish-modules事件, 这里我们首先看到的又是index.ejs这个老朋友,由于他是单独的文件经过了loader处理没有获得额外的处理函数的依赖,所以最终这里看到的module实际上是它的js外壳包起来的ejs文件,此阶段也还没有进行资源hash的注入等等 这里有一个FlagDependencyExportsPlugin进行了操作,听名字可能就听出来了,他是对我们资源中的export使用进行一个标志的作用,~~和我们最终做出的tree shaking效果可能是相关的~~ 调用seal事件处理 处理我们的preparedChunk,这个东西是我们刚好在进行addEntry的时候添加上的不知道你们还记不记得,中途就没有添加过新的,所以讲道理,一个entry是只用一个的,但是这里使用了一个数组不知道有什么用意  然后把这个入口模块添加到了block里面,过后打包也是从block里面拿数据,block里面的东西会被打包成为单独的文件,但是还是工作在之前的上下文中,这里可以通过看一下这里的import即是我们之前在路由文件中通过import函数设置引入的动态加载路由资源  进入到processDependenciesBlockForChunk函数,就开始处理我们之前做好准备的block了,这里这是一个不断处理依赖的过程,但是没有使用递归的做法,毕竟文件太多了,不断的进行递归会浪费很多空间,取而代之的是使用queue进行记录,处理过程中不断把新的需要处理的模块放到queue里面等待下一步处理 在每一步的处理中 1....