Singing synthesis with LPCnet
Hello,
I was researching this vocoder recently. The LPCnet used the normal speaker data set for training and synthesized sample sounds, and the sample sound output was normal. When synthesizing the singing voice, I encountered some problems,(the following does not consider the previous acoustic model, use real features to train the vocoder)
1、The LPCnet uses female singing data for training and synthesizes sample sounds. The high-frequency part of the sample sounds cannot be recovered. What could be the problem?
The first picture is the original spectrum of singing
The second picture is the synthesized singing spectrum
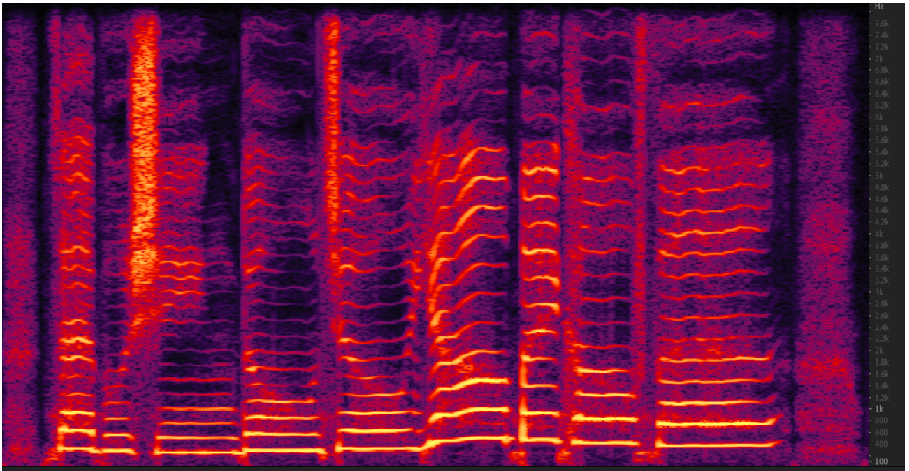
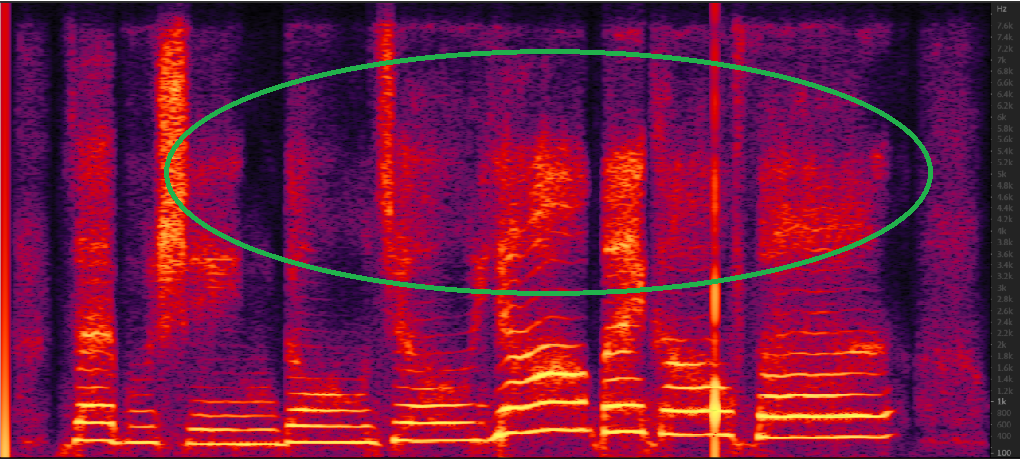
Looking forward to your reply, thank you very much
Could be to do with the particular selection of Bark bands and pitch quantization neglecting harmonics much higher than expected range of speech - do you find that similar lack of recovery happens with speech samples (that contain discernible higher-frequency characteristics)? It may not be limited to singing, more a general bandwidth issue with how LPCNet is configured by default