About EMA update in paper
Hi, authors. Thanks for your great work! After reading the paper, the equation (1) confuses me. Since in the original Mean Teacher framework, the update equation is written as $\phi_{t+1} =\mu \phi_t+(1-\mu) \theta_{t+1}$ , which means the student model is updated using the backward gradient first, and then the teacher model is updated by EMA. However, in your paper, it is written in contrary, as follows. I think it is inconsistent with the original paper. Is this the writing error, or my understanding goes wrong?
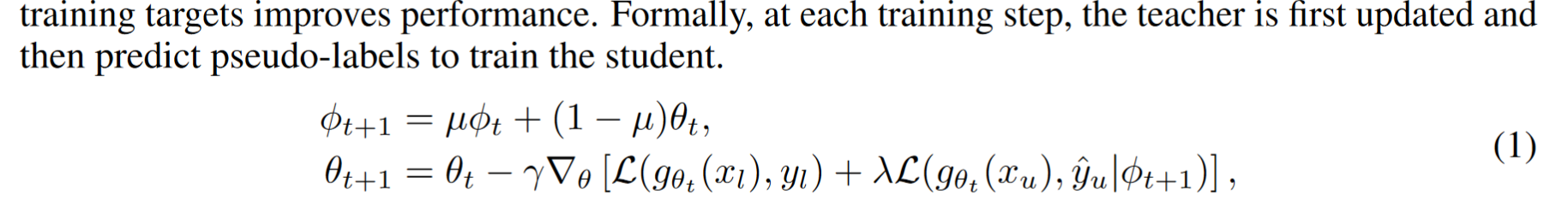
Hi, authors. Thanks for your great work! After reading the paper, the equation (1) confuses me. Since in the original Mean Teacher framework, the update equation is written as ϕt+1=μϕt+(1−μ)θt+1 , which means the student model is updated using the backward gradient first, and then the teacher model is updated by EMA. However, in your paper, it is written in contrary, as follows. I think it is inconsistent with the original paper. Is this the writing error, or my understanding goes wrong?
hello, I want to ask if you success run the code. I meet some problem when run the code for example
KeyError: "encoderDecoder: " DLV2Head is not in the models registry""
And I find missing some dir in this code.