Why triton serving shared memory failed with running multiple workers in uvicorn in order to send multiple request concurrently to the models?
Hi all, Description I run a model in triton serving with shared memory and it works correctly. In order to simulate backend structure to requests to my models, I wrote a Fast API for my model and run it with gunicorn with 6 workers. Then I wrote anthor Fast API to route locust requests to my first Fast Fast API as below image(a pseudo code is witten). my second Fast API runs with uvicorn. but the problem is when I used multiple workers for my uvicorn, triton serving failed to shared memory.
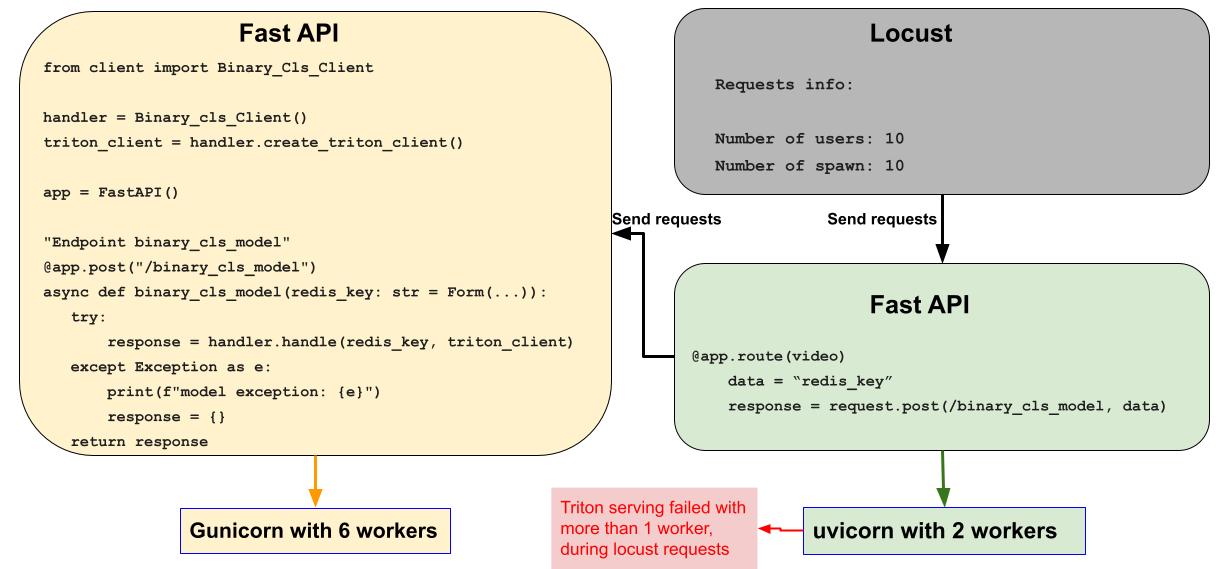
Note: without shared memory, it works correctly even with 10 workers in uvicorn. but my response time is much longer than the shared memory option. so I need to use shared memory option to speed up.
Triton Information
I used Triton server dockerfile: nvcr.io/nvidia/tritonserver:20.11-py3
tritonclient version 2.5.0
I installed Triotn client by pip install
here is my triton client code:
I have a functions in my client code named predict function which used the requestGenerator to shared input_simple and output_simple spaces.
this is my requestGenerator generator:
def requestGenerator(self, triton_client, batched_img_data, input_name, output_name, dtype, batch_data):
triton_client.unregister_system_shared_memory()
triton_client.unregister_cuda_shared_memory()
output_simple = "output_simple"
input_simple = "input_simple"
input_data = np.ones(
shape=(batch_data, 3, self.width, self.height), dtype=np.float32)
input_byte_size = input_data.size * input_data.itemsize
output_byte_size = input_byte_size * 2
shm_op0_handle = shm.create_shared_memory_region(
output_name, output_simple, output_byte_size)
triton_client.register_system_shared_memory(
output_name, output_simple, output_byte_size)
shm_ip0_handle = shm.create_shared_memory_region(
input_name, input_simple, input_byte_size)
triton_client.register_system_shared_memory(
input_name, input_simple, input_byte_size)
inputs = []
inputs.append(
httpclient.InferInput(input_name, batched_img_data.shape, dtype))
inputs[0].set_data_from_numpy(batched_img_data, binary_data=True)
outputs = []
outputs.append(
httpclient.InferRequestedOutput(output_name,
binary_data=True))
inputs[-1].set_shared_memory(input_name, input_byte_size)
outputs[-1].set_shared_memory(output_name, output_byte_size)
yield inputs, outputs, shm_ip0_handle, shm_op0_handle
this is my predict function:
def predict(self, triton_client, batched_data, input_layer, output_layer, dtype):
responses = []
results = None
for inputs, outputs, shm_ip_handle, shm_op_handle in self.requestGenerator(
triton_client, batched_data, input_layer, output_layer, type,
len(batched_data)):
self.sent_count += 1
shm.set_shared_memory_region(shm_ip_handle, [batched_data])
responses.append(
triton_client.infer(model_name=self.model_name,
inputs=inputs,
request_id=str(self.sent_count),
model_version="",
outputs=outputs))
output_buffer = responses[0].get_output(output_layer)
if output_buffer is not None:
results = shm.get_contents_as_numpy(
shm_op_handle, triton_to_np_dtype(output_buffer['datatype']),
output_buffer['shape'])
triton_client.unregister_system_shared_memory()
triton_client.unregister_cuda_shared_memory()
shm.destroy_shared_memory_region(shm_ip_handle)
shm.destroy_shared_memory_region(shm_op_handle)
return results
Any help would be appreciated to help me how to use multiple uvicorn workers to send multiple requests concurrently to my triton code without failing.
Hi @JavanehBahrami, from the code you have provided it appears you might be unregistering all shared memory regions rather than the current one inside your for-loop: triton_client.unregister_system_shared_memory() and triton_client.unregister_cuda_shared_memory(). You can read more about how the unregister shared memory api works here.
Hi @nv-kmcgill53, I changed my code as below, now I added 2 more custom functions named _set_shared_memory and _unset_shared_memory.
Now I run _set_shared_memory function at the initialize function of my class for once in triton client.
This function feeds the same input_simple and output_simple paths to all model instances (the code is below):
def _set_shared_memory(self, triton_client, input_simple, output_simple):
triton_client.unregister_system_shared_memory()
triton_client.unregister_cuda_shared_memory()
input_data = np.ones(
shape=(self.batch_size, 3, self.width, self.height), dtype=np.float32)
input_byte_size = input_data.size * input_data.itemsize
output_byte_size = input_byte_size
shm_op0_handle = shm.create_shared_memory_region(
self.output_layer, output_simple, output_byte_size)
triton_client.register_system_shared_memory(
self.output_layer, output_simple, output_byte_size)
shm_ip0_handle = shm.create_shared_memory_region(
self.input_layer, input_simple, input_byte_size)
triton_client.register_system_shared_memory(
self.input_layer, input_simple, input_byte_size)
return input_byte_size, output_byte_size, shm_ip0_handle, shm_op0_handle
in the end of my client code I have another custom function named _unset_shared_memory which is called at the end of all process:
def _unset_shared_memory(self, triton_client, shm_ip_handle, shm_op_handle):
triton_client.unregister_system_shared_memory()
triton_client.unregister_cuda_shared_memory()
shm.destroy_shared_memory_region(shm_ip_handle)
shm.destroy_shared_memory_region(shm_op_handle)
return
and my requestGenerator now changed as below:
def requestGenerator(self, triton_client, batched_img_data, input_name, output_name, dtype, input_byte_size, output_byte_size):
inputs = []
inputs.append(
httpclient.InferInput(input_name, batched_img_data.shape, dtype))
inputs[0].set_data_from_numpy(batched_img_data, binary_data=True)
outputs = []
outputs.append(
httpclient.InferRequestedOutput(output_name,
binary_data=True))
inputs[-1].set_shared_memory(input_name, input_byte_size)
outputs[-1].set_shared_memory(output_name, output_byte_size)
yield inputs, outputs
Now my client code works with multiple workers in uvicorn (run with 3 workers). but after 28 requests, when my _set_shared_memory function tries to register this line:
triton_client.register_system_shared_memory(self.output_layer, output_simple, output_byte_size)
I faced with segmentation fault as below
/opt/tritonserver/tritonserving.sh: line 10: 69 Segmentation fault (core dumped) LD_PRELOAD=/models/libmyplugins.so tritonserv
er --model-repository=/models --strict-model-config=false
Note: without shared memory, I tried more than 680 requests but no seg fault happened.
I debugged the code and my only guess is that when multiple workers concurrently sent requests, multiple shared memory spaces are opened and before responding completely to the old requests, new requests are started, so my unset function has not been called yet which is in the last part of my function. because of that, I think the server memory got full and crashed. If my guess is correct, how to solve this problem?
There is an problem in creating the shared memory via shm.create_shared_memory_region(<shm_name>, <shm_key>, <byte_size>). Because <shm_key> is the unified id of the created-shared-memory-regions, here you use the same identifier, namely "input_simple" in your code. Try Use "uuid" package to generate uuid to identify created-shared-memory-regions, and reference them by these identifiers.
if you want to the code with multi workers, a papramters need to be specified in triton_client.unregister_system_shared_memory(), which is the shared memory name to be registered, such as triton_client.unregister_system_shared_memory(name='input_data').
Thanks for providing answers to the above! Closing due to inactivity. Please let us know to reopen the issue if you'd like to follow up.