Graph Classification & Batchwise Training
Hi I have two questions:
- I would like to repurpose this for graph classification (where I have a single label per graph). I see there is an option to choose
featureless=Falsewhen defining a newGraphConvolutionlayer. However, the loss is still computed for each node, and I was wondering how I should change your code. - In the context of graph classification, how should I modify your
train.pyfor batch-wise training?
Thanks for putting this together!
Thanks for your questions. For graph-level classification you essentially have two options:
- "hacky" version: you add a global node to the graph that is connected to all other nodes and run the standard protocol. You can then interpret the final value of this global node as graph-level label.
- global pooling: as a last layer, you can implement a global pooling layer that performs some form of pooling operation (optionally with attention mechanism as in https://arxiv.org/abs/1511.05493) over all graph nodes
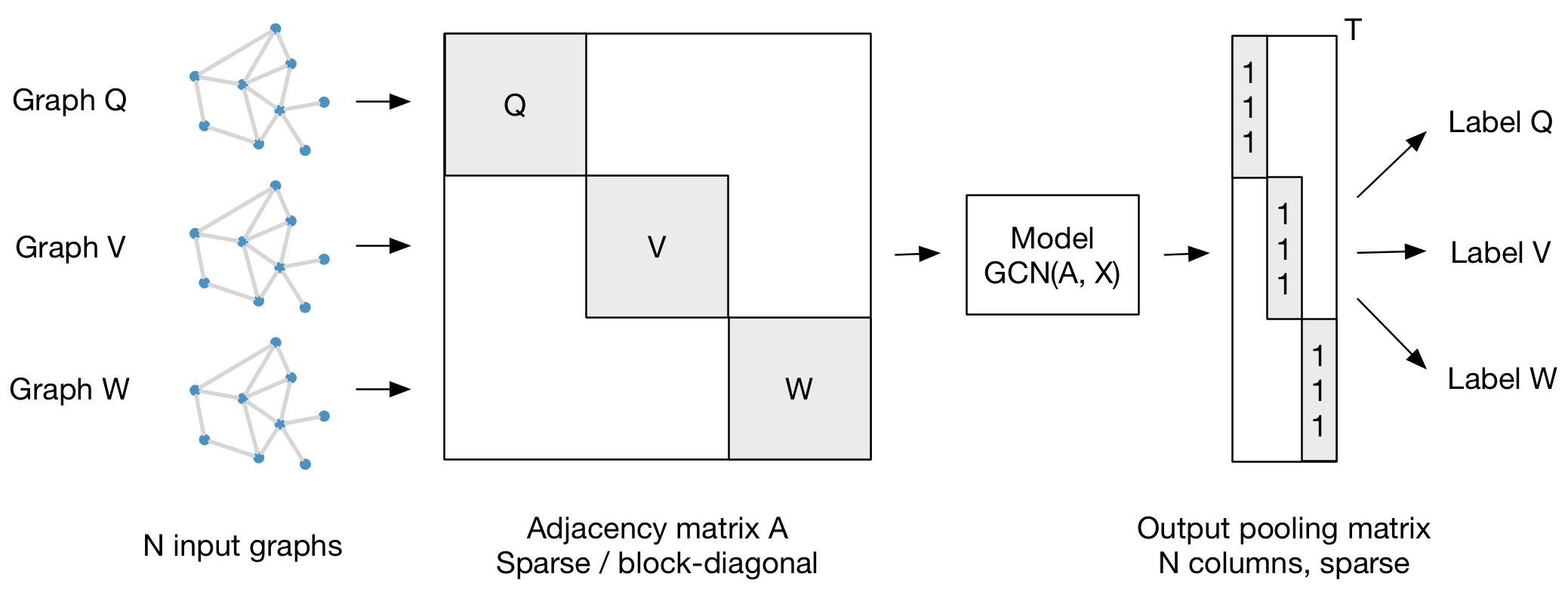
For batch-wise training over multiple graph instances (of potentially different size) with an adjacency matrix each, you can feed them in the form of a block-diagonal adjacency matrix (each block corresponds to one graph instance) to the model, as illustrated in the figure below:
Hi,
I have a followup question here. Though the code has a featureless option, I do not think it works directly when featureless is set to True. I just wanted to confirm that.
Thanks for your great code !
Hi, thanks for the catch. For the featureless mode, you have to set the input dimension of the first layer (only the first layer supports featureless) to be the number of nodes in the graph. I'll make sure to add a sentence or two about this in the documentation at some point.
Hi,
I want to use this gcn framework to do a semi-supervised regression mission (Given a graph(V, E) with feature matrix, the value(continuous) of some node is known while others are not, Target: predict the value of those unknown nodes). I directly change the loss function into RMSE, but it doesn't work well on validation dataset and test dataset. so,
-
is GCN suitable for regression?
-
how to change this framework to meet the requirements of regression?
Thanks you !
As far as I know regression should work. But you may want to look at the A-normalization. If I remember correctly, the normalization method proposed by Kipf & Welling does not lead to the rows of the normalized adjacency summing to 1.
It might be a good idea to turn the regression problem into a classification problem by bucketing the real-valued targets into several classes. This typically (empirically) works quite well in combination with a (softmax) cross-entropy loss. See, e.g., the WaveNet paper (https://arxiv.org/abs/1609.03499) for details.
It might also work to cast the regression problem as a classification problem by augmenting the input data similar to support vector regression. For example, regression from x to y, can be converted to a classification task with data ([x, y+r], 1) and ([x, y-r], -1). Thus no need to change the normalization term.
'r' is a manually set real-value margin, e.g., r = 0.8. The setting of 'r' typically depends on the range of y (to ensure most/all features are separable) and how much you'd like the samples to be separable. See here for details, where r is the epsilon in this case.
Hi, it is not clear to me how to give to the model a batch of graphs instead of only one. Could you please give other details? Thanks
Hi @tommy9114,
If I remember correctly (last time I touched it was in April) it is not possible to forward-pass multiple graphs at once, because you'd need a rank>2 sparse Tensor. Attempts were made to support rank>2 sparse Tensors with tensorflow (https://github.com/tensorflow/tensorflow/pull/9373) but it did not work out.
So if you want to pass multiple graphs at once, you should find out if any of the other frameworks (PyTorch?) support rank>2 sparse Tensors.
This is not quite correct, you can build a block-diagonal sparse matrix representing multiple graph instances at once. You further need to introduce a sparse gathering matrix that pools representations from their according graphs. All this can be done with regular sparse-dense matrix multiplications (of rank 2). Let me know if you need further details to implement this! On Mon 18. Dec 2017 at 17:43 michaelosthege [email protected] wrote:
Hi @tommy9114 https://github.com/tommy9114,
If I remember correctly (last time I touched it was in April) it is not possible to forward-pass multiple graphs at once, because you'd need a rank>2 sparse Tensor. Attempts were made to support rank>2 sparse Tensors with tensorflow (tensorflow/tensorflow#9373 https://github.com/tensorflow/tensorflow/pull/9373) but it did not work out.
So if you want to pass multiple graphs at once, you should find out if any of the other frameworks (PyTorch?) support rank>2 sparse Tensors.
— You are receiving this because you commented.
Reply to this email directly, view it on GitHub https://github.com/tkipf/gcn/issues/4#issuecomment-352483155, or mute the thread https://github.com/notifications/unsubscribe-auth/AHAcYO2TyQEbFrZWHiD5tBmer9iKcr7rks5tBpYWgaJpZM4LofoM .
yea in fact I previously read about this block-diagonal sparse matrix but actually I don't really know what is it and how to create it. I didn't find anything on google about how to build such data structure.
Oh, great thanks!
On Wed, Dec 20, 2017 at 9:53 AM, Thomas Kipf [email protected] wrote:
The following figure should hopefully clarify the idea: [image: graph_classification] https://user-images.githubusercontent.com/7347296/34198685-8c48e1d2-e56b-11e7-8ce6-64f1ba8a655c.png
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/tkipf/gcn/issues/4#issuecomment-353002759, or mute the thread https://github.com/notifications/unsubscribe-auth/AHMXGsWFLJMy4Fm2CH8jT2VJ1LZACLf-ks5tCMsDgaJpZM4LofoM .
-- Tommaso Pasini Ph.D. Student, Linguistic Computing Laboratory (LCL) Computer Science Department Sapienza University of Roma Room: F13 - via Regina Elena 295 palazzina F, 00161 Rome, Italy. Homepage: http://wwwusers.di.uniroma1.it/~pasini/ http://www.tommasopasini.altervista.org/
@tkipf Sorry to beat this into the ground. But, I'm interested in classifying about 2000 (i.e., N = 2000) 100x100 adjacency matrices (representing graphs) into two different classes -- i.e., whole-graph labelling. Going by your figure, this means that I ought to feed it a sparse 200,000 x 200,000 adjacency matrix into the model (i.e., each of the 2000 graphs represented along the diagonal). And the output pooling matrix is 200,000 x 2000, with the class labels along the diagonals (i.e., where the 1's are in your figure). Is this correct or am I completely missing something?
This is correct, but I would recommend training the model using smaller mini-batches of, say, 32 or 64 graphs each. Make sure the pooling matrix is also sparse and that you're using sparse-dense matrix multiplications wherever possible. This should run quite fast in practice. Good luck!
@mkeming Can I ask you if your graphs have the same node set (all the graphs have the same nodes) but different edges, or each graph has different nodes?
Best
On Thu, Jan 4, 2018 at 10:48 PM, Thomas Kipf [email protected] wrote:
This is correct, but I would recommend training the model using smaller mini-batches of, say, 32 or 64 graphs each. Make sure the pooling matrix is also sparse and that you're using sparse-dense matrix multiplications wherever possible. This should run quite fast in practice. Good luck!
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/tkipf/gcn/issues/4#issuecomment-355408464, or mute the thread https://github.com/notifications/unsubscribe-auth/AHMXGqMD-KiG0M_MMLft-v0dYDWx4SHwks5tHUc_gaJpZM4LofoM .
-- Tommaso Pasini Ph.D. Student, Linguistic Computing Laboratory (LCL) Computer Science Department Sapienza University of Roma Room: F13 - via Regina Elena 295 palazzina F, 00161 Rome, Italy. Homepage: http://wwwusers.di.uniroma1.it/~pasini/ http://www.tommasopasini.altervista.org/
i see, thanks
On Fri, Jan 5, 2018 at 11:19 AM, mleming [email protected] wrote:
@tommy9114 https://github.com/tommy9114 Same nodes and number of nodes, different edge values.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/tkipf/gcn/issues/4#issuecomment-355520472, or mute the thread https://github.com/notifications/unsubscribe-auth/AHMXGikQanQhd5tkg4tKbXs9FpPSJ9IGks5tHfc-gaJpZM4LofoM .
-- Tommaso Pasini Ph.D. Student, Linguistic Computing Laboratory (LCL) Computer Science Department Sapienza University of Roma Room: F13 - via Regina Elena 295 palazzina F, 00161 Rome, Italy. Homepage: http://wwwusers.di.uniroma1.it/~pasini/ http://www.tommasopasini.altervista.org/
Hi, does anyone successfully use this for graph classification? I implement a toy example on mnist using each pixel as node and its intensity as feature. However, the loss did not go down? I have modified the graphconv layer to dense matrix to work with parallel data loader. And the "ind" (size: N*batch, values are normalized to the number of nodes in each graph) is the pooling matrix as in the figure
class GCN(nn.Module):
def __init__(self, dropout):
super(GCN, self).__init__()
self.gc1 = GraphConv(1, 16)
self.gc2 = GraphConv(16, 32)
self.fc1 = nn.Linear(32, 500)
self.fc2 = nn.Linear(500, 10)
self.dropout = dropout
def forward(self, x, adj, ind):
# Conv layer
x = F.relu(self.gc1(x, adj))
x = F.relu(self.gc2(x, adj))
# Batching before fc layer
x = torch.mm(ind, x)
# FC layers
x = F.relu(self.fc1(x))
x = F.dropout(x, self.dropout, training=self.training)
x = self.fc2(x)
return x
I used this model quite some time ago for graph-level classification of the datasets provided in this paper: https://arxiv.org/abs/1605.05273 and got comparable (sometimes worse, sometimes better) results compared to their method. So maybe just have a look at these datasets. Shouldn't be too hard to load them in and run the model on these.
I edited your Keras Graph convolution code (train.py) and got something working, though it doesn't work incredibly well. I am still a little confused. The model in train.py (again, in the Keras version) takes both the adjacency matrix and the features of the graph. However, I wish to train on the adjacency matrices themselves, so the feature matrix would be unnecessary. And, for turning all of the node labels into a single graph label (for classification purposes), should we simply take the average of the node labels and go with the maximum? With the code as it is, I am still unsure how this would work well for whole-graph classification.
On 8 January 2018 at 09:04, Thomas Kipf [email protected] wrote:
I used this model quite some time ago for graph-level classification of the datasets provided in this paper: https://arxiv.org/abs/1605.05273 and got comparable (sometimes worse, sometimes better) results compared to their method. So maybe just have a look at these datasets. Shouldn't be too hard to load them in and run the model on these.
— You are receiving this because you commented. Reply to this email directly, view it on GitHub https://github.com/tkipf/gcn/issues/4#issuecomment-355912795, or mute the thread https://github.com/notifications/unsubscribe-auth/ACuN4w6F1ePthUKZCMC1sY9wQ2EMnIqAks5tIdoogaJpZM4LofoM .
In order to go from node-level representation to a graph-level representation you will indeed have to perform some kind of order-invariant pooling operation. Any popular pooling strategy typically works fine, in my experience: attentive pooling (https://arxiv.org/abs/1703.03130) often works better than max pooling which in turn often works better than average pooling. Make sure to allocate a somewhat large representation size for the pre-pooling layer (as you're going to average a lot of values). You can also pool the representation of every layer individually and concatenate or add/average the result (similar to https://arxiv.org/abs/1509.09292).
If you don't have any initial node features, simply use an identity matrix (assuming the identity and position of every node is the same across all the graph samples) as an initial feature matrix. This essentially provides a unique one-hot feature vector for every node in the graph. Only works if node identities stay the same across all graph samples. Otherwise you will have to come up with some sensible feature representation (e.g. node degree, betweenness centrality, etc.).
Sorry to keep asking question but I'm not sure if I got the right intuition: The architecture is able to learn feature vectors for nodes only if I pass always the same graph right? If my training set has different graphs (assume they have all the same dimension) but each row in the adj matrix may represents a different node then this architecture is not a good fit to learn the fetures of the nodes right? Thanks for your patient and kind answers
No worries! Your intuition is correct in the absence of any node features, i.e. if you pick an identity matrix for the initial feature matrix. If, however, you describe nodes by features (from a feature space which is shared by all nodes, i.e. two nodes could have the same features) the model can learn from different graphs (e.g. molecules), such as done here: https://arxiv.org/abs/1509.09292
Ok very interesting, so the features could also be derived from the graph itself (degree, centrality, number of triangles that contains it etc.) right?
On Fri, Jan 12, 2018 at 11:44 AM, Thomas Kipf [email protected] wrote:
No worries! Your intuition is correct in the absence of any node features, i.e. if you pick an identity matrix for the initial feature matrix. If, however, you describe nodes by features (from a feature space which is shared by all nodes, i.e. two nodes could have the same features) the model can learn from different graphs (e.g. molecules), such as done here: https://arxiv.org/abs/1509.09292
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/tkipf/gcn/issues/4#issuecomment-357205568, or mute the thread https://github.com/notifications/unsubscribe-auth/AHMXGoT0vVdcTWtnLdXTxdccKLPDM30Yks5tJzeqgaJpZM4LofoM .
-- Tommaso Pasini Ph.D. Student, Linguistic Computing Laboratory (LCL) Computer Science Department Sapienza University of Roma Room: F13 - via Regina Elena 295 palazzina F, 00161 Rome, Italy. Homepage: http://wwwusers.di.uniroma1.it/~pasini/ http://www.tommasopasini.altervista.org/
Yes, sure! https://arxiv.org/abs/1509.09292 uses node degree as an initial feature, for example.
Hello, @rushilanirudh @tkipf have you succeeded to update the code to deal with graph classification (rather than node classification. Each graph has only one class)?
Thank you
I do not intend to release this implementation as part of this repository. But it shouldn't be too difficult to implement this yourself :-)
Edit: PRs are welcome