How to handle items that can be purchased/used just once?
I'm training the model using purchase data for a certain period and validating it on what the same users purchased in the future.
How should I set up the model in case the items can be purchased just once? I don't want the model to recommend items present in the training set but only choose among the ones in the test set (which would be the ones available at that time in the future).
I was thinking of setting the candidates_dataset in the FactorizedTopK metric to use just the candidates from the test group but how would the model then be able to compute the loss on the training set?
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=candidates_dataset.batch(8192).map(self.candidate_model).cache()
))
The candidates_dataset is defined as
candidates = tf.data.Dataset.from_tensor_slices(
dict(train_df[candidate_features] \
.append(test_df[candidate_features]) \
.drop_duplicates())) \
.cache(tempfile.NamedTemporaryFile().name)
EDIT:
I think the solution might be defining different train_step and test_step using 2 different tasks that use different candidates. This is my attempt:
# using input embedding layer for candidate model
class RetrievalModel(tfrs.models.Model):
def __init__(self, layer_sizes, train_dataset, candidates_dataset,
max_tokens=100_000, embed_dim=32):
super().__init__()
self.embed_dim = embed_dim
self.query_model = QueryModel(layer_sizes, train_dataset, max_tokens=max_tokens, embed_dim=embed_dim)
self.candidate_model = CandidateModel(layer_sizes, self.query_model)
self.training_task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=train.batch(8192).map(self.candidate_model).cache()
))
self.test_task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=test.batch(8192).map(self.candidate_model).cache()
))
# def compute_loss(self, features, training=False):
# return self.task(self.query_model(features),
# self.candidate_model(features),
# compute_metrics=not training)
def train_step(self, features) -> tf.Tensor:
# Set up a gradient tape to record gradients.
with tf.GradientTape() as tape:
# Loss computation.
query_vectors = self.query_model(features)
candidate_vectors = self.candidate_model(features)
loss = self.training_task(query_vectors, candidate_vectors, compute_metrics=False)
# Handle regularization losses as well.
regularization_loss = sum(self.losses)
total_loss = loss + regularization_loss
gradients = tape.gradient(total_loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
metrics = {metric.name: metric.result() for metric in self.metrics}
metrics["loss"] = loss
metrics["regularization_loss"] = regularization_loss
metrics["total_loss"] = total_loss
return metrics
def test_step(self, features) -> tf.Tensor:
# Loss computation.
query_vectors = self.query_model(features)
candidate_vectors = self.candidate_model(features)
loss = self.test_task(query_vectors, candidate_vectors, compute_metrics=True)
# Handle regularization losses as well.
regularization_loss = sum(self.losses)
total_loss = loss + regularization_loss
metrics = {metric.name: metric.result() for metric in self.metrics}
metrics["loss"] = loss
metrics["regularization_loss"] = regularization_loss
metrics["total_loss"] = total_loss
return metrics
The simplest way would probably be to use the following in compute_loss:
if training:
loss = self.training_task(...)
else:
loss = self.test_task(...)
One thing I noticed in your code: you call .cache() after .map() in your task definitions. This is wrong: it means that after the first evaluation loop the candidate embeddings are cached, and the metrics do not reflect any improvements your model makes to its candidate representations later on. You need to reverse the order of these. If you saw this in a tutorial, let me know and I'll fix it.
Oh, good catch! Thanks! I'll keep the steps separate as this allows me to hide the accuracy metrics in the log when training.
The reason why I swapped map() with cache() is that it takes a super long time to perform the validation when I put cache before. Any ideas on how to speed things up?
This is the time with map after cache:
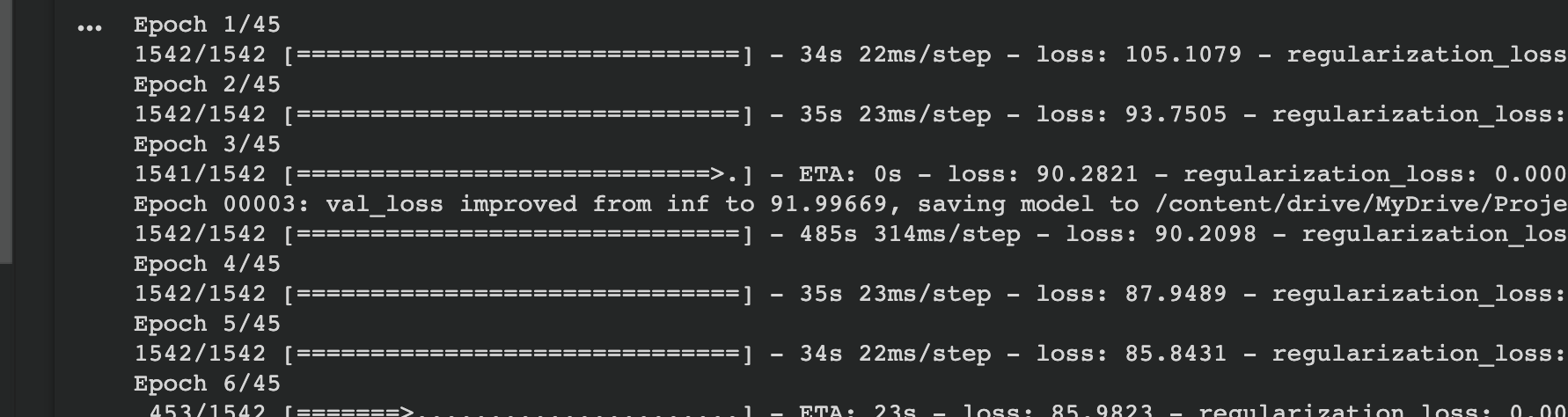
This is using map before cache:
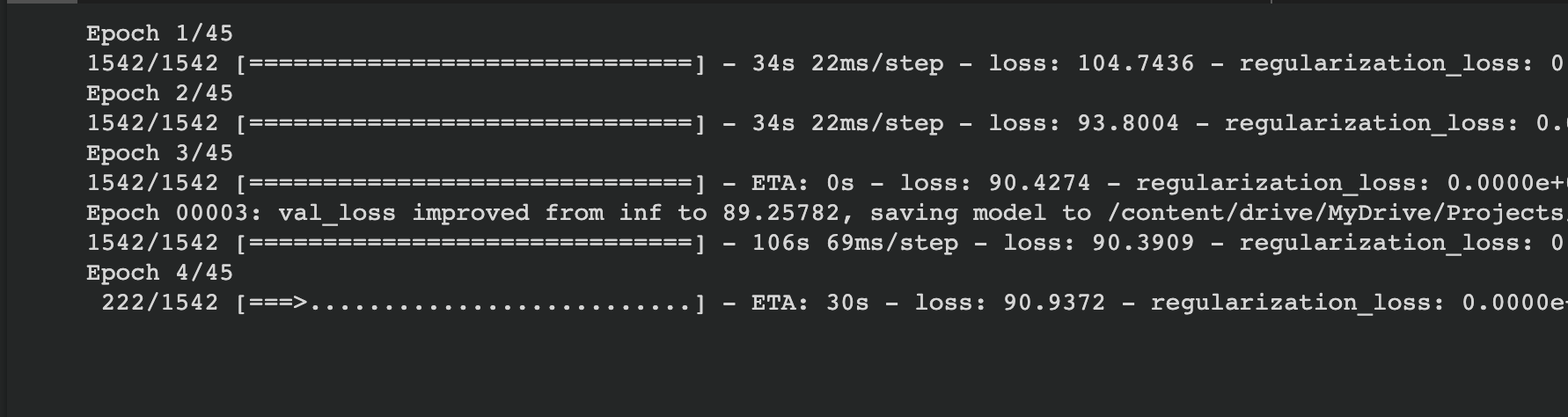
This is the time with map after cache changing the task batch size to 128:
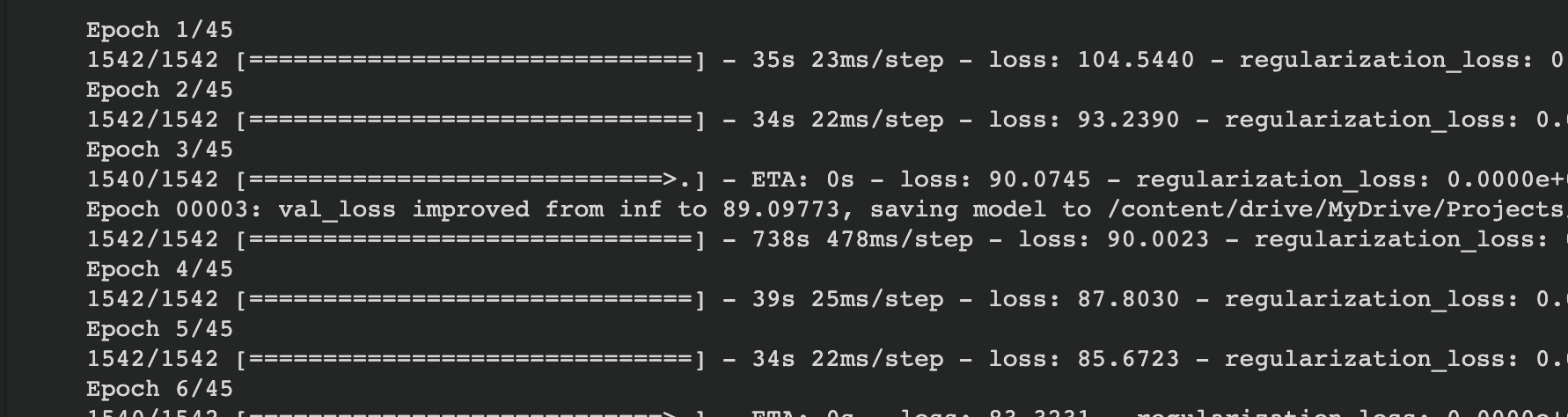
Yes, it is slow. That's because it needs to recompute all the candidate embeddings on the fly to give you accurate results if you intersperse training with evaluation. If you know you run it only once after you've finished training, it's perfectly fine to add .cache() after .map.
Have a look at the efficient serving tutorial for ideas how to make final post-training evaluation really fast.
But why is it faster even on the first validation? If it's caching the candidates after the 1st evaluation, shouldn't it be faster only starting from the 2nd validation? or am I missing something?
Also, is it expected that the batch size used for the candidates has such a big impact on the speed? The training batch size doesn't seem to impact training times as much.
If you're doing things on the fly, the evaluation metrics loop over the candidates dataset many, many times during a single evaluation run. That's why adding .cache speeds it up even in a single run; that's also why the batch size has such a huge impact.
It's possible that we may be able to optimize this, at the cost of higher memory usage.
To be clear, are you suggesting to increase the batch size of both the test and candidates datasets? As well as adding .cache before .map for candidates in the task?
- The
candidatesbatch size is the key part, but thetestbatch size might help as well. - You can add
cacheaftermaponce you know your model isn't changing any more. Don't do that if it's still changing.
Is it possible that both the val_accuracy and the val_loss go down together? How should I interpret this?
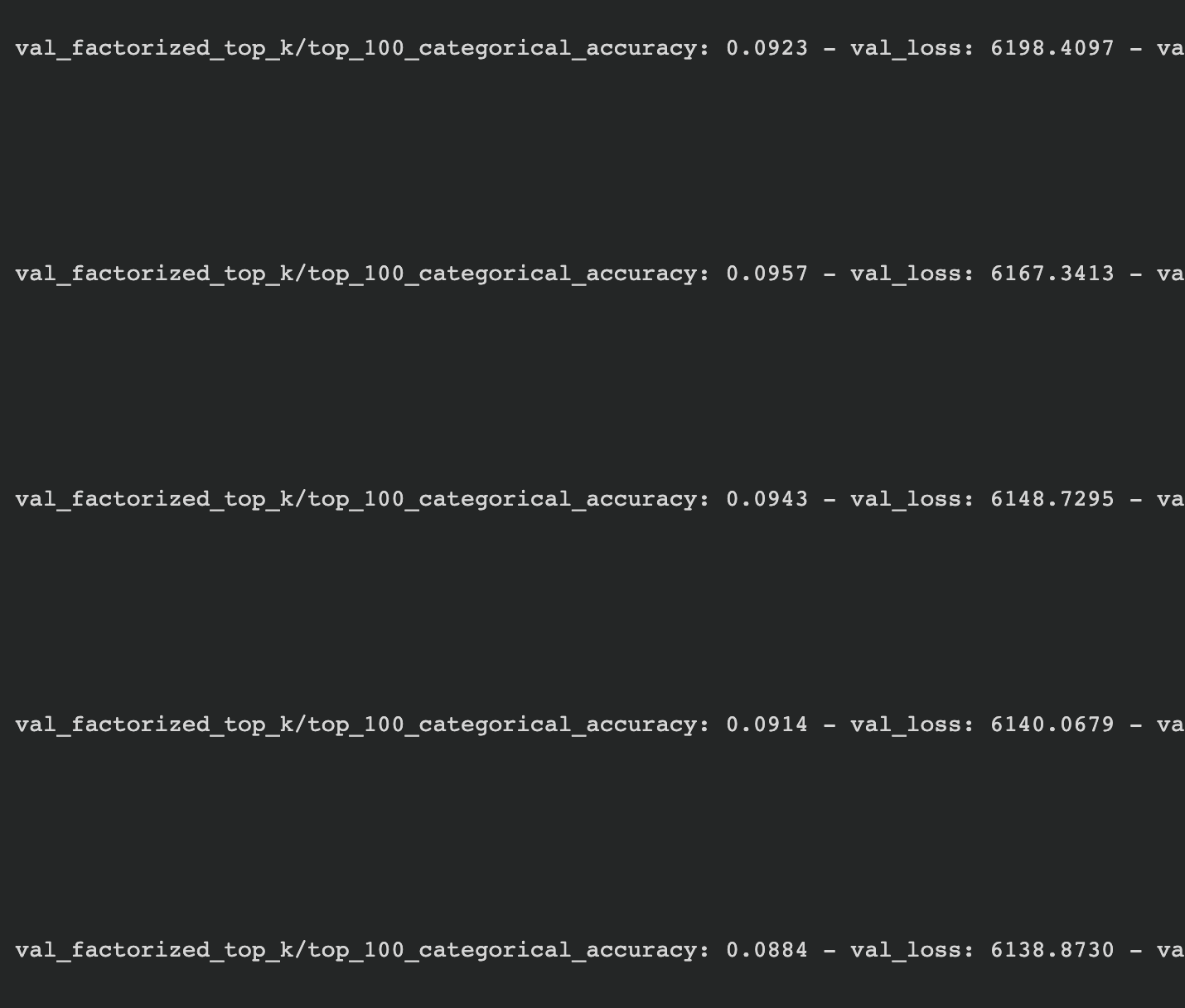
@italodamato
Accuracy is the metric and val_loss is the loss. The algo only optimize the loss, metric is whatever you define.