Optimize verbs with static memory registration and multi request buffers
The original implementation of verbs (which is called orig_verbs here) in networking cannot achieve good performance especially for large scale execution. To improve the performance of verbs, we optimized verbs (which is called mt-verbs) with static memory registration and multi request buffers:
-
Static memory registration. In order to transfer data with verbs, the memory should be registered with ibv_reg_mr which is time consuming. In orig_verbs, tensor is created by BFC allocator, then registered with ibv_reg_mr. Frequently memory registration largely reduces the performance of orig_verbs. In mt-verbs, we allocate a large memory space and then registered. Tensor is created in this memory space. This can significant reduce the overhead of memory registration.
-
Multi request buffers. In orig_verbs, grpc requests in a client are transferred through one request buffer. So a request can not be sent until the ack of pre-request is received, which limits the throughput of requests. In mt-verbs, each client has several request buffers, the requests can be sent and responded in parallel. Multi request buffers can improve the throughput of requests.
In order to evaluate the performance improvement of mt-verbs, dlrm model is chosen as the experimental model.
We measured three distributed scale: 50 worker and 5 ps; 100 worker and 10 ps; 200 worker and 10 ps. Each scale is measured several times. We deleted the fastest and the slowest values. The average of the remaining values is calculated as the final result of each scale. The results are list as follow.
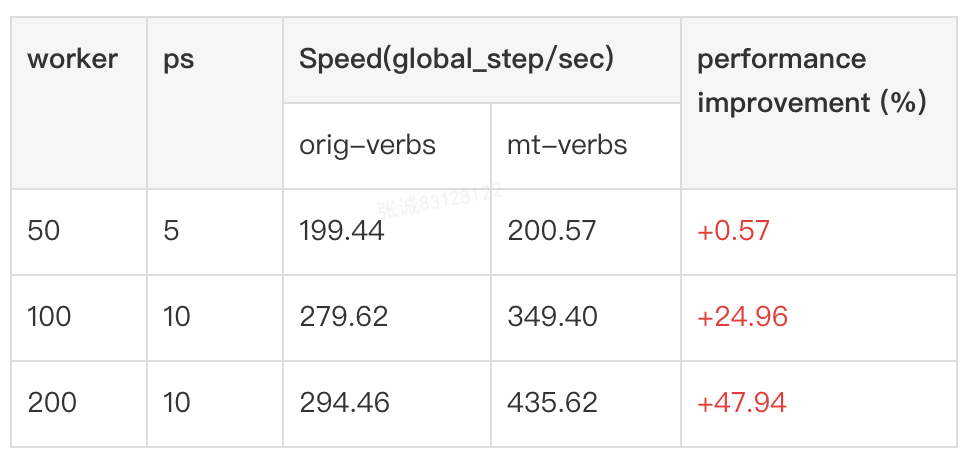
As above results shown, mt-verbs achieved similar performance as orig_verbs in small distributed scale (50 worker and 5 ps), and achieved 24.96% and 47.94% performance improvement respectively when using 100 worker and 200 worker.
We also compared the performance of mt-verbs and seastar with several business models. Mt-verbs can achieve 10%~60% performance improvement.
@byronyi I am happy to contribute my code. Could you please help review the pull request?
Thanks for your contribution! The performance figure looks promising.
It is interesting to see some additional improvement of the original BFC allocator design, as it already does proactive registration of large chunk of tensor memory. I am wondering if you have some figures to compare your static memory registration with the BFCAllocator alone, without enabling the multi-request buffer optimization.
The second design looks similar to FuseRecv (please correct me if I am wrong by the way) which is agnostic to specific networking protocols. An early implementation of FuseRecv is available at https://github.com/tensorflow/tensorflow/pull/27454, which is also specific to the transport though.
Nevertheless, glad to see someone that is still maintaining/improving this piece of code :)
@byronyi Thanks for your reply. I will try to compare the static memory registration with the BFCAllocator alone without enabling the multi-request buffer optimization later.