Suspected memory leak
环境: cpu 12核,20核心线程,64G内存,双固态硬盘(tdeinge存储于在挂载的第二块固态硬盘) (一台电脑部署应用程序,缓存,关系数据库,tdengine)
从3.0.1.6升级至3.0.1.7(数据从0重新插入,查询策略细微调整),出现一个现象:
-
3.0.1.6 taosd 内存8G左右。应用程序内存17G多。总体看上去能平稳。
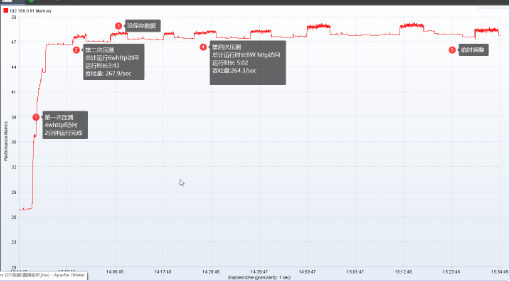
-
3.0.1.7 taosd 内存12G多。应用程序内存19G多,总体看上去是上升,且还在上升。
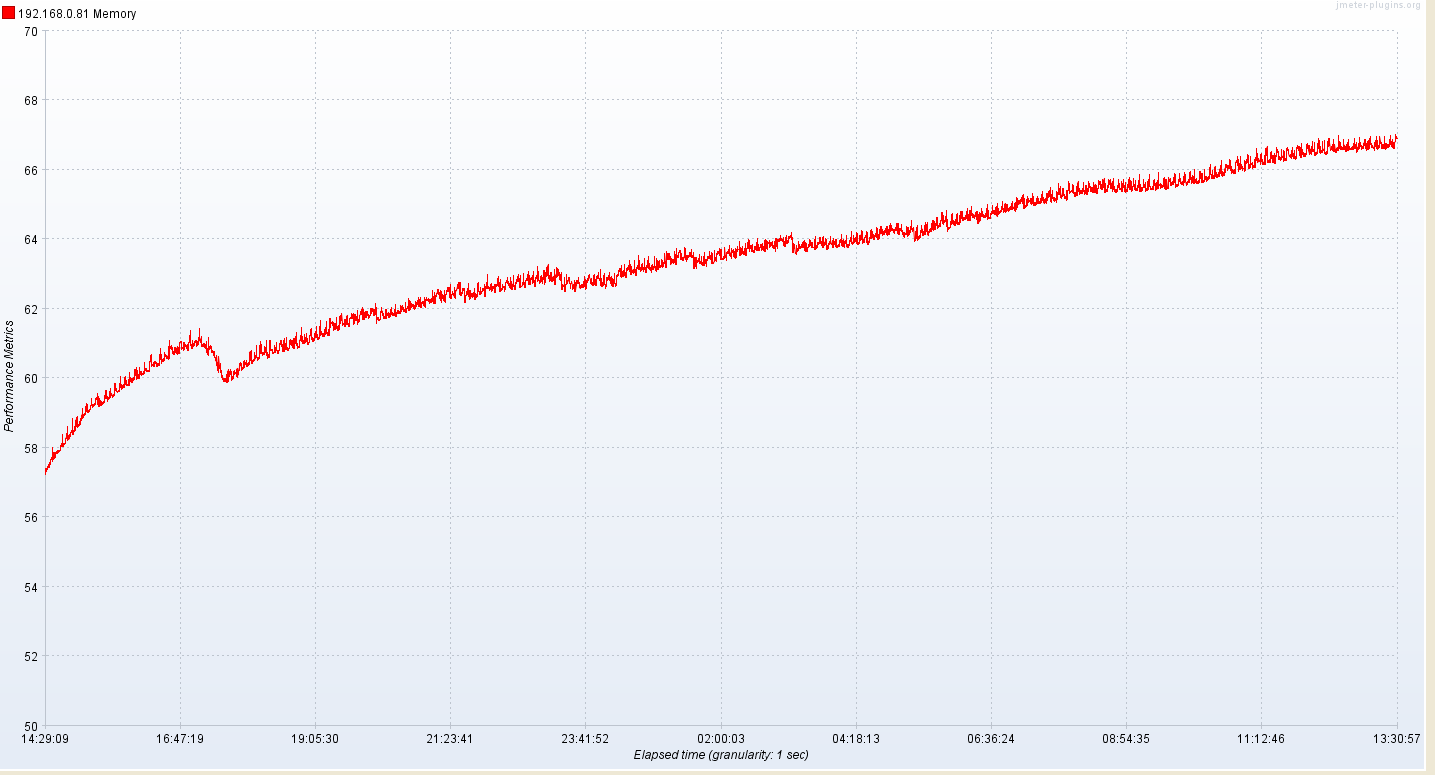
建库语句
create DATABASEdb BUFFER 1024 COMP 2 DURATION 1d WAL_FSYNC_PERIOD 3000 MAXROWS 8192 MINROWS 100 KEEP 366d,366d,366d PAGES 512 PAGESIZE 16 precision 'ms' REPLICA 1 STRICT 'off' WAL_LEVEL 1 VGROUPS 20 SINGLE_STABLE 0
超级表
CREATE STABLEevent_tdstore_status (_tsTIMESTAMP,dateTimeBIGINT,isHomeWifiBOOL,isChargingCompleteBOOL,isHistoricalDataBOOL,fallDownStatusINT,workModeINT,dataTypeVARCHAR(32),isBeaconBOOL,isChargingBOOL,isHomeBOOL,bleConnectedBOOL,batteryINT,isBLEBOOL,isSmartBOOL,isAGPSBOOL,createTimeBIGINT,isWIFIBOOL,isGPSBOOL,signalSizeINT,isRebootBOOL,statusCodeBIGINT,isGMSBOOL,isMotion BOOL) TAGS (productIdVARCHAR(64),deviceIdVARCHAR(64))
CREATE STABLEevent_tdstore_isactitem (_tsTIMESTAMP,datetimeBIGINT,createTimeBIGINT,active INT) TAGS (productIdVARCHAR(64),deviceIdVARCHAR(64))
CREATE STABLEevent_tdstore_gps (_tsTIMESTAMP,satellitesFLOAT,altitudeFLOAT,lngDOUBLE,createTimeBIGINT,precisionFLOAT,latDOUBLE,speedFLOAT,directionFLOAT,mileage FLOAT) TAGS (productIdVARCHAR(64),deviceIdVARCHAR(64))
插入:jdbc
数据时间
createTime时间:2022-11-17 18:27:08.360 至 2022-11-19 13:50:44.935
_ts时间:2022-01-01 04:12:30至2022-01-19 06:45:06
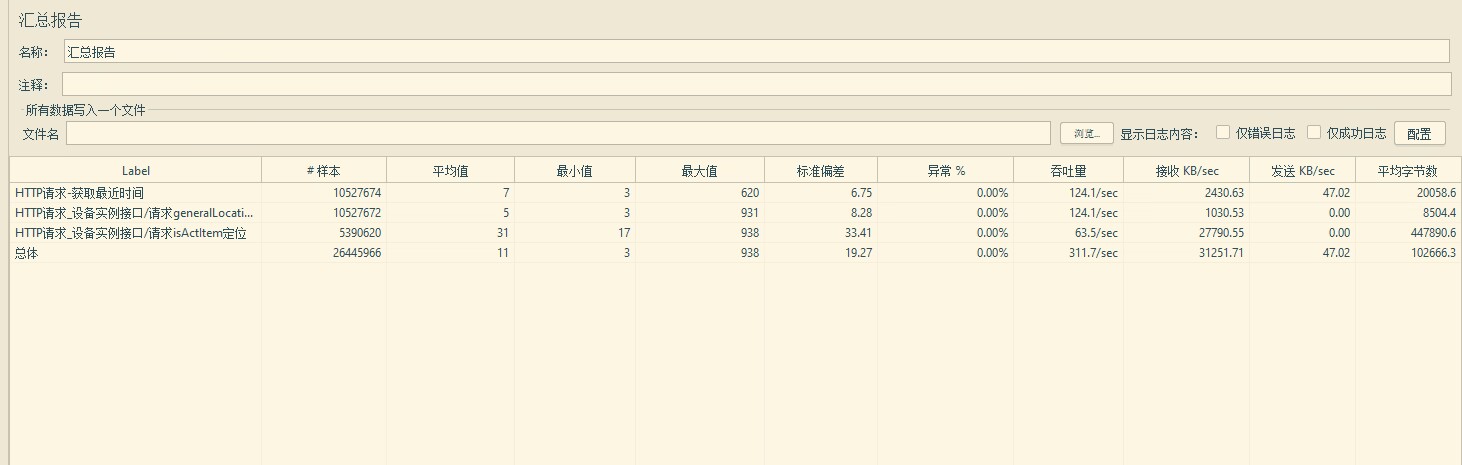
select count(_ts) from db.event_tdstore_isActItem; --103135079 select count(_ts) from db.event_tdstore_generallocation; --49508824 select count(_ts) from db.event_tdstore_gps; -- 49522963 select count(_ts) from db.event_tdstore_status; -- 49522965
查询:rest 2022-11-18 12:27:08.360 至 2022-11-19 13:50:44.935 查询一:
- 查询策略:
- 查询最新数据的_ts时间: select _ts from db.event_tdstore_gps_子表 order by _ts desc limit 1 offset 0
- 查询最新七天的数据top50: select * from db.event_tdstore_gps_子表 where _ts > 七天前的时间 order by _ts desc limit 50 offset 0
查询二:
- 查询策略 select * from db.event_tdstore_isactitem子表 order by _ts desc limit 2000 offset 0

从数据来说,肯定是线性增长的,而查询一般
- 查最新的n条
- 距今多少时间的数据。 随着时间的迁移,原来需要查的数据,已经不需要查了,但是这一部分的数据(可能是某种缓存)一直被驻留在内存中。只要有一个超时机制,释放,问题就解决了。
我也遇到了这个问题,内存持续上涨,而且夜间有一天突然打满。目前只是吧tdengine当做prometheus的外部读写,平时用量较小,日志量只有2个服务器的,也不大。


docker部署的3.0.1.2版本
从数据来说,肯定是线性增长的,而查询一般
- 查最新的n条
- 距今多少时间的数据。 随着时间的迁移,原来需要查的数据,已经不需要查了,但是这一部分的数据(可能是某种缓存)一直被驻留在内存中。只要有一个超时机制,释放,问题就解决了。
麻烦提供一下复现代码吧,我们跑一下
通过远程协助,发现日志级别,对性能影响太大了。
show dnodes; alter dnode 1 'tsdbdebugflag' '131'; alter dnode 1 'qdebugflag' '131';
需要重新压测,再反馈是否有问题
@yu285 感谢大佬鼎力相助
3.0.1.7升级到3.0.1.8(非docker),一启动查询压力测试,直接崩,暂时只能下面的信息。 java: /home/ubuntu/workroom/jenkins/3.0/TDinternal/community/source/libs/catalog/src/ctgRemote.c:31:ctgHandleBatchRsp: 假设 ‘taskNum == msgNum || 0 == msgNum’ 失败。 ^C 因为环境切来切去,没有生成core,然后重新启动后重新压力测试,没复现上面的异常了。
当前(2022-11-28 11:25)目前最大单表2.4w*2w大概4-5亿条记录,四张超级表(其他数据量减半),总数据量10亿+
内存还涨么
3.0.1.7测试到内存达到一定程度后,执行超级表count查询没响应,crash之后,升级到3.0.1.8。 目前只压力测试一天,表现如下:
38-40这个是我应用程序的问题,tdengine 3.0.1.8目前看,在趋向稳定,但还是微量上涨
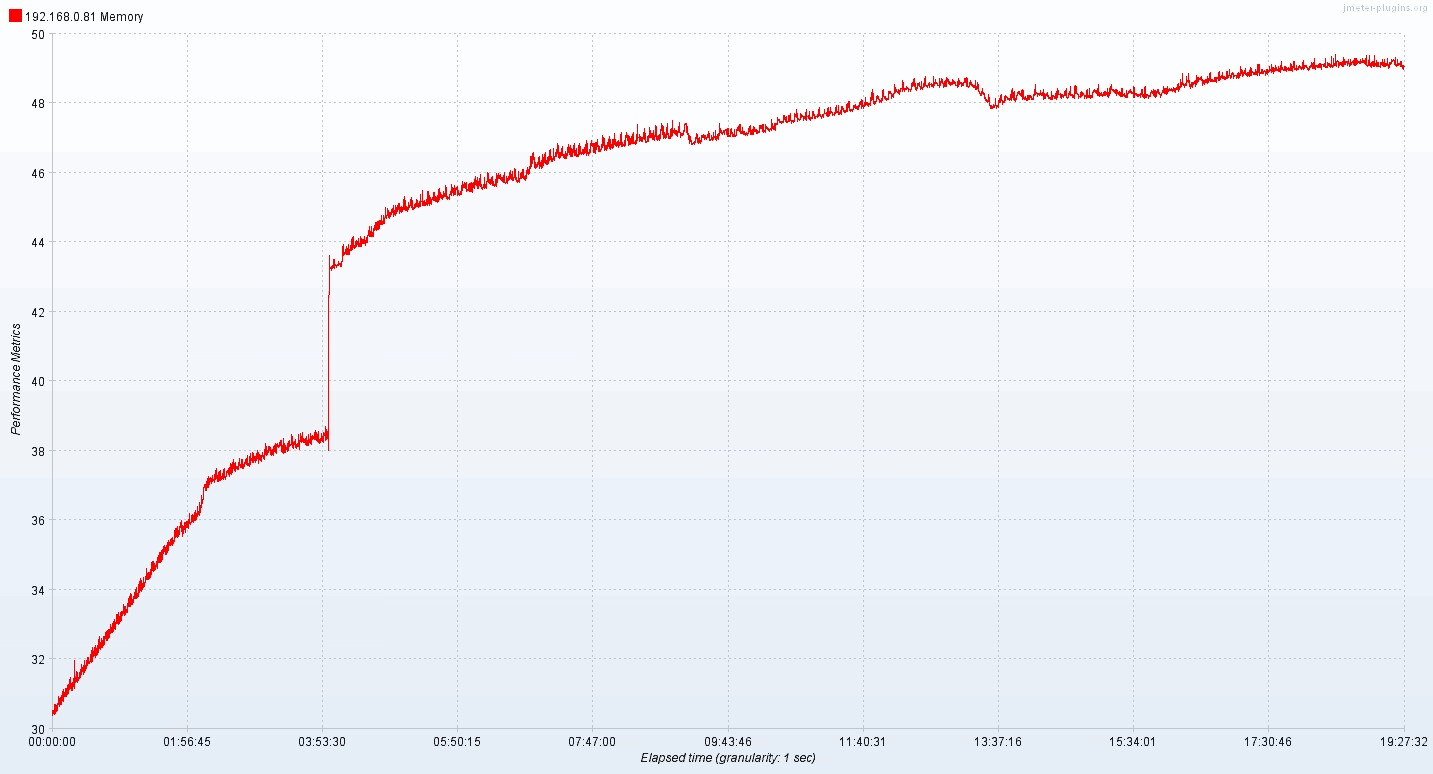
我这边是挂着就会涨,重新弄还是一样,,,官方可以试一下,找个服务器,用docker compose吧tdengine作为prometheus后端,监控采集本机运行两天就能复现
我这边是挂着就会涨,重新弄还是一样,,,官方可以试一下,找个服务器,用docker compose吧tdengine作为prometheus后端,监控采集本机运行两天就能复现
请问是无限制增长直到 OOM 么
我这边是挂着就会涨,重新弄还是一样,,,官方可以试一下,找个服务器,用docker compose吧tdengine作为prometheus后端,监控采集本机运行两天就能复现
请问是无限制增长直到 OOM 么
是的,抱歉邮件没看到,回复晚了
我这边是挂着就会涨,重新弄还是一样,,,官方可以试一下,找个服务器,用docker compose吧tdengine作为prometheus后端,监控采集本机运行两天就能复现
请问是无限制增长直到 OOM 么
是的,抱歉邮件没看到,回复晚了
请把你的电脑配置,版本,还有环境搭建脚本,发一下吧。
我这边今天是第五天了,还没OOM,不过内存还是继续涨
我这边是挂着就会涨,重新弄还是一样,,,官方可以试一下,找个服务器,用docker compose吧tdengine作为prometheus后端,监控采集本机运行两天就能复现
请问是无限制增长直到 OOM 么
是的,抱歉邮件没看到,回复晚了
请把你的电脑配置,版本,还有环境搭建脚本,发一下吧。
我这边今天是第五天了,还没OOM,不过内存还是继续涨
OOM几乎是必然的,我内存比较少,可能饱的快。但是一直涨早晚OOM,我觉得这个跟配置没关系
服务器是8c16g,还部署了好多其他项目
docker-compose配置可以参考一下,用的夜莺的部署demo改的
version: "3.7"
services:
prometheus:
image: prom/prometheus
container_name: prometheus
restart: unless-stopped
volumes:
- ./nightingale/prometc:/etc/prometheus:ro
- prometheus-data:/prometheus
ports:
- "39090:9090"
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--web.console.libraries=/usr/share/prometheus/console_libraries"
- "--web.console.templates=/usr/share/prometheus/consoles"
- "--enable-feature=remote-write-receiver"
- "--query.lookback-delta=2m"
networks:
- nightingale
grafana:
image: grafana/grafana:9.0.9
container_name: grafana
restart: unless-stopped
ports:
- 33000:3000
environment:
TZ: Asia/Shanghai
volumes:
- /etc/timezone:/etc/timezone:ro
- /etc/localtime:/etc/localtime:ro
- ./nightingale/grafana/provisioning:/etc/grafana/provisioning
- ./nightingale/grafana/dashboards:/var/lib/grafana/dashboards
- ./nightingale/grafana/config/grafana.ini:/etc/grafana/grafana.ini
- grafana-data:/var/lib/grafana
networks:
- nightingale
nwebapi:
image: flashcatcloud/nightingale:latest
container_name: nwebapi
restart: unless-stopped
environment:
TZ: Asia/Shanghai
GIN_MODE: release
WAIT_HOSTS: postgres:5432, redis:6379
volumes:
- /etc/timezone:/etc/timezone:ro
- /etc/localtime:/etc/localtime:ro
- ./nightingale/n9eetc:/app/etc:ro
ports:
- "18000:18000"
command: >
sh -c "/wait && /app/n9e webapi"
networks:
- nightingale
nserver:
image: flashcatcloud/nightingale:latest
container_name: nserver
restart: unless-stopped
environment:
GIN_MODE: release
TZ: Asia/Shanghai
WAIT_HOSTS: postgres:5432, redis:6379
volumes:
- /etc/timezone:/etc/timezone:ro
- /etc/localtime:/etc/localtime:ro
- ./nightingale/n9eetc:/app/etc:ro
ports:
- "19000:19000"
command: >
sh -c "/wait && /app/n9e server"
networks:
- nightingale
redis:
image: ${REDIS_IMAGE}
restart: unless-stopped
volumes:
- /etc/timezone:/etc/timezone:ro
- /etc/localtime:/etc/localtime:ro
- redis-data:/data
# ports:
# - "6379:6379"
environment:
- TZ=Asia/Shanghai
- ALLOW_EMPTY_PASSWORD=yes
- REDIS_DISABLE_COMMANDS=FLUSHDB,FLUSHALL
networks:
- nightingale
tdengine:
image: tdengine/tdengine:3.0.1.2
restart: unless-stopped
environment:
TAOS_FQDN: "tdengine"
ports:
- 36030:6030
- 36041:6041
- 36043:6043
volumes:
- tdengine-data:/var/lib/taos/
- tdengine-log:/var/log/taos/
networks:
db-net:
volumes:
tdengine-data:
driver: local
tdengine-log:
driver: local
redis-data:
driver: local
prometheus-data:
driver: local
grafana-data:
driver: local
3.0.1.8,压力测试13天,我们模拟了130天的数据,随着时间的增长,内存在涨,查询性能在下降(查询固定时间周期)。
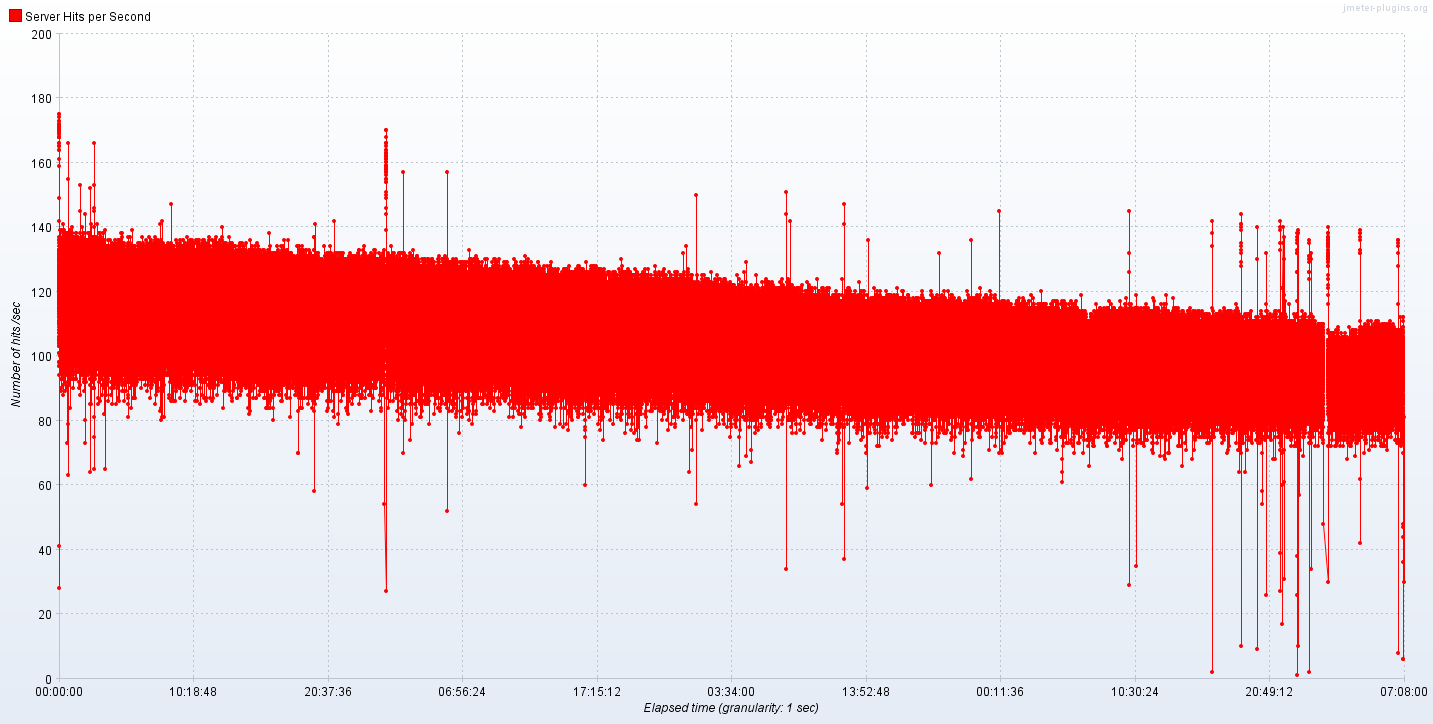 若从我们的时序数据库的设计来讲,总体查询性能应该持平才对。
若从我们的时序数据库的设计来讲,总体查询性能应该持平才对。
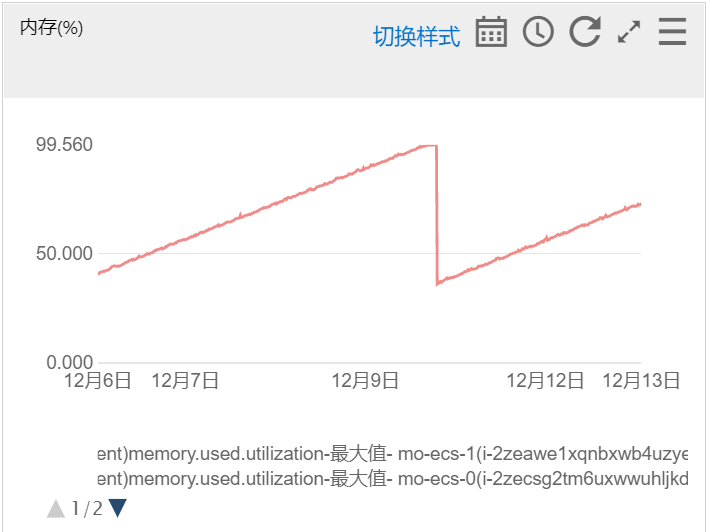 监控服务没有管,最近两周跑固定业务不动服务器,很规律的内存增长并oom
监控服务没有管,最近两周跑固定业务不动服务器,很规律的内存增长并oom
这个有办法记录日志或怎么排查一下吗,因为这个服务是测试用的,量也不大,想试用一下tdengine,然后这个内存涨的确实有点快
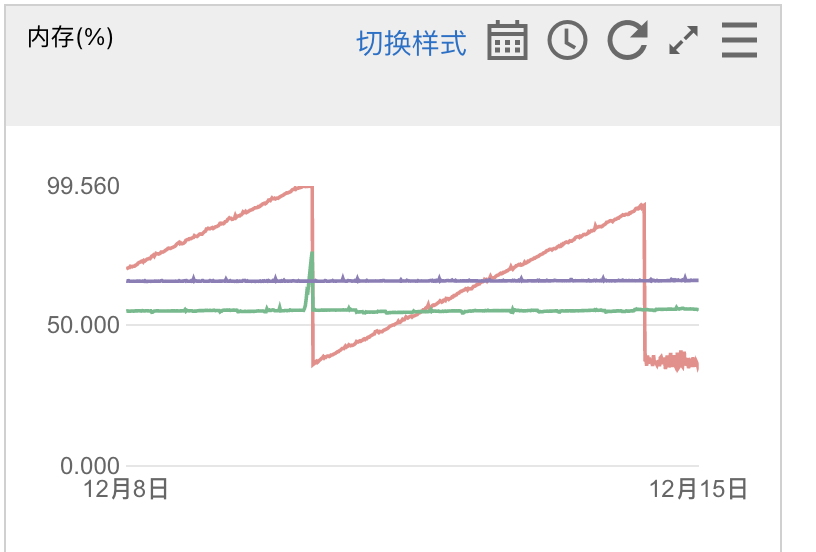
@zeje @yu285 看了发布,更新到3.0.2.0内存泄漏问题应该是已经解决了,目前非常稳定,也很快~
没跑几天就说稳定……
我这边还在跑,还是内存持续少量上涨。从几百兆涨到6G,今天突然停电又重新测试。

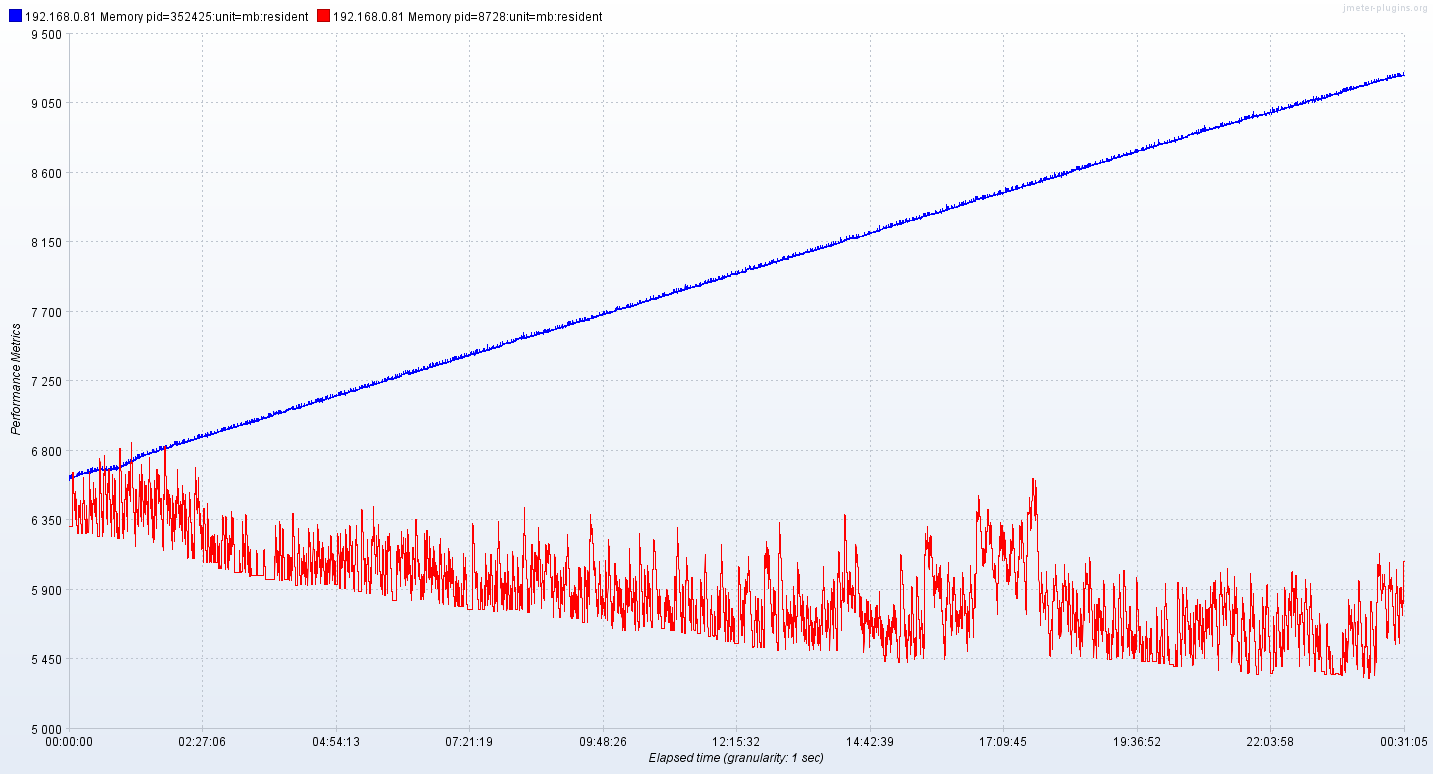

原结论:tdengine 3.0.2.0,同时插入+查询 压力测试,内存泄露。 升级为:tdengine 3.0.2.2版本之后:
- 纯压数据插入:已平稳运行22小时,可认为纯插入数据无内存泄露。(下图蓝色线条)
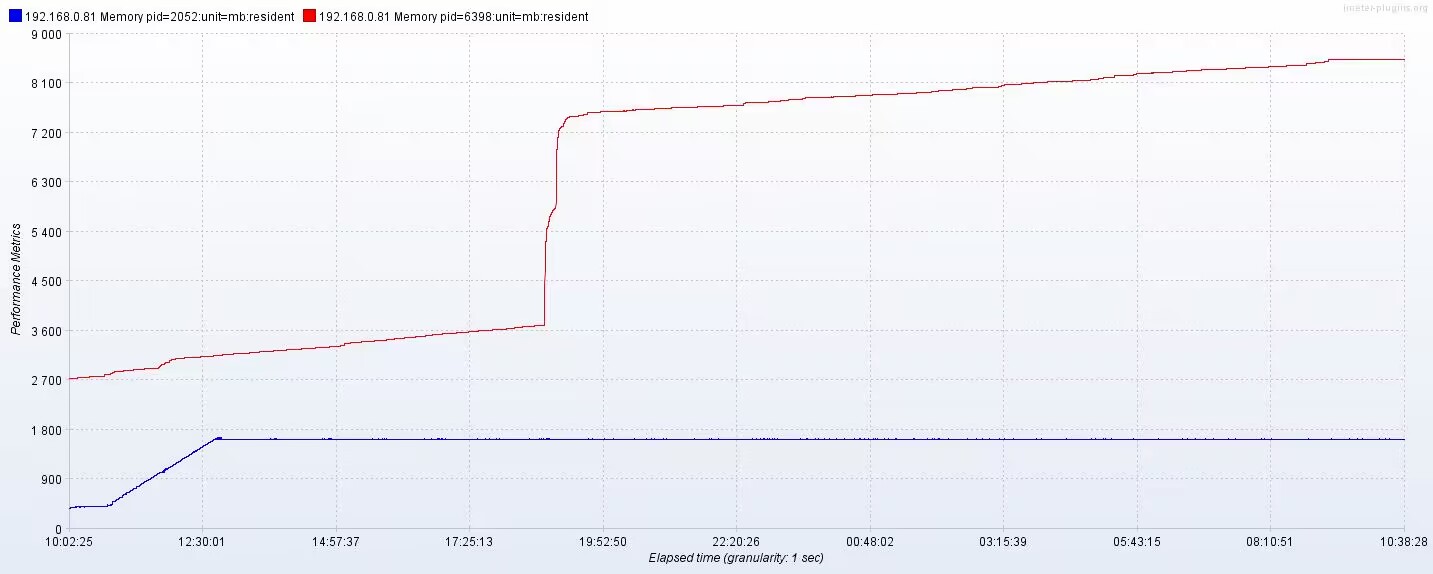

- 待测试: 2.1. 纯压查询:数据无新增,所有查询应该都是老的数据,待确认是否有内存泄露。 2.2. 压插入+查询:原来有泄露的是3.0.2.0版本,待确认下3.0.2.2是否已解决此场景下的内存泄露问题。
3.0.2.2版本,模拟2w设备,插入使用jdbc,查询使用restful 建库参数:CACHEMODEL 'last_row' 超级整表数据量约10亿,count超级表一次49秒(速度慢原因不明)
压力测试过程如下:
taod重启
纯压插入(jdbc方式):
压测22小时,内存达到稳定状态,约1700M,见上图
纯压查询(restful):
jemeter传入设备随机编号:${__Random(888888100000001,888888100020000,)}
模拟 device 2w,300qps左右,一直执行类似如下语句(rest),内存泄露。 select count(ts) total from loctube.event" + productId + "" + event + "" + deviceId; select LAST_ROW(*) from db.tb_{deviceId} order by _ts desc
纯压查询count:
String sql = "select count(ts) total from loctube.event" + productId + "" + event + "" + deviceId; return tDengineOperations.query(sql);
count跑了2小时,内存涨了100M
11:22:08 3517.101 13:41:28 3610.558
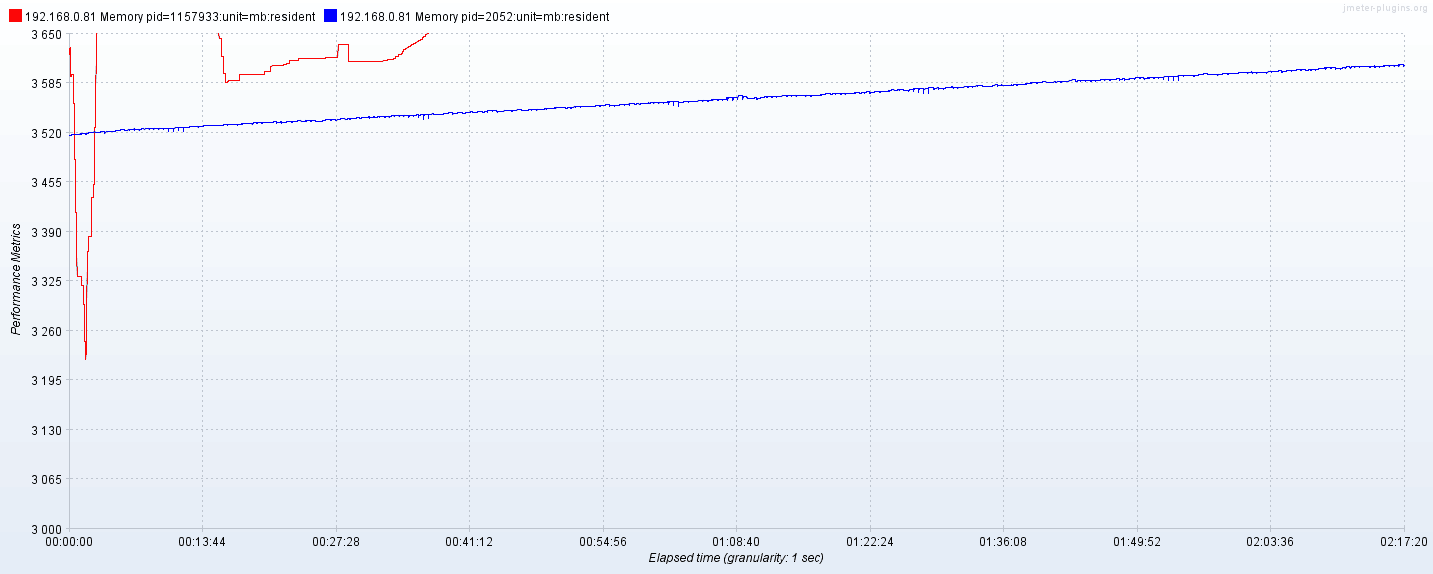
纯压查询last_row order by _ts desc:
(qps未记录)
String sql = "select LAST_ROW(*) from loctube.event_" + productId + "" + event + "" + deviceId + " order by _ts desc"; return tDengineOperations.query(sql);
last_row跑了40分钟,内存涨约100M

纯压查询last_row:
(最后qps达到了2875)
String sql = "select LAST_ROW(*) from loctube.event_" + productId + "" + event + "" + deviceId; return tDengineOperations.query(sql);

将查询方式由restful切换为jdbc,压测上述的纯count,问题依旧。可见问题在taosd端,而不在taosadapter端。
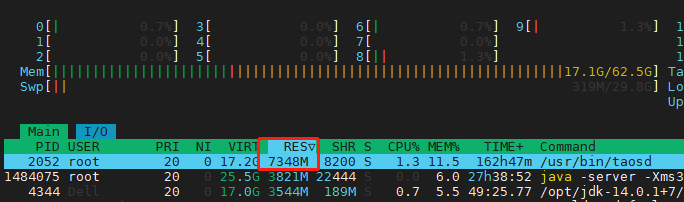
@zeje 问题收到,我们看一下
陈玉反馈LAST_ROW内存泄露在3.0.2.3版本可能已解决,然而更新到3.0.2.3,压力测试 String sql = "select LAST_ROW(*) from loctube.event_" + productId + "" + event + "" + deviceId; return tDengineOperations.query(sql); 问题依旧。
麻烦执行一下:
ldd taosd然后把结果贴出来。
[root@tdengine-server ~]# cd /usr/local/taos [root@tdengine-server taos]# ls bin cfg data driver examples include log script [root@tdengine-server taos]# cd bin [root@tdengine-server bin]# ls get_client.sh remove_client.sh set_core.sh startPre.sh taos taosadapter taosBenchmark taosd taosd-dump-cfg.gdb udfd [root@tdengine-server bin]# ldd taosd linux-vdso.so.1 (0x00007ffebabf7000) libm.so.6 => /lib64/libm.so.6 (0x00007f5fd6e8d000) libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f5fd6c6d000) libdl.so.2 => /lib64/libdl.so.2 (0x00007f5fd6a69000) librt.so.1 => /lib64/librt.so.1 (0x00007f5fd6861000) libc.so.6 => /lib64/libc.so.6 (0x00007f5fd649c000) /lib64/ld-linux-x86-64.so.2 (0x00007f5fd720f000)