Failed to validate connection com.taosdata.jdbc.TSDBConnection@4a9ebf77 (TDengine ERROR (8000000b): Unable to establish connection). Possibly consider using a shorter maxLifetime value.
环境 CentOS 8.0,64g内存,20核心线程
tdengine数据库 CREATE DATABASE IF NOT EXISTS db vgroups 20 DURATION 1d KEEP 380d, 380d, 380d
模拟设备上报数据频率一致,程序一样
模拟:18w设备,influxdb 1.8.10,单机,http可正常插入,设备一次上报插入10条记录, 内存占用25G。
模拟:10w设备,tdengine 3.0.15,20个vgroup,单机,设备一次上报插入3条记录, jdbc可正常插入(hikari maximum-pool-size512内存占用1.5G) restful不可正常插入
对比写入,18w 乘以 10 vs 10 乘以 3 = 6:1
此情况下, 一. influxdb进行查询,内存更是猛涨。 二. tdengine进行查询时,报如下几种错误,并且严重影响写入:
- java.sql.SQLException: TDengine ERROR (8000000b): Unable to establish connection
- HikariPool-1 - Failed to validate connection com.taosdata.jdbc.TSDBConnection@2c0d22a9 (TDengine ERROR (8000000b): Unable to establish connection). Possibly consider using a shorter maxLifetime value.
问题一: 之前看到的资料是tdengine写入性能 > influxdb,从我这边的环境及配置看,远不如influxdb,请问,如何调整配置,写入才能提高性能?
问题二: 一个简单的查询,影响了插入。l hikari maximum-pool-size 原来是36,后面因为报错,调整成了512(是不是太大了?),实际报错的时候,pool的使用数量<200。如何调整配置,才能提高?
如下是目前tdengine jdbc的压测下入情况:
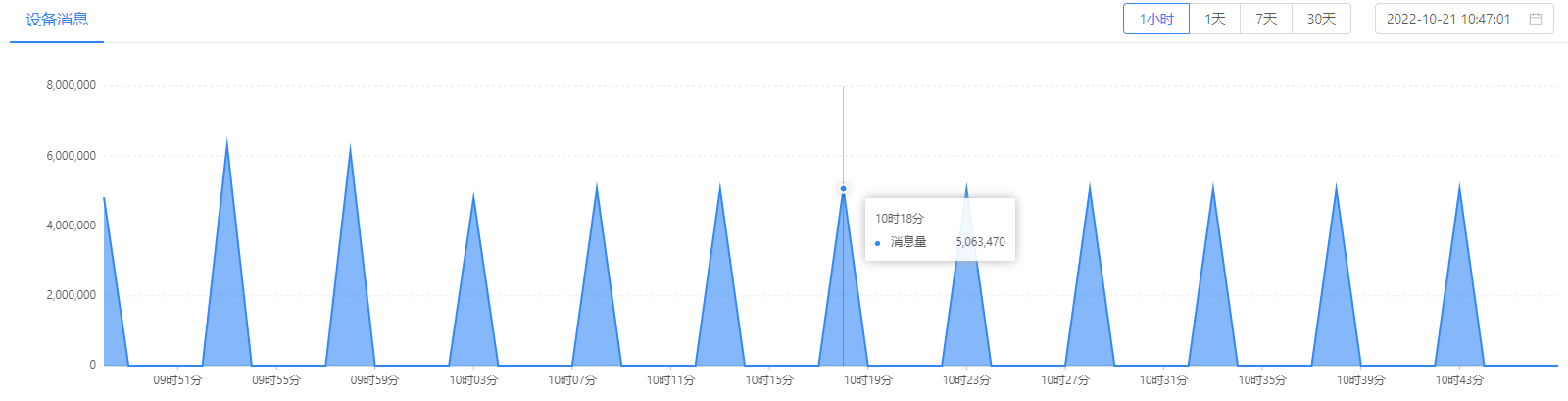
其中,非常明显的性能下降是,我有一个字段,原来是binary(1024),因为长度不够,我加到了2048,这个时候,并发插入直线下降。而实际上的数据量是没有变化的。模拟的设备量由15w,下降到10w都还有问题。
还有,就是后面使用了三个数据节点作为集群。vnode由原来的20变40,插入性能依旧没有得到提高。
三个数据节点的集群,网络情况,同一台电脑上部署的3个docker实例。客户端电脑与测试主机是在同一个子网下
按照上面的压力测试,压了一个晚上之后,有上亿条数据,之后产生了问题。(此刻已没有在写入数据了)
如下语句: A: select count(1) from db.event_tdengine_status_999999100000001 B: select count(1) from db..event_tdengine_status_999999100000002 C: select * from db.event_tdengine_status_999999100000010 limit 1
使用restful查询,每个表平均有600多条数据,反复重试,有时候正常,有时候异常 SQL 错误 [8984]: ERROR (2318): Read timed out SQL 错误 [8984]: ERROR (2318): Connect to taosnode1:6041 [taosnode1/192.168.0.81] failed: Connection refused: no further information
使用jdbc驱动查询,A语句执行正常,B语句执行异常, 10/22 13:32:39.402000 00011444 RPC ERROR TSC conn 0000012EC91224A0 failed to connect server:connection timed out 10/22 13:32:40.450000 00011444 RPC ERROR TSC conn 0000012EC91224A0 failed to connect server:connection timed out 10/22 13:32:40.451000 00012456 TSC ERROR 0x65 rsp msg:vnode-batch-meta-rsp, code:Unable to establish connection rspLen:0, elapsed time:3105 ms, reqId:0x1d19342dca62ba5f 10/22 13:32:40.453000 00012456 QRY ERROR Got error rsp, error:Unable to establish connection 10/22 13:32:40.455000 00017864 QRY ERROR PARSER: 0x1d19342dca62ba5f catalogGetTableMeta error, code:Unable to establish connection, dbName:tb, tbName:event_tdengine_status_999999100000002 10/22 13:32:40.457000 00017864 TSC ERROR 0x65 error occurs, code:Fail to get table info, return to user app, reqId:0x1d19342dca62ba5f 10/22 13:32:40.458000 00015960 JNI ERROR jobj:0000001D7C4FE970, conn:0000012ECAAD5990, code:Fail to get table info, msg:Fail to get table info, error: Unable to establish connection 10/22 13:32:40.459000 00015960 TSC select duration 3113000us: syntax:0us, ctg:3109000us, semantic:1000us, planner:-1666416760456000us, exec:0us, reqId:0x1d19342dca62ba5f
还有一堆timedout的日志 10/22 13:35:44.166000 00005212 RPC ERROR TSC conn 0000028E01507940 failed to connect server:connection timed out 10/22 13:35:45.202000 00005212 RPC ERROR TSC conn 0000028E015073D0 failed to connect server:connection timed out

使用dbweaver,查询出来,id,deviceStaus均为乱码,正常情况下deviceStatus是json字符串 (高频率的偶发)
show create stable db.event_tdengine_status 乱码(高频率的偶发)

补充一点, 原来录入数据是当前时间,后来因为模拟程序是一天压测10天的数据量,后面调整成了 补录一年的数据,也就是开始的时间是一年前。 打从改成了补录方式后,这个性能感觉也是直线下滑,是不是这个缘故呢?