[SCIM] Requests performance
Hello,
I am debugging a performance issue I have with PATCH requests to a group with many members.
I noticed that the generated SQL for a GET of a group is the following:
SELECT t.id, t.created, t.display_name, t.external_id, t.last_modified, t.resource_type, t.tenant_id, t.version, t0.id, t0.attribute_id, t0.full_path, t0.namespace, t0.parent_attribute_id, t0.representation_id, t0.resource_type, t0.schema_attribute_id, t0.tenant_id, t0.value_binary, t0.value_boolean, t0.value_date_time, t0.value_decimal, t0.value_integer, t0.value_reference, t0.value_string, t0.id0, t0.canonical_values, t0.case_exact, t0.default_value_int, t0.default_value_string, t0.description, t0.full_path0, t0.multi_valued, t0.mutability, t0.name, t0.parent_id, t0.reference_types, t0.required, t0.returned, t0.schema_id, t0.type, t0.uniqueness, t1.representations_id, t1.schemas_id, t1.id, t1.description, t1.is_root_schema, t1.name, t1.resource_type, t1.id0, t1.canonical_values, t1.case_exact, t1.default_value_int, t1.default_value_string, t1.description0, t1.full_path, t1.multi_valued, t1.mutability, t1.name0, t1.parent_id, t1.reference_types, t1.required, t1.returned, t1.schema_id, t1.type, t1.uniqueness
FROM (
SELECT s.id, s.created, s.display_name, s.external_id, s.last_modified, s.resource_type, s.tenant_id, s.version
FROM scim_representation_lst AS s
WHERE ((s.id = '0ffb4b21-fe3f-4126-b0f7-e96d9e8a308c') AND (s.resource_type = 'Group'))
LIMIT 1
) AS t
LEFT JOIN (
SELECT s0.id, s0.attribute_id, s0.full_path, s0.namespace, s0.parent_attribute_id, s0.representation_id, s0.resource_type, s0.schema_attribute_id, s0.tenant_id, s0.value_binary, s0.value_boolean, s0.value_date_time, s0.value_decimal, s0.value_integer, s0.value_reference, s0.value_string, s1.id AS id0, s1.canonical_values, s1.case_exact, s1.default_value_int, s1.default_value_string, s1.description, s1.full_path AS full_path0, s1.multi_valued, s1.mutability, s1.name, s1.parent_id, s1.reference_types, s1.required, s1.returned, s1.schema_id, s1.type, s1.uniqueness
FROM scim_representation_attribute_lst AS s0
LEFT JOIN scim_schema_attribute AS s1 ON s0.schema_attribute_id = s1.id
) AS t0 ON t.id = t0.representation_id
LEFT JOIN (
SELECT s2.representations_id, s2.schemas_id, s3.id, s3.description, s3.is_root_schema, s3.name, s3.resource_type, s4.id AS id0, s4.canonical_values, s4.case_exact, s4.default_value_int, s4.default_value_string, s4.description AS description0, s4.full_path, s4.multi_valued, s4.mutability, s4.name AS name0, s4.parent_id, s4.reference_types, s4.required, s4.returned, s4.schema_id, s4.type, s4.uniqueness
FROM scim_representation_scim_schema AS s2
INNER JOIN scim_schema_lst AS s3 ON s2.schemas_id = s3.id
LEFT JOIN scim_schema_attribute AS s4 ON s3.id = s4.schema_id
) AS t1 ON t.id = t1.representations_id
ORDER BY t.id, t0.id, t0.id0, t1.representations_id, t1.schemas_id, t1.id, t1.id0
It looks to me that too much data is being queried, and that the query creates unnecessary row duplication. When a group contains 1000+ members the data retrieved is huge.
I think that we should consider a different way of getting all the relevant data.
What do you think?
Kind regards, Dan
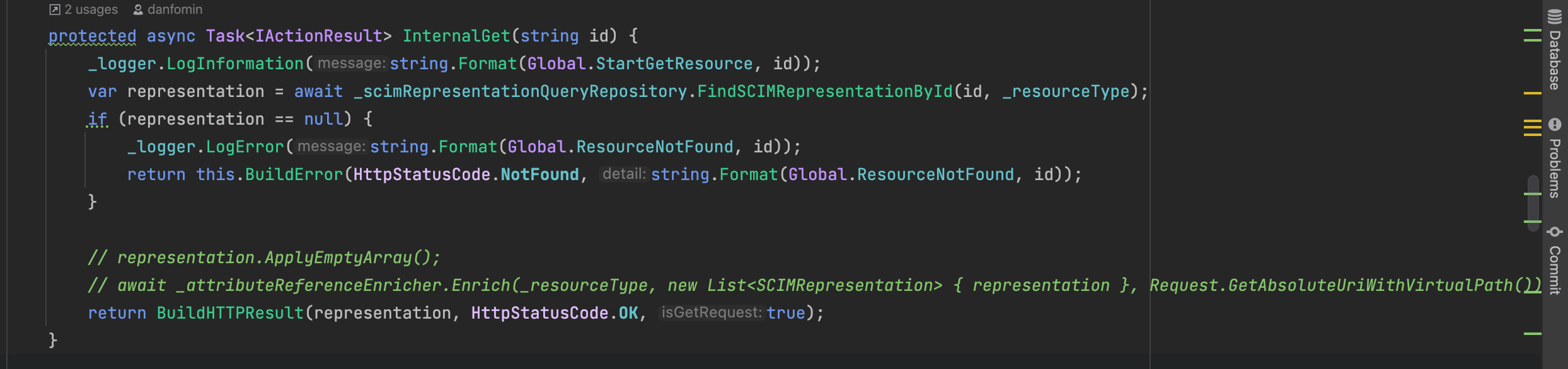
I tried to debug the code and I noticed that commenting out these lines for the GET of a user lowered a request by half (from 5 sec to 2.5 sec).
Do you think that this implementation can be optimized?
Hello Dan,
The query performance can easily be improved by doing the following modifications.
- Update your configuration file like this :
services.AddScimStoreEF(options =>
{
options.UseSqlServer(Configuration.GetConnectionString("db"), o =>
{
o.MigrationsAssembly(migrationsAssembly);
o.UseQuerySplittingBehavior(QuerySplittingBehavior.SplitQuery);
});
});
- Update the ConnectionString to enable MultipleActiveResultSets (MARS)
Data Source=MSSQL; Initial Catalog=AdventureWorks; Integrated Security=SSPI; MultipleActiveResultSets=True
MARS ( MultipleActiveResultSets) have been enabled in all the startup projects AND the interface IDistributedLock has been removed from the solution because it causes performance issue and it is not needed.
The changes have been committed into the branch release/v2.0.14.
Can-you please check if you still have performance issue with the latest changes present in the branch ? On my local machine it takes 83MS to fetch one group with 300 members.
KR,
Sid
The Split Query helped my performance issues.
I still experience slowness but it is better this way :)
Do you think that the ApplyEmptyArray and Enrich methods can be optimized?