1901100277-自学训练营学习19群-每课 学习总结
学员信息
- 学号:<1901100277>
- 学习内容:<Python 编写一个简单的支持 加、减、乘、除功能 的计算器,支持输入数据,并输出计算结果>
- 学习用时:<6小时>
学习笔记
拿到作业有点蒙圈,感觉好复杂,因为我们用的计算器有好多功能,无从下手 . 看了一下大家的作业,大概感觉到 先要对问题拆分 1/ 用Python 2/ 要支持输入 https://blog.csdn.net/qq_36016407/article/details/77856729 3/ 要支出输出
输出好理解 ,用 print 函数就好了
要想 让人 输入,怎么做???
试试强大的 Google


搜索后
get 到Python里有一个函数 支持接收 外部输入数据

重点研究了下 input函数 ,问题就解决了一大半 <收获总结> 在整个过程中,一定要注意 数据类型, 用 input函数 接受输入的任何内容都是 字符串类型, 如果有需要进行其他运算 ,一定要注意先 转换数据类型. 当然这只是一个很简单的计算器,仅仅实现了 两个数的加减乘除,但是作为新手来讲,能够主动分析出最小模块,也是一种能力,没必要一下做到完美.后面慢慢完善就好了 <遇到的难点与问题(是否解决)>看到别的同学 有用 定义函数 的方式,来写代码,我试了,总是报错,所以用了自己最熟悉的 定义变量,来进行运算.也是可以的. 接下来要好好学习 def 定义函数的相关内容给了
学员信息
-
学号:<1901100277>
-
学习内容:<用不同语句 打印指定格式的的九九乘法表>
-
学习用时:<8小时>
学习笔记
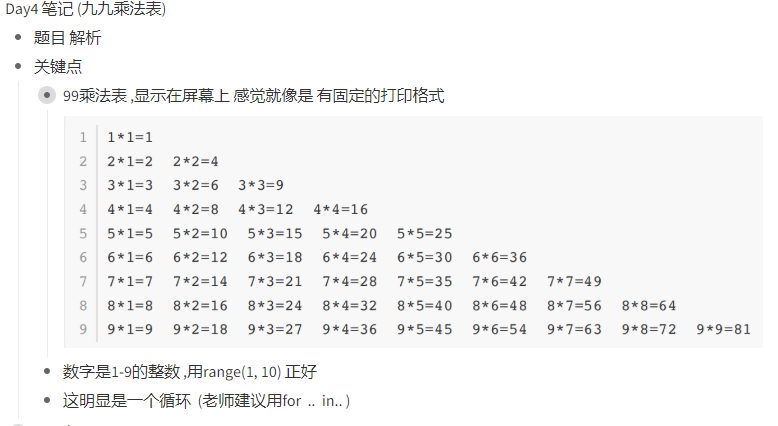
拿到今天的作业 ,没有上次那么无从下手了,观察乘法表,打印的格式好像是有一定的规律,Google,找了一下发现了 这个
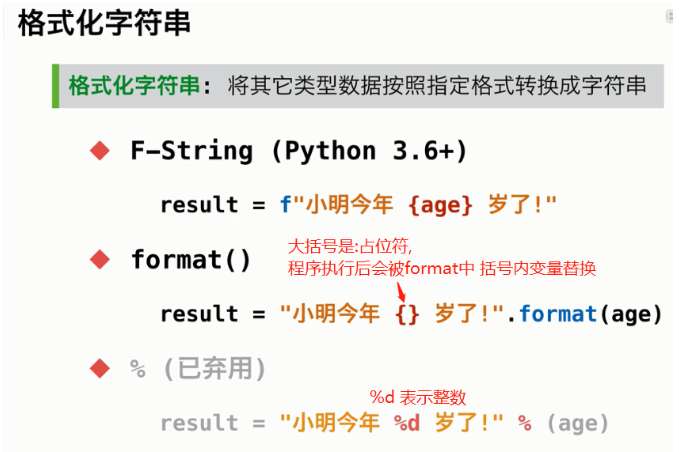 顺腾摸瓜,发现了rang() 函数, 它非常方便控制循环的次数,但是和while 函数又有不同 ;
顺腾摸瓜,发现了rang() 函数, 它非常方便控制循环的次数,但是和while 函数又有不同 ;
之前只知道 print()函数 可以打印,却不知道print( )里面竟然可以放多个参数,而且默认是在打印的最后添加了一个换行 ;

通过这个作业学习了转义字符的实战用法
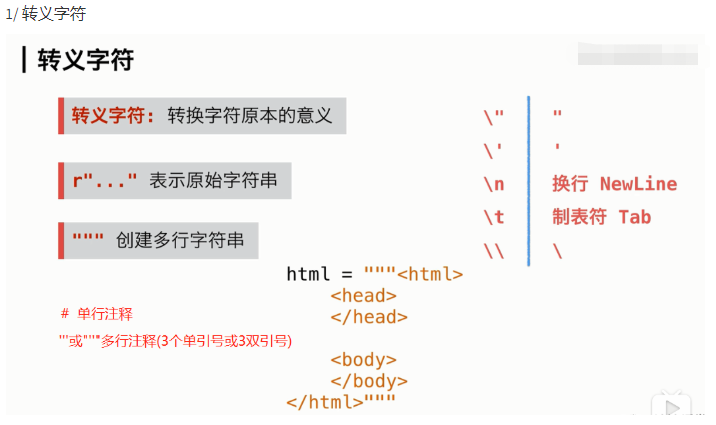
<收获总结> 心底慢慢的感觉 :程序其实没有这么复杂,一步步的学习拆分他的功能,组装在一起,调试就好了,对于没有见过的函数,最好的学习方法就是看案例,看他的实战用法,看文档,看多了 分析多了,也就会了. <遇到的难点与问题(是否解决)> while 语句 break continue 还是不会用,尽管也可以用while 写出 作业,要加强学习 @liujiayi0042
学员信息
- 学号:<1901100277>
- 学习内容:<字符串的基本处理/统计字符串样本中英文单词出现的次数/ 数组操作,进制转换 >
- 学习用时:<14小时>
学习笔记 Day 5 自我感觉从这一课开始,才算真的进入到了编程的世界。 课后给一段文字,竟然也可以教计算机根据我们的要求处理一些文字,很开心学完后收货慢慢的成就感。 当然 今天的作业相比之前涵盖了更多知识。 个人感觉 尤为重要的知识点是 for...in ... 可以自动对 字符串/列表里面的元素进行遍历(遍历的意思就是 将元素 一个一个取出来进行操作,超级方便) 字符串 替换/分割split/拼接join/大小写翻转swapcase/排序sort/sorted 这些内容Google一下,不难理解.
很早之前就读笑来老师的书,得知早在很多年前 就运用统计考试中最常出现的 单词词频 这一技能,写了一本书,大卖成为了长销书.有幸今天能有知道了原理. 统计词频这个题目中 最重要的也是for...in...语句 ,对每个单词进行遍历,在此基础上 对遍历的每一个单词count 计数+1,并同时把单词和计数 添加到一个初始化的字典里,最后从大到小排序
起初,在进行遍历单词的时候,起初 我并没有想到,其实是可以先set() 对单词进行去重 减少遍历次数(比如:文章里 共有100个单词, 有20个单词出现了两次,甚至3次,那么我们就可以 set()后,再去遍历整篇文章,来统计单词出现的频率)
在进行排序的过程中 使用sorted函数 遇到一个问题 : 就是 lambda函数 ,经过查询它就是一个匿名函数

#################################################
# sorted 函数 排序:https://docs.python.org/zh-cn/3/howto/sorting.html#sortinghowto
# 敲重点: lambda 是一个匿名函数,https://www.bilibili.com/video/av40153579/?p=13
# key=lambda 元素: 元素[字段索引] https://blog.csdn.net/u010758410/article/details/79737498
# 0:代表按照第一个字段索引,1:代表按照第二个字段索引,比如下面的1 就是按照 单词的频率
进行索引排序
#################################################
字符串相关知识:


字典相关知识:



<收获总结> 尽管工作之余,需要抽出不少的时间,甚至会研究到很晚,但是看着代码一步步的完善,一切是过往云烟,感觉很棒! <遇到的难点与问题(是否解决)> 已经解决
学员信息
- 学号:<1901100277>
- 学习内容:<封装统计英文单词词频的函数/封装统计中文汉字字频的函数>
- 学习用时:<4小时> Day 6
学习笔记
作为一个门外汉,之前也会偶尔听说 封装,感觉很高大上的一个词, 没有学习课程前并没有研究过它 究竟是什么? ---其实就是将写好的代码 ,定义成一个函数,后期便可以写出函数名 直接调用,根本不用管函数体里面到底是什么,例如 print( )函数 难点就在于 如何判断 给到的字符串 是否是文字 (汉字和中文是不一样的,包括标点符号也不一样) if "\u4e00" <= wen_zi <= "\u9fff" #unicode 中 中文字符的 范围
ps:我发现 new = list (text) #汉字 字符串可以直接用 list 转化为 单个文字的列表 但是会出现一个问题 :如果字符串里有 英文单词,list 会把单词中的每个字母 拆分为 单个元素,不完善. 在这道题中 ,list 只适合纯中文字符串
也许有更好的方法 判断 字符串是中文 还是英文,后面慢慢更新